训练文字类微调模型
目前流行的文字类生成模型,例如 LLama,ChatGLM,即使是相对较小的尺寸也难以在消费级GPU上进行全参数微调,因此,在这里,我们不讨论如何对文字类微调模型进行全参数微调,只关注如何进行轻量化微调
训练工具 🔧
图像类生成模型领域,往往都是基于Stable Diffusion,通常具有相同的网络结构,而不同的文字类生成模型可能源于不同的基础模型,我们这里只使用 text-generation-webui 的训练微调模型功能来说明如何训练微调模型
text-generation-webui 目前对流行的模型的支持度如下, (对于其他目前 text-generation-webui 不支持的模型,可以使用对应模型的微调方法进行训练,产物需要为 peft 的 lora 模型格式)
| 基础模型 | 微调 |
|---|---|
| LLaMA | 支持 |
| OPT | 支持 |
| GPT-J | 支持 |
| GPT-NeoX | 支持 |
| RWKV | 不支持 |
| ChatGLM | 不支持,请使用第三方工具 |
模型选择
LLaMA 系列的模型目前是最主流的模型
但是因为在训练时采用的语料主要是英文,对于其他语言的支持较弱
对于英文类语言,建议使用 WizardLM-7B-Uncensored 或 vicuna-7b-1.1 在自己的数据上进行进一步微调
对于中文类语言,建议使用 Linly-Chinese-LLaMA-7b-hf 进行微调
对于韩语,建议使用 kollama-7b
| 模型 | 语言 |
|---|---|
| WizardLM-7B-Uncensored | English |
| vicuna-7b-1.1 | English |
| Linly-Chinese-LLaMA-7b-hf | 中文 |
| kollama-7b | 한국어 |
数据准备 📚
对于文字类微调模型来说,存在两种数据大类
| 数据 | 格式 | 使用场景 | 什么时候使用 | 缺点 | 作用 |
|---|---|---|---|---|---|
| 纯文字语料数据 | 不需要有特别的数据格式,将所有的文字放到一个或多个txt文件 | 文本补齐 | 例如,你希望微调一个编故事的模型,输入故事的开头,让模型补充后续的内容 | 进行微调后,可能失去原有的能力 | |
| 指令数据 | 需要有特殊的数据格式 | 对话,命令 | 让模型更好的理解人类的意图 |
指令数据是通过调整数据集,让模型更好的理解人类的意图
不管是指令数据还是纯文字语料,都是文本补齐类任务的。
对于指令数据,可以将其看作模型的输入为带有指令的文字,要求模型补全剩余的文字
text-generation-webui 目前对这两种形式的语料都支持 lora 微调
训练微调模型
按照 text-generation-webui 的安装指南,安装text-generation-webui
启动 text-generation-webui,从顶部的选项卡选择,进入到 Model 选项卡
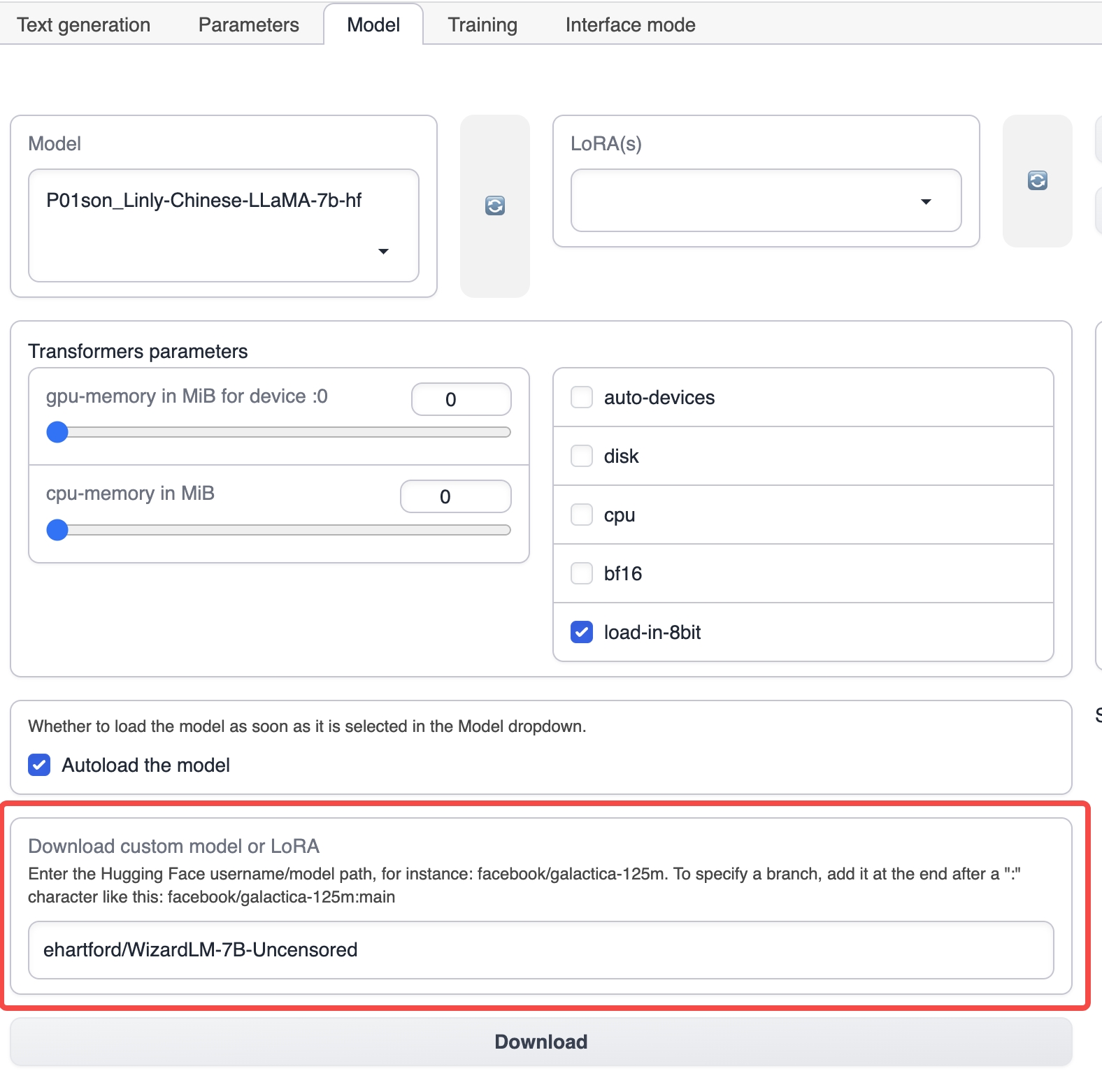
在 Model 选项卡下,输入对应的基础模型的名字,例如 ehartford/WizardLM-7B-Uncensored,然后点击下载,下载基础模型(也可以手动下载模型,然后放到 text-generation-webui 安装目录下的 models 目录)
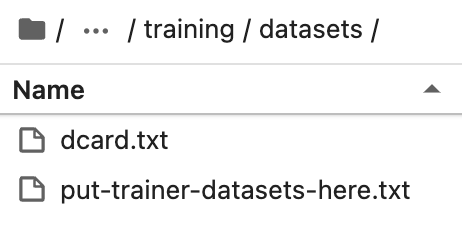
将准备好的数据集放到 text-generation-webui 安装目录下的 training/datasets 里
切换到 text-generation-webui 的 training 选项卡,选择你准备好的数据
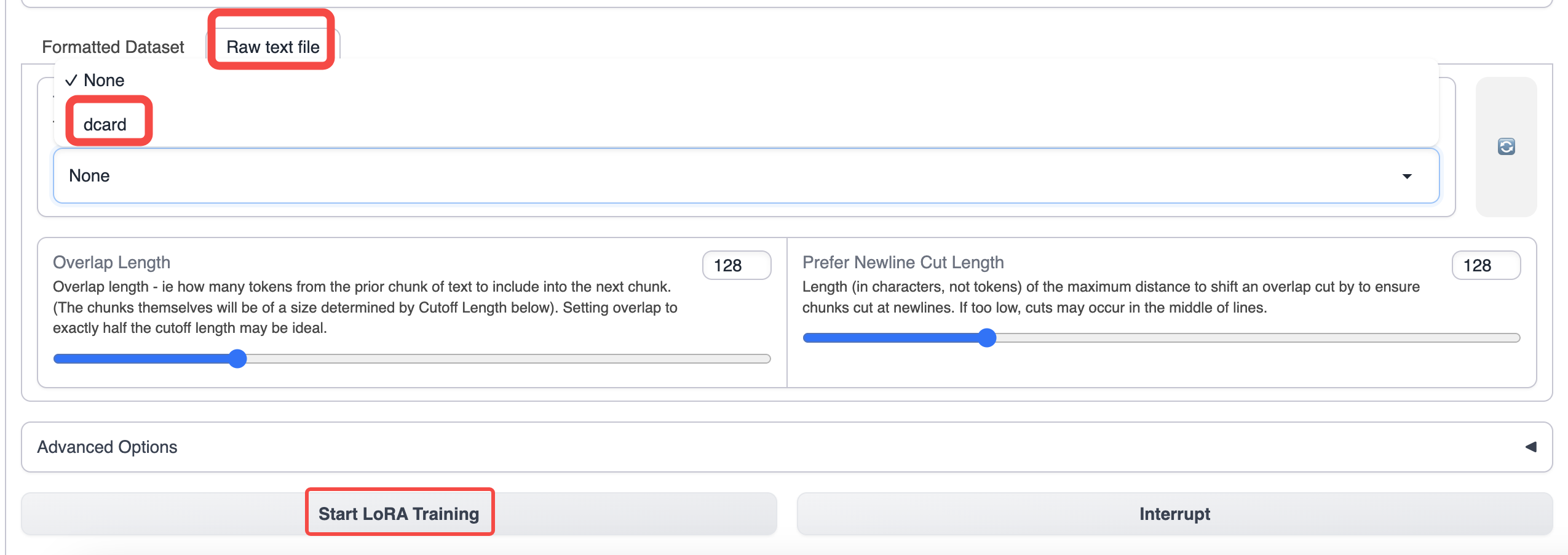
使用默认的参数进行训练即可,如果希望增加上下文长度,可以调高 cutoff 参数
开始训练后,能在 text-generation-webui 看到训练进度
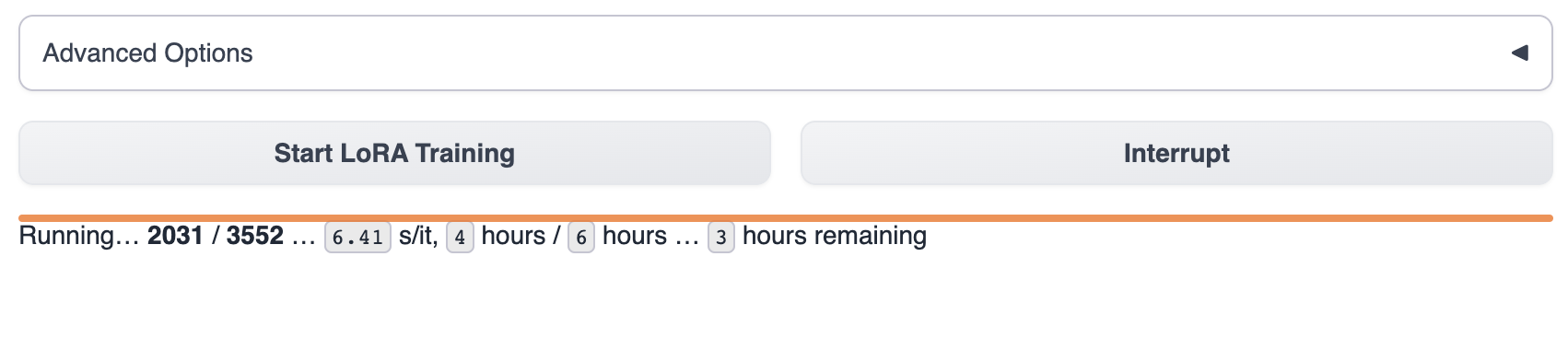
等待模型训练完成,通常,这将持续1~8个小时。训练数据的大小,训练参数,GPU型号区别都会影响模型的训练速度
训练过程中的产物保存在 lora 目录下,你也可以中途中断训练,直接使用 lora 目录现有的 checkpoint 模型
在 lora 目录下手动新建一个文件夹,名字为你希望的 lora 模型的名字
将最新的 checkpoint 模型,从文件夹中复制到 lora 目录下
然后在 text-generation-webui 中选择 lora 模型进行使用
对于如何使用模型,请参考模型使用概述/使用文字类模型
如果您对于如何微调模型仍然存在疑惑,我们提供了两个真实的微调案例流程供您参考
📄️ Dcard 情感区微调(中文)
在线体验
📄️ Reddit Crushes Post 微调
在线体验
- Dcard Emotion fine-tune (Chinese)
- Reddit Fine-tune