Treinamento de Modelos Ajustados Fino para Textos
Atualmente, modelos populares de geração de texto, como LLama e ChatGLM, mesmo em tamanhos relativamente pequenos, são difíceis de serem totalmente ajustados em GPUs de consumo. Portanto, aqui, não discutimos como realizar ajuste fino de parâmetros em modelos ajustados fino para texto, apenas focamos em como realizar um ajuste fino leve.
Ferramentas de Treinamento 🔧
No campo de modelos de geração de imagem, geralmente é baseado em Stable Diffusion e geralmente tem a mesma estrutura de rede. Diferentes modelos de geração de texto podem vir de modelos básicos diferentes. Aqui, usamos apenas a função de treinamento de modelo de ajuste fino da text-generation-webui para ilustrar como treinar modelos ajustados fino.
Atualmente, a text-generation-webui suporta os seguintes modelos populares, (para outros modelos que a text-generation-webui não suporta, você pode usar o método de ajuste fino do modelo correspondente para treinar, e o produto precisa estar no formato de modelo lora de peft)
| Modelo Básico | Ajuste Fino |
|---|---|
| LLaMA | Suportado |
| OPT | Suportado |
| GPT-J | Suportado |
| GPT-NeoX | Suportado |
| RWKV | Não suportado |
| ChatGLM | Não suportado, por favor use ferramentas de terceiros |
Seleção de Modelo
Os modelos da série LLama são atualmente os modelos mais populares.
No entanto, como o corpus usado no treinamento é principalmente em inglês, o suporte para outros idiomas é fraco.
Para o idioma inglês, é recomendado usar WizardLM-7B-Uncensored ou vicuna-7b-1.1 para um ajuste fino adicional em seus próprios dados.
Para o idioma chinês, é recomendado usar Linly-Chinese-LLaMA-7b-hf para ajuste fino.
Para o idioma coreano, é recomendado usar kollama-7b
| Modelo | Idioma |
|---|---|
| WizardLM-7B-Uncensored | Inglês |
| vicuna-7b-1.1 | Inglês |
| Linly-Chinese-LLaMA-7b-hf | Chinês |
| kollama-7b | Coreano |
Preparação de Dados 📚
Para modelos ajustados fino para texto, existem dois tipos de dados:
| Dados | Formato | Caso de Uso | Quando Usar | Desvantagens | Função |
|---|---|---|---|---|---|
| Dados de corpus de texto puro | Não há necessidade de formato de dados especial, coloque todo o texto em um ou mais arquivos txt | Completar texto | Por exemplo, se você quiser ajustar fino um modelo de escrita de histórias, insira o início da história e deixe o modelo preencher o restante do conteúdo | Após o ajuste fino, ele pode perder sua capacidade original | |
| Dados de instrução | É necessário um formato de dados especial | Diálogo, comando | Faz o modelo entender melhor a intenção humana |
Os dados de instrução são ajustados pelo conjunto de dados para fazer o modelo entender melhor a intenção humana.
Seja dados de instrução ou corpus de texto puro, é uma tarefa de completar texto.
Para dados de instrução, pode ser considerado como a entrada do modelo com instruções para completar o texto restante.
A text-generation-webui atualmente suporta ajuste fino lora para ambos os tipos de dados.
Treinando Modelos Ajustados Fino
Siga o guia de instalação da text-generation-webui para instalar a text-generation-webui.
Inicie a text-generation-webui e selecione a aba Modelo na parte superior.
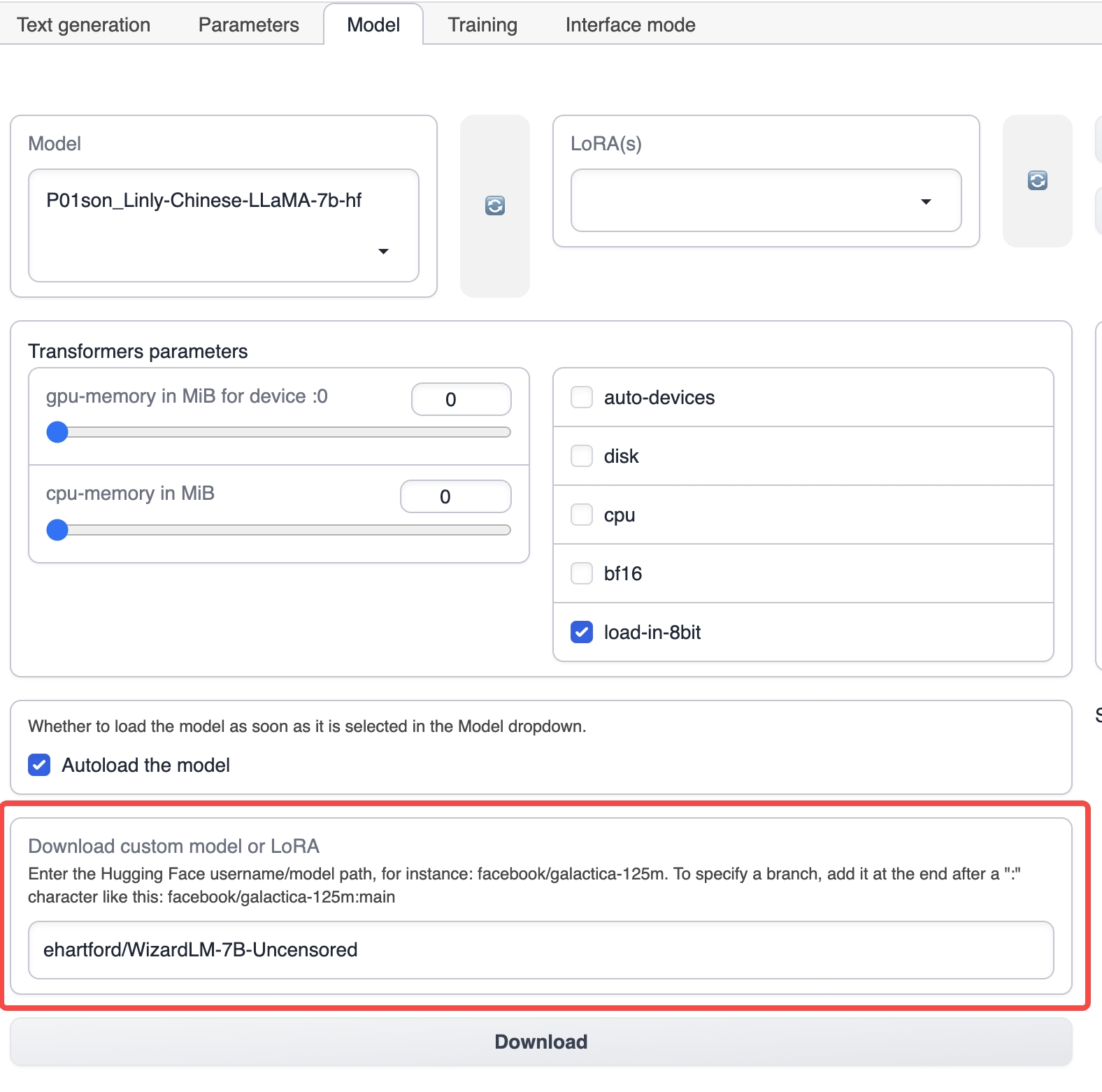
Na aba Modelo, insira o nome do modelo básico correspondente, como ehartford/WizardLM-7B-Uncensored, e clique em download para baixar o modelo básico (você também pode baixar manualmente o modelo e colocá-lo no diretório de modelos sob o diretório de instalação da text-generation-webui).
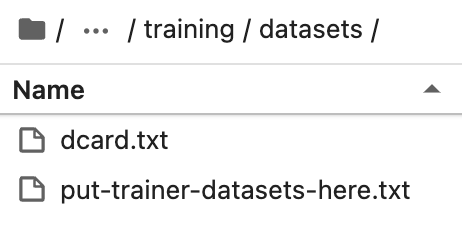
Coloque o conjunto de dados preparado no diretório de treinamento / conjuntos de dados sob o diretório de instalação da text-generation-webui.
Mude para a guia de treinamento da text-generation-webui e selecione os dados que você preparou.
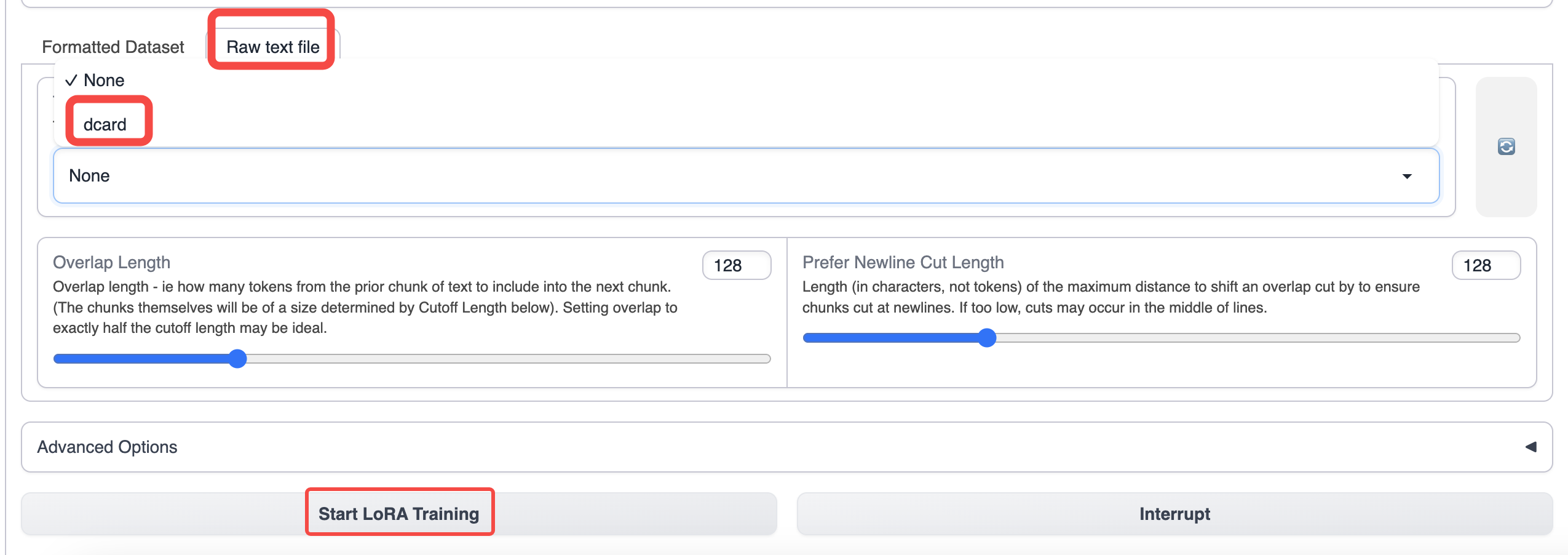
Use parâmetros padrão para treinamento. Se você quiser aumentar o comprimento do contexto, pode aumentar o parâmetro de corte.
Depois de iniciar o treinamento, você pode ver o progresso do treinamento na text-generation-webui.
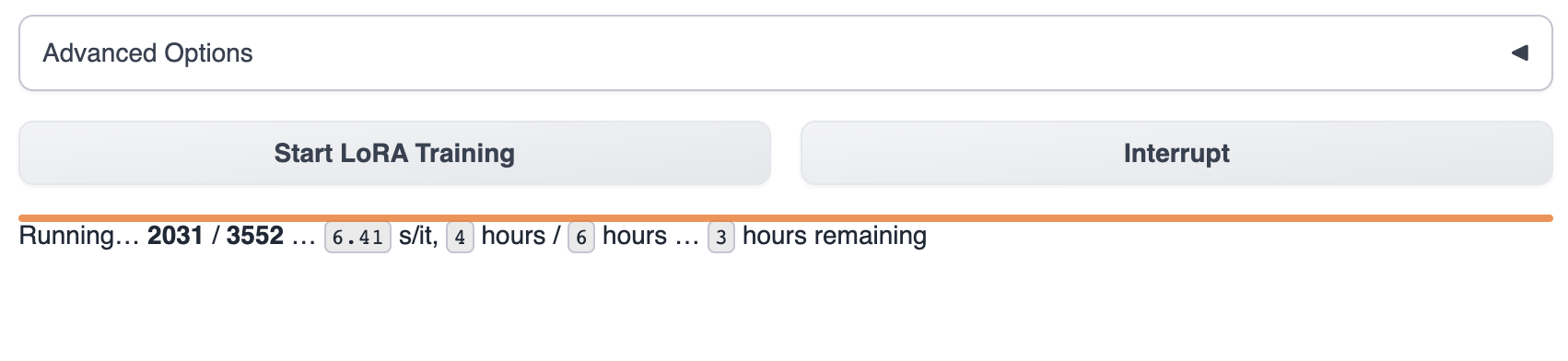
Aguarde o modelo terminar o treinamento, o que geralmente leva de 1 a 8 horas. O tamanho dos dados de treinamento, parâmetros de treinamento e diferenças de modelo de GPU afetarão a velocidade de treinamento do modelo.
O produto durante o processo de treinamento é salvo no diretório lora. Você também pode interromper o treinamento no meio do caminho e usar o modelo de checkpoint existente no diretório lora.
Crie manualmente uma pasta no diretório lora com o nome do modelo lora que você deseja.
Copie o modelo de checkpoint mais recente da pasta para o diretório lora.
Em seguida, selecione o modelo lora na text-generation-webui para uso.
Para saber como usar o modelo, consulte Visão geral do modelo/Usando modelos de texto
Se você ainda tiver dúvidas sobre como ajustar fino o modelo, fornecemos dois processos reais de ajuste fino de casos para sua referência.
📄️ Ajuste fino de sentimientos en Dcard (Chino)
Experiencia en línea
📄️ Ajuste fino de publicaciones de Reddit
Experiencia en línea
- Ajuste fino de emoções Dcard (Chinês)
- Ajuste fino de Reddit para inglês para espanhol