Schulung von feinabgestimmten Textmodellen
Aktuell sind beliebte Textgenerierungsmodelle wie LLama und ChatGLM selbst in relativ kleinen Größen auf Consumer-Grade-GPUs schwer vollständig feinabzustimmen. Daher diskutieren wir hier nicht, wie man eine vollständige Parameterfeinabstimmung bei Textmodellen durchführt, sondern konzentrieren uns nur darauf, wie man eine leichte Feinabstimmung durchführt.
Schulungswerkzeuge 🔧
Im Bereich der Bildgenerierungsmodelle basiert dies oft auf Stable Diffusion und hat in der Regel die gleiche Netzwerkstruktur. Unterschiedliche Textgenerierungsmodelle können aus verschiedenen Grundmodellen stammen. Hier verwenden wir nur die Funktion zum Schulen von Feinabstimmungsmodellen von text-generation-webui, um zu veranschaulichen, wie man Feinabstimmungsmodelle schult.
Derzeit unterstützt text-generation-webui beliebte Modelle wie folgt (für andere Modelle, die text-generation-webui nicht unterstützt, können Sie die Feinabstimmungsmethode des entsprechenden Modells zum Schulen verwenden, und das Produkt muss im Lora-Modellformat von [peft] (https://github.com/huggingface/peft) sein)
| Grundmodell | Feinabstimmung |
|---|---|
| LLaMA | Unterstützt |
| OPT | Unterstützt |
| GPT-J | Unterstützt |
| GPT-NeoX | Unterstützt |
| RWKV | Nicht unterstützt |
| ChatGLM | Nicht unterstützt, bitte verwenden Sie Tools von Drittanbietern |
Modellauswahl
Die LLaMA-Serienmodelle sind derzeit die mainstream-Modelle.
Da das für das Training verwendete Korpus hauptsächlich Englisch ist, ist die Unterstützung für andere Sprachen schwach.
Für die englische Sprache wird empfohlen, [WizardLM-7B-Uncensored] (https://huggingface.co/ehartford/WizardLM-7B-Uncensored) oder [vicuna-7b-1.1] (https://huggingface.co/eachadea/vicuna-7b-1.1) für die weitere Feinabstimmung auf Ihren eigenen Daten zu verwenden.
Für die chinesische Sprache wird empfohlen, [Linly-Chinese-LLaMA-7b-hf] (https://huggingface.co/P01son/Linly-Chinese-LLaMA-7b-hf) für die Feinabstimmung zu verwenden.
Für die koreanische Sprache wird empfohlen, [kollama-7b] (https://huggingface.co/beomi/kollama-7b) zu verwenden.
| Modell | Sprache |
|---|---|
| [WizardLM-7B-Uncensored] (https://huggingface.co/ehartford/WizardLM-7B-Uncensored) | Englisch |
| [vicuna-7b-1.1] (https://huggingface.co/eachadea/vicuna-7b-1.1) | Englisch |
| [Linly-Chinese-LLaMA-7b-hf] (https://huggingface.co/P01son/Linly-Chinese-LLaMA-7b-hf) | Chinesisch |
| [kollama-7b] (https://huggingface.co/beomi/kollama-7b) | Koreanisch |
Datenvorbereitung 📚
Für feinabgestimmte Textmodelle gibt es zwei Arten von Daten:
| Daten | Format | Anwendungsfall | Wann zu verwenden | Nachteile | Funktion |
|---|---|---|---|---|---|
| Reine Textkorpusdaten | Kein spezielles Datenformat erforderlich, legen Sie alle Texte in eine oder mehrere TXT-Dateien | Textergänzung | Wenn Sie beispielsweise ein Storywriting-Modell feinabstimmen möchten, geben Sie den Anfang der Geschichte ein und lassen Sie das Modell den Rest des Inhalts ausfüllen | Nach der Feinabstimmung kann es seine ursprüngliche Fähigkeit verlieren | |
| Anweisungsdaten | Spezielles Datenformat erforderlich | Dialog, Befehl | Machen Sie das Modell besser verstehen, was der Benutzer beabsichtigt |
Anweisungsdaten werden durch den Datensatz angepasst, um das Modell besser verstehen zu lassen, was der Benutzer beabsichtigt.
Ob es sich um Anweisungsdaten oder reine Textkorpora handelt, es handelt sich um eine Textergänzungsaufgabe.
Für Anweisungsdaten kann es als Eingabe des Modells mit Anweisungen zur Vervollständigung des restlichen Textes betrachtet werden.
text-generation-webui unterstützt derzeit das Lora-Feintuning für beide Arten von Daten.
Schulung von Feinabstimmungsmodellen
Befolgen Sie die Installationsanleitung von text-generation-webui, um text-generation-webui zu installieren.
Starten Sie text-generation-webui und wählen Sie den Modell-Tab aus dem oberen Tab aus.
Geben Sie unter dem Modell-Tab den Namen des entsprechenden Grundmodells ein, z. B. ehartford/WizardLM-7B-Uncensored, und klicken Sie dann auf Download, um das Grundmodell herunterzuladen (Sie können das Modell auch manuell herunterladen und unter dem Installationsverzeichnis von text-generation-webui im Models-Verzeichnis ablegen).
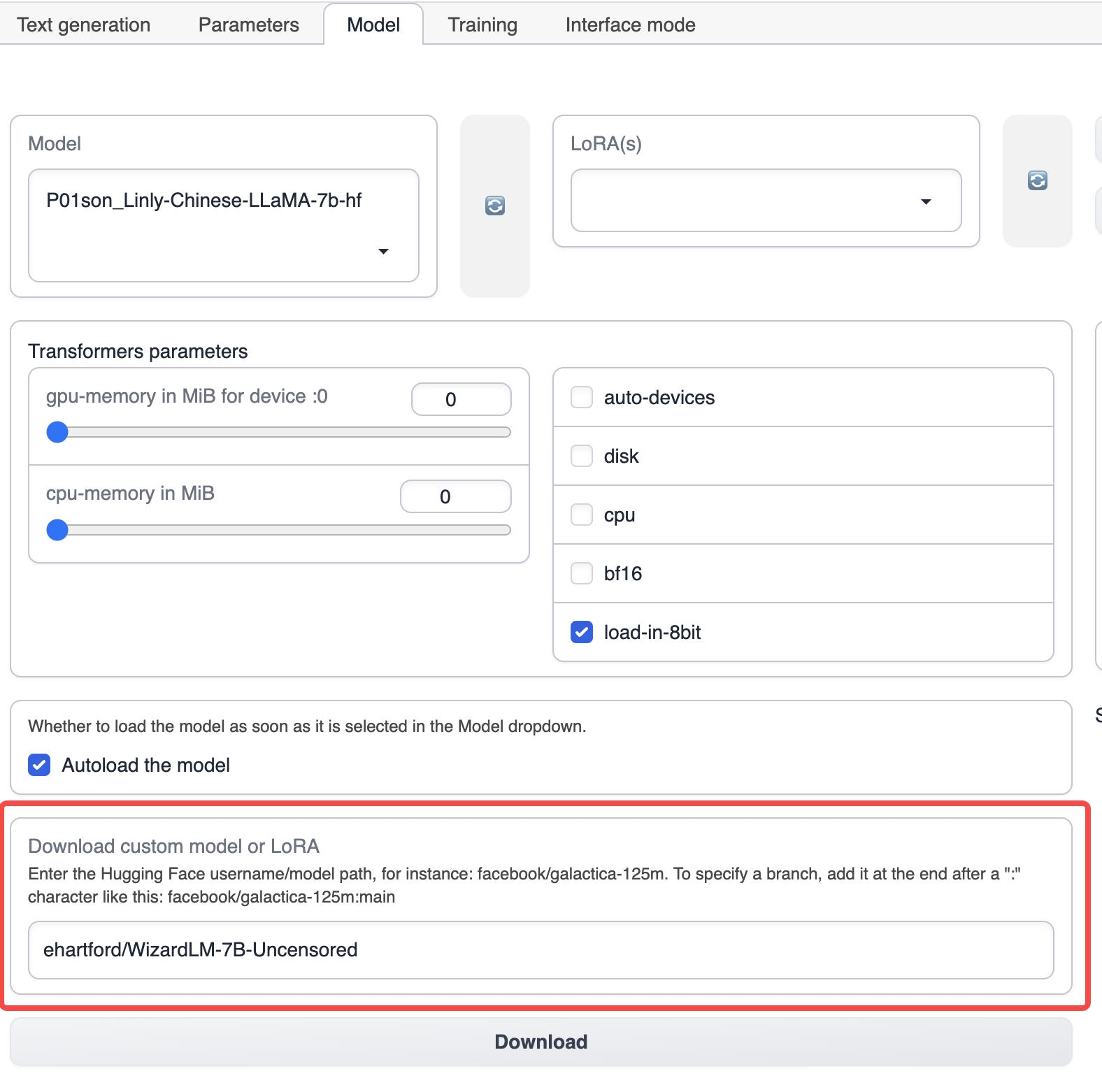
Legen Sie das vorbereitete Datenset im Verzeichnis training/datasets unter dem Installationsverzeichnis von text-generation-webui ab.
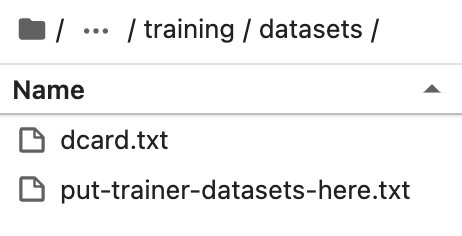
Wechseln Sie zum Schulungs-Tab von text-generation-webui und wählen Sie die von Ihnen vorbereiteten Daten aus.
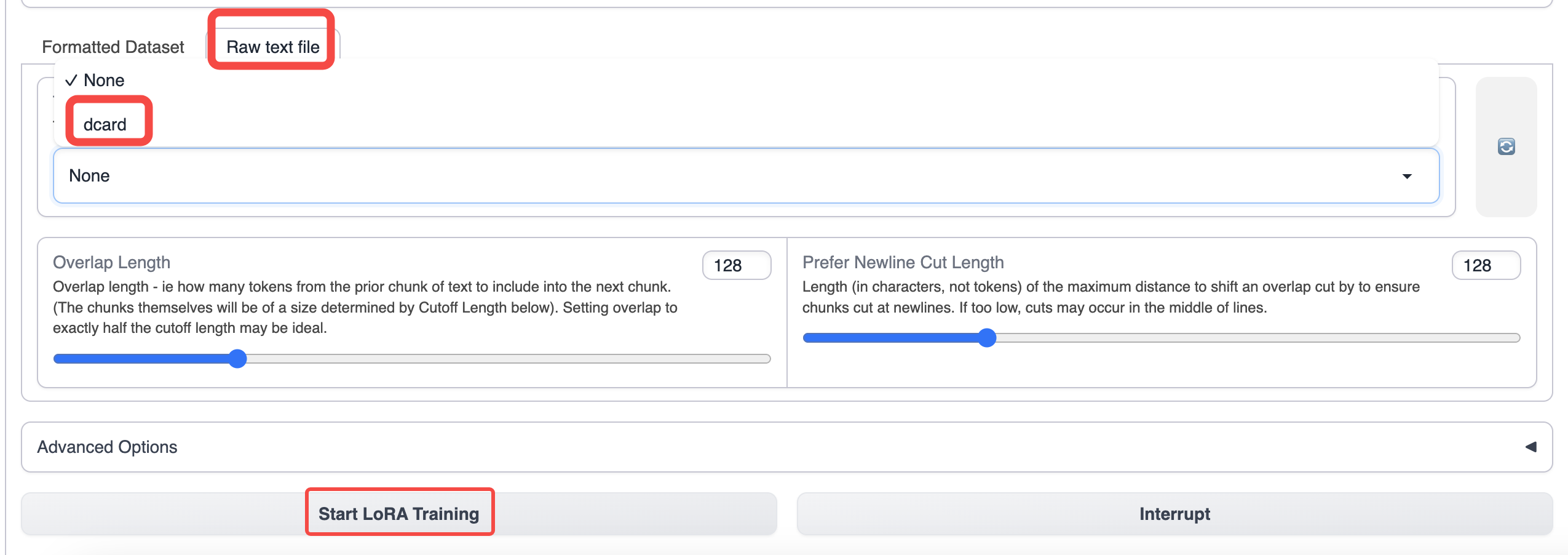
Verwenden Sie die Standardparameter für das Training. Wenn Sie die Kontextlänge erhöhen möchten, können Sie den Cutoff-Parameter erhöhen.
Nach dem Start des Trainings können Sie den Schulungsfortschritt in text-generation-webui sehen.
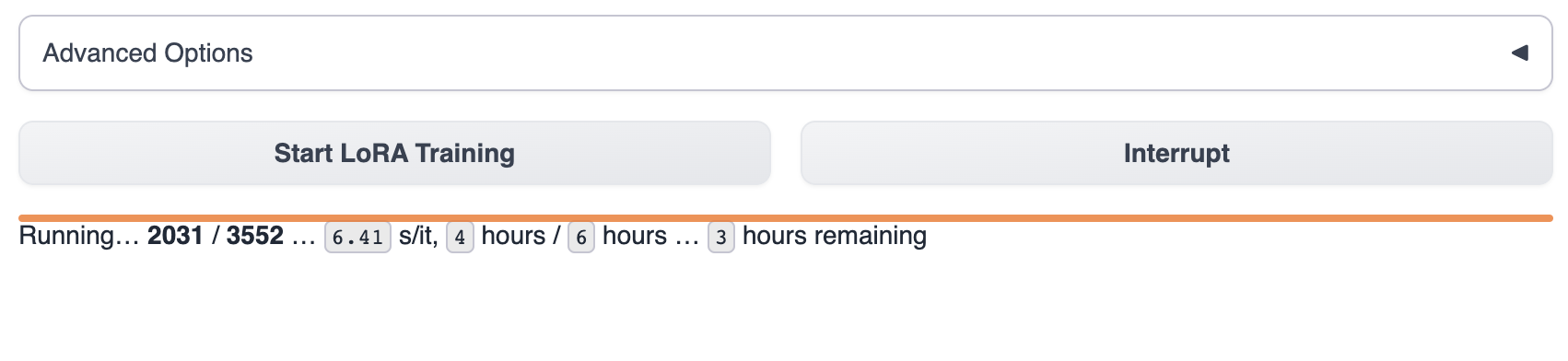
Warten Sie, bis das Modell das Training abgeschlossen hat, was normalerweise 1-8 Stunden dauert. Die Größe der Schulungsdaten, die Schulungsparameter und die Unterschiede im GPU-Modell beeinflussen die Schulungsgeschwindigkeit des Modells.
Das Produkt während des Schulungsprozesses wird im Lora-Verzeichnis gespeichert. Sie können das Training auch unterbrechen und das vorhandene Checkpoint-Modell im Lora-Verzeichnis verwenden.
Erstellen Sie manuell einen Ordner im Lora-Verzeichnis mit dem Namen des Lora-Modells, das Sie möchten.
Kopieren Sie das neueste Checkpoint-Modell aus dem Ordner in das Lora-Verzeichnis.
Wählen Sie dann das Lora-Modell in text-generation-webui zur Verwendung aus.
Für Informationen zur Verwendung des Modells lesen Sie bitte Model Overview/Using Text Models
Wenn Sie immer noch Zweifel haben, wie man das Modell feinabstimmt, bieten wir zwei reale Feinabstimmungsprozesse als Referenz an.
📄️ Dcard Sentiment Fine-tuning (Chinese)
Online-Erfahrung
📄️ Reddit Crushes Post Feineinstellung
Online-Erfahrung
- Dcard Emotion Feinabstimmung (Chinesisch)
- Reddit Feinabstimmung auf Englisch zu Deutsch