Обучение моделей с тонкой настройкой текста
В настоящее время популярные модели генерации текста, такие как LLama и ChatGLM, даже в относительно небольших размерах, трудно полностью настроить на обычных графических процессорах. Поэтому здесь мы не обсуждаем, как выполнить полно-параметрическую тонкую настройку на моделях с тонкой настройкой текста, мы сосредоточены только на том, как выполнить легкую тонкую настройку.
Инструменты для обучения 🔧
В области моделей генерации изображений это часто основано на Stable Diffusion и обычно имеет ту же сетевую структуру. Различные модели генерации текста могут происходить от разных базовых моделей. Здесь мы используем только функцию обучения модели с тонкой настройкой text-generation-webui, чтобы показать, как обучать модели с тонкой настройкой.
В настоящее время text-generation-webui поддерживает следующие популярные модели (для других моделей, которые не поддерживает text-generation-webui, вы можете использовать метод тонкой настройки соответствующей модели для обучения, и продукт должен быть в формате модели lora peft)
| Базовая модель | Тонкая настройка |
|---|---|
| LLaMA | Поддерживается |
| OPT | Поддерживается |
| GPT-J | Поддерживается |
| GPT-NeoX | Поддерживается |
| RWKV | Не поддерживается |
| ChatGLM | Не поддерживается, используйте сторонние инструменты |
Выбор модели
Модели серии LLaMA в настоящее время являются наиболее распространенными моделями.
Однако, поскольку корпус, используемый в обучении, в основном на английском языке, поддержка других языков слабая.
Для английского языка рекомендуется использовать WizardLM-7B-Uncensored или vicuna-7b-1.1 для дальнейшей тонкой настройки на своих собственных данных.
Для китайского языка рекомендуется использовать Linly-Chinese-LLaMA-7b-hf для тонкой настройки.
Для корейского языка рекомендуется использовать kollama-7b
| Модель | Язык |
|---|---|
| WizardLM-7B-Uncensored | Английский |
| vicuna-7b-1.1 | Английский |
| Linly-Chinese-LLaMA-7b-hf | Китайский |
| kollama-7b | Корейский |
Подготовка данных 📚
Для моделей с тонкой настройкой текста существуют два типа данных:
| Данные | Формат | Применение | Когда использовать | Недостатки | Функция |
|---|---|---|---|---|---|
| Чистые текстовые корпусные данные | Не требуется специальный формат данных, поместите все тексты в один или несколько файлов txt | Завершение текста | Например, если вы хотите настроить модель написания истории, введите начало истории и позвольте модели заполнить остальное содержание | После тонкой настройки она может потерять свои первоначальные возможности | |
| Инструкционные данные | Требуется специальный формат данных | Диалог, команда | Сделать модель лучше понимать человеческий намерения |
Инструкционные данные настраиваются набором данных, чтобы модель лучше понимала человеческие намерения.
Независимо от того, являются ли это инструкционные данные или чистый текстовый корпус, это задача завершения текста.
Для инструкционных данных это можно рассматривать как входную модель с инструкциями для завершения оставшегося текста.
text-generation-webui в настоящее время поддерживает тонкую настройку lora для обоих типов данных.
Обучение моделей с тонкой настройкой
Следуйте инструкциям по установке text-generation-webui, чтобы установить text-generation-webui.
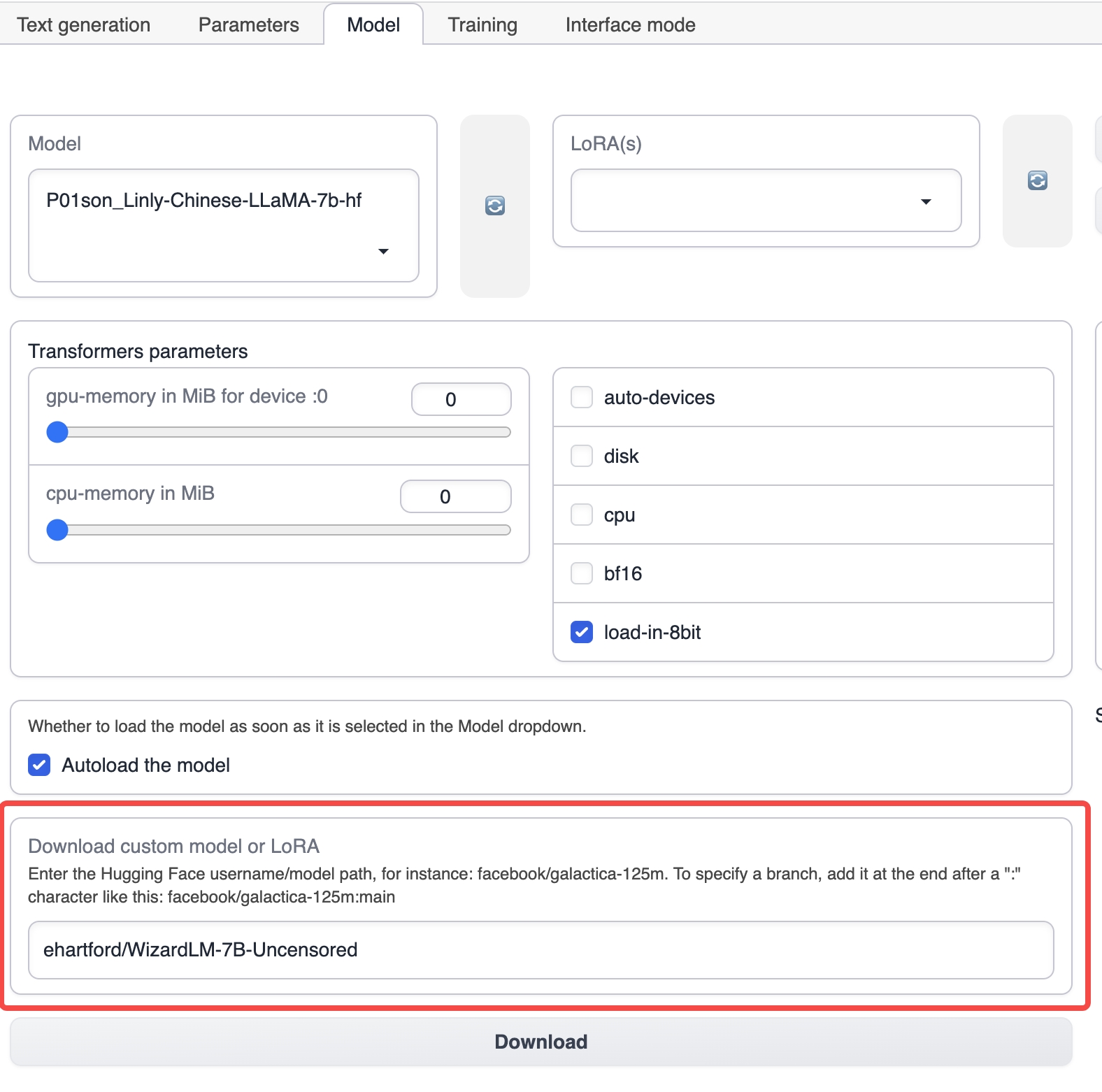
Запустите text-generation-webui и выберите вкладку Model из верхней вкладки.
Под вкладкой Model введите имя соответствующей базовой модели, например ehartford/WizardLM-7B-Uncensored, а затем нажмите кнопку загрузки, чтобы загрузить базовую модель (вы также можете вручную загрузить модель и поместить ее в каталог моделей в каталоге установки text-generation-webui).
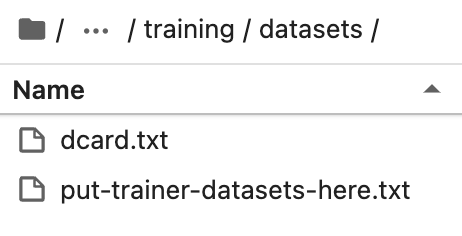
Поместите подготовленный набор данных в каталог training/datasets в каталоге установки text-generation-webui.
Переключитесь на вкладку training text-generation-webui и выберите подготовленные данные.
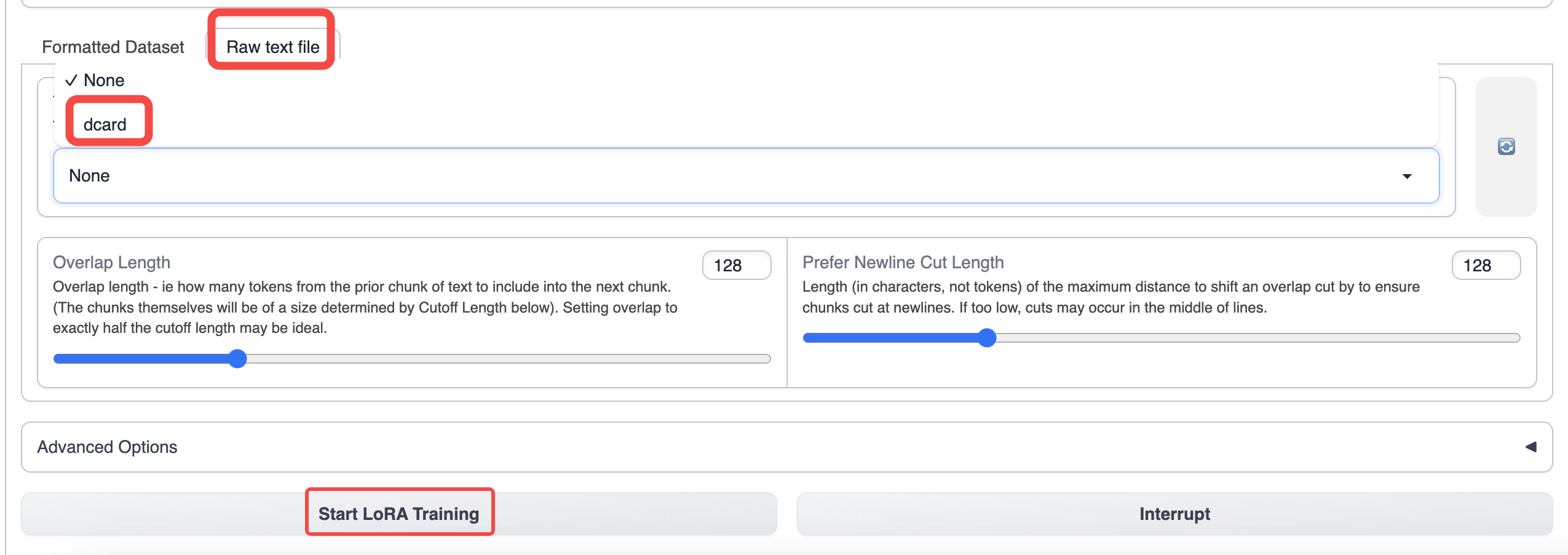
Используйте параметры по умолчанию для обучения. Если вы хотите увеличить длину контекста, вы можете увеличить параметр отсечения.
После запуска обучения вы можете увидеть прогресс обучения в text-generation-webui.
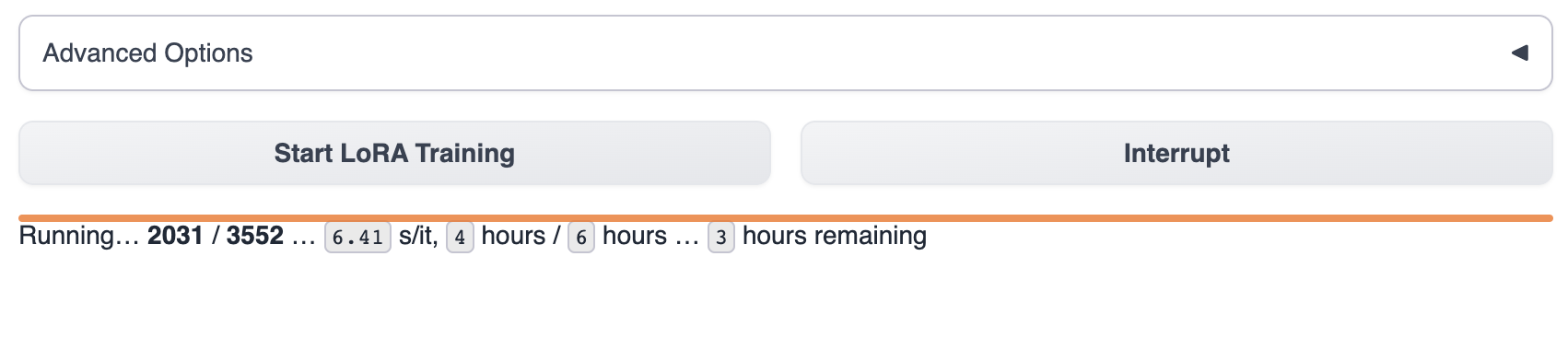
Дождитесь окончания обучения модели, что обычно занимает от 1 до 8 часов. Размер данных для обучения, параметры обучения и модель GPU различий будут влиять на скорость обучения модели.
Продукт во время процесса обучения сохраняется в каталоге lora. Вы также можете прервать обучение посередине и использовать существующую контрольную точку модели в каталоге lora.
Вручную создайте папку в каталоге lora с именем lora-модели, которую вы хотите.
Скопируйте последнюю контрольную точку модели из папки в каталоге lora.
Затем выберите модель lora в text-generation-webui для использования.
Для того, чтобы узнать, как использовать модель, обратитесь к Обзору модели/Использованию текстовых моделей
Если у вас все еще есть сомнения относительно тонкой настройки модели, мы предоставляем два реальных процесса тонкой настройки для вашего ознакомления.
📄️ Доводка настроенной модели Dcard Sentiment (китайский)
Опыт в Интернете
📄️ Reddit Crushes Post Fine-tune
Онлайн-опыт