Reddit Crushes Post 微调
在线体验
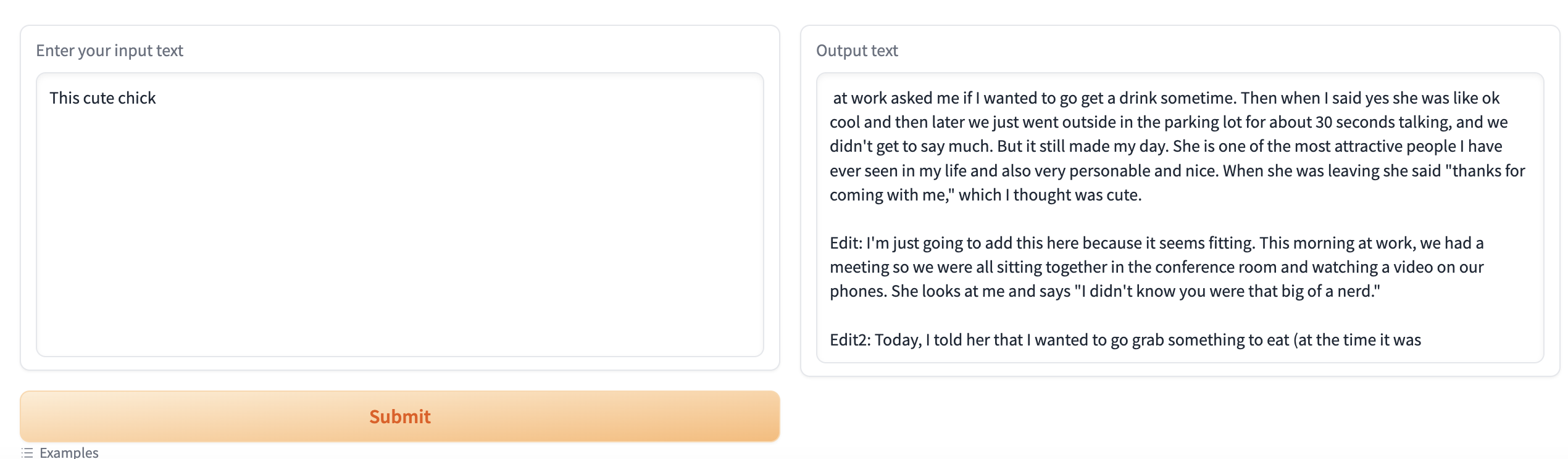
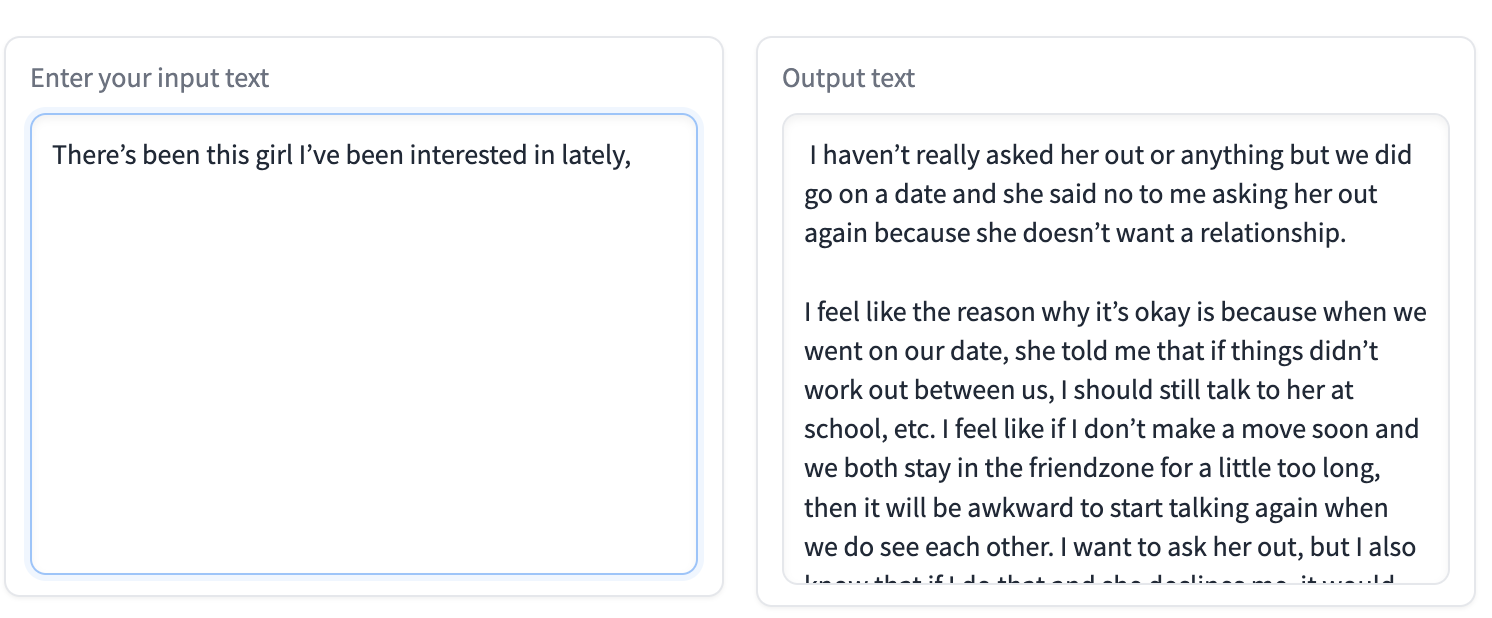
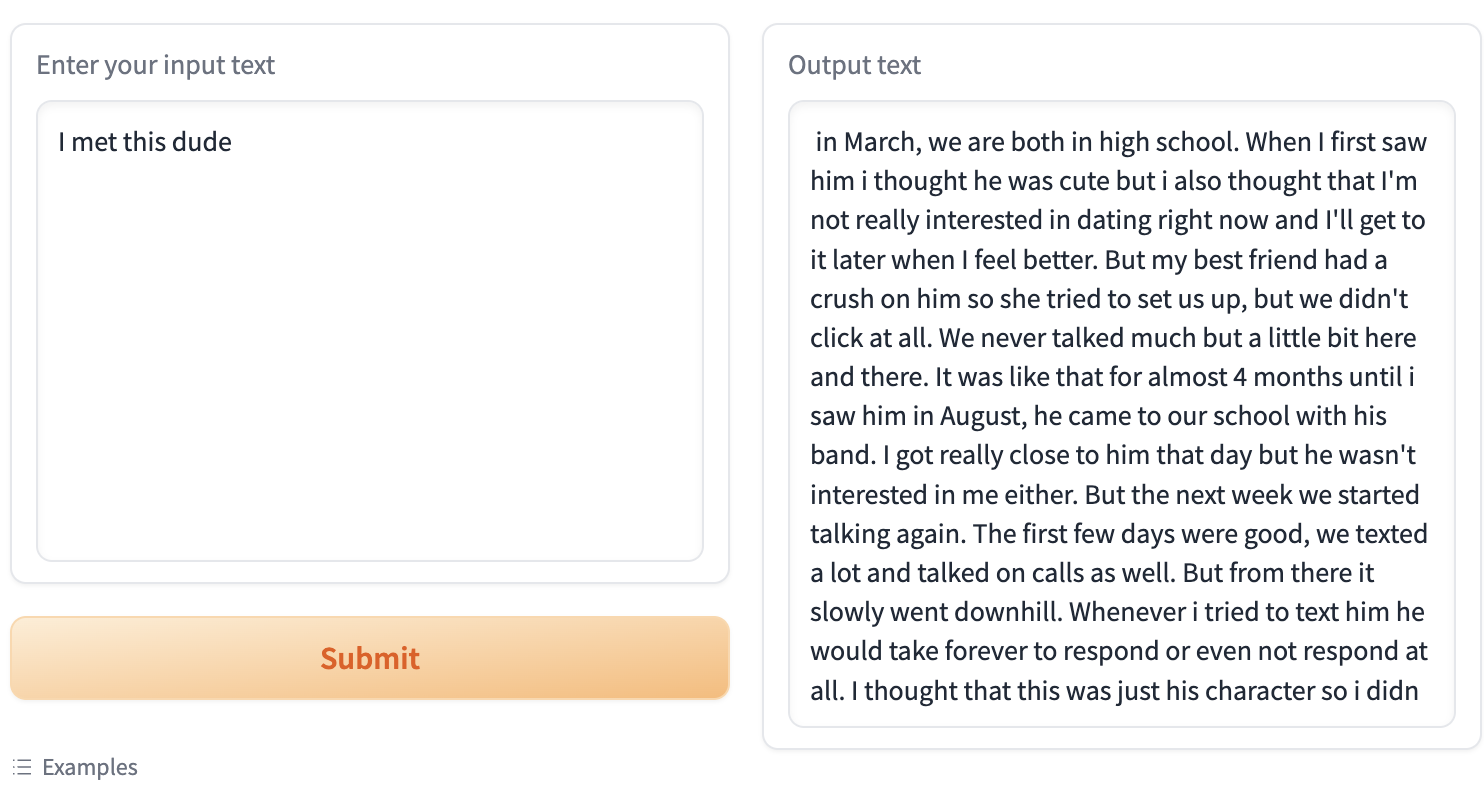
效果
数据说明
训练数据来源于 Reddit Crushes subreddit
采集了 Crushes 话题下的所有帖子
简要介绍
采集 Reddit Crush 的帖子数据,转为纯文本数据,然后在 TheBloke/Wizard-Vicuna-7B-Uncensored-HF 模型上进行了微调训练
教程
训练微调模型
安装text-generation-webui
按照 text-generation-webui 的安装指南,安装text-generation-webui
启动 text-generation-webui,从顶部的选项卡选择,进入到 Model 选项
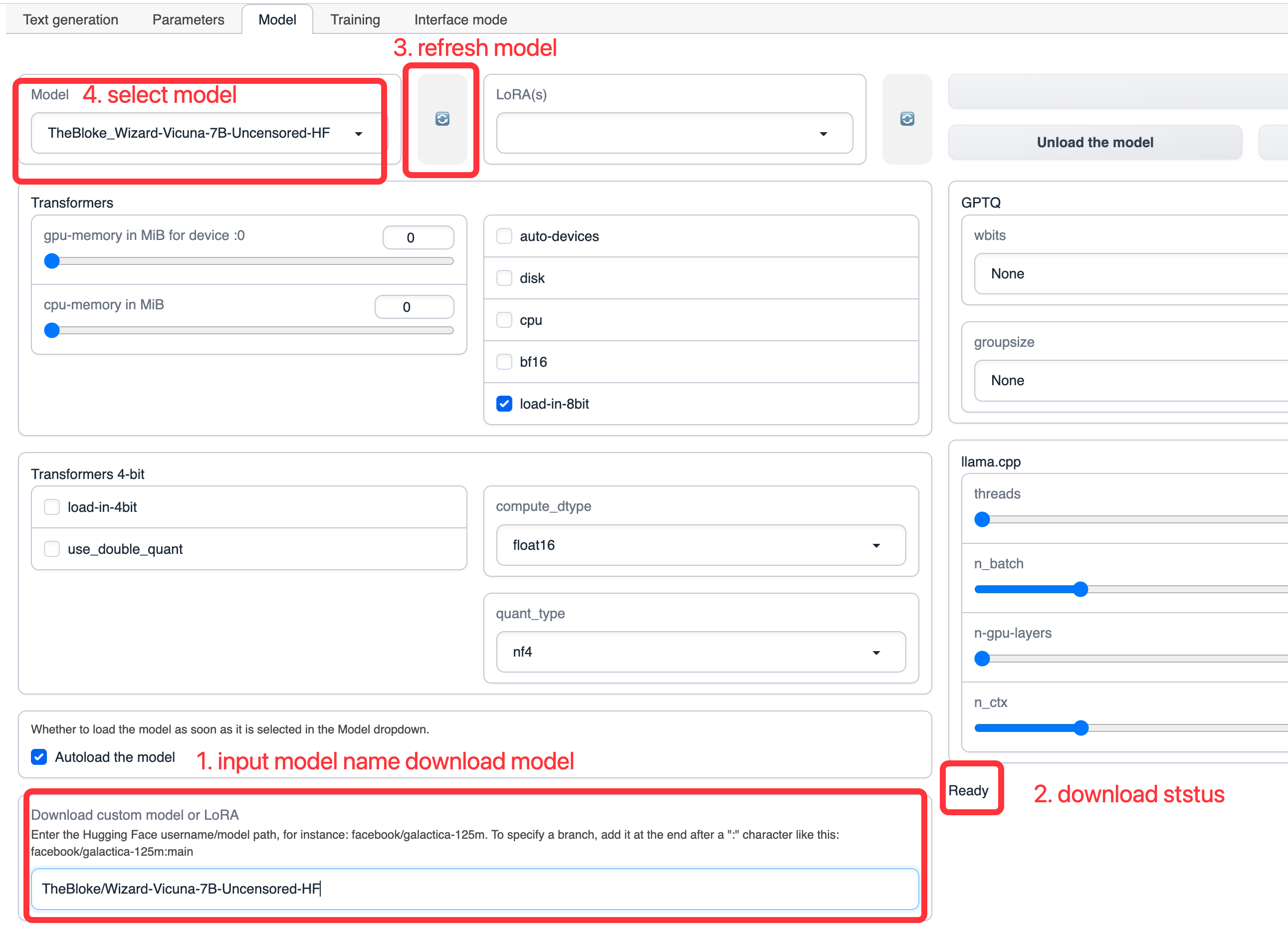
在 Model 选项卡下,输入 TheBloke/Wizard-Vicuna-7B-Uncensored-HF ,然后点击下载,下载基础模型(也可以手动下载模型,然后放到 text-generation-webui 安装目录下的 models 目录)
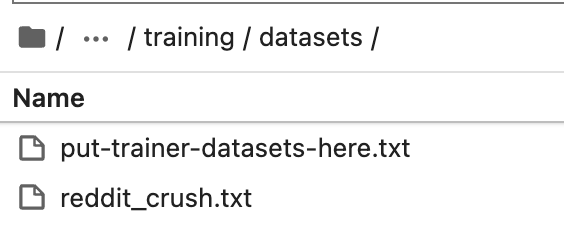
下载准备好的 reddit crush 数据集,将数据集放到 text-generation-webui 安装目录下的 training/datasets 里
切换到 text-generation-webui 的 training 选项卡
选择 reddit crush 数据
切换到 Raw text file,选择 reddit crush 数据
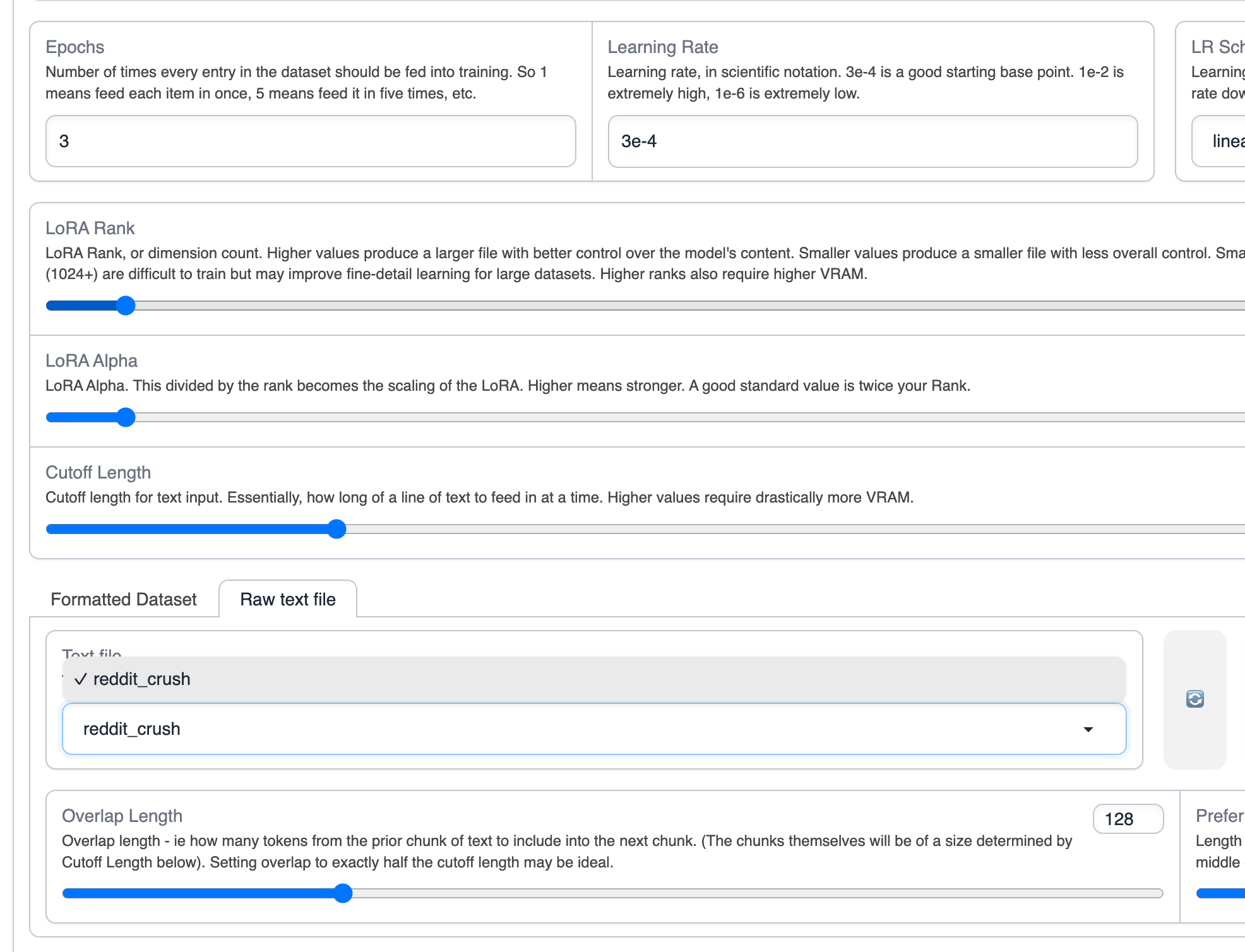
开始训练
使用默认的参数进行训练即可,如果希望增加上下文长度,可以调高 cutoff 参数,
点击 Start LoRA Training 开始训练
开始训练后,能在 text-generation-webui 看到训练进度
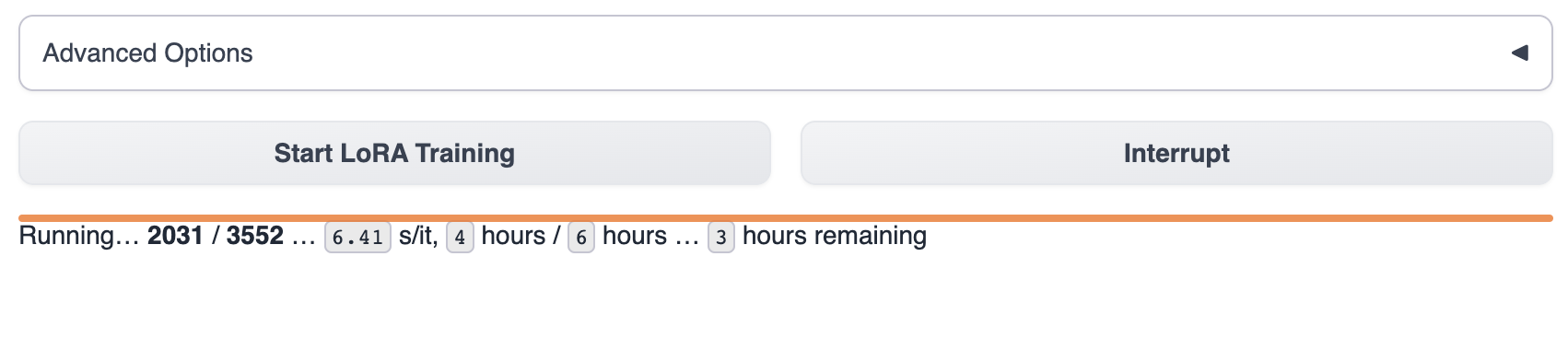
等待模型训练完成,通常,这将持续1~8个小时
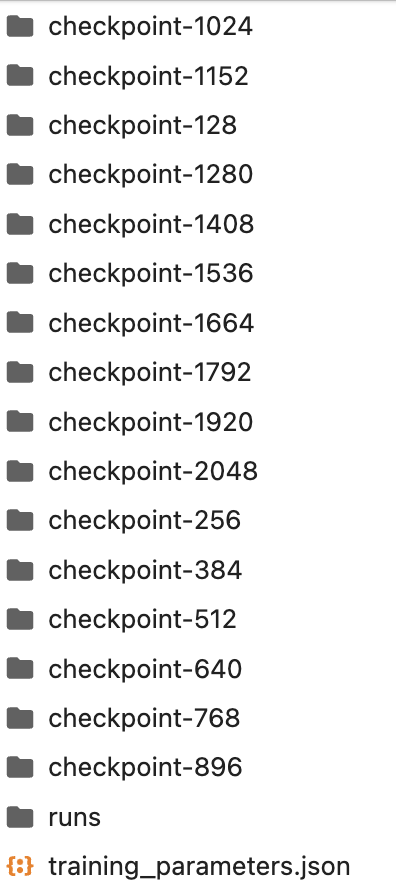
训练过程中的产物保存在 lora 目录下,你也可以中途中断训练,直接使用 lora 目录现有的 checkpoint 模型
使用模型
在 lora 目录下手动新建一个文件夹,名字为 reddit_crush
将最新的 checkpoint 模型,从文件夹中复制到 lora 目录下
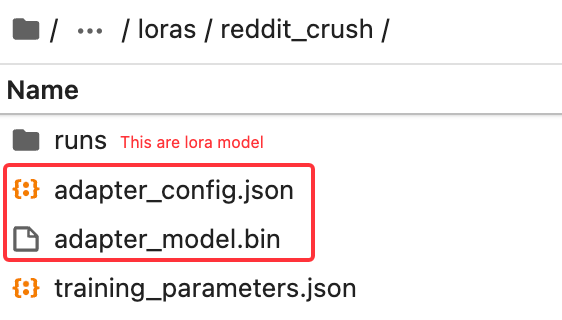
使用微调模型
切换到 Model 选项卡,先选择Model
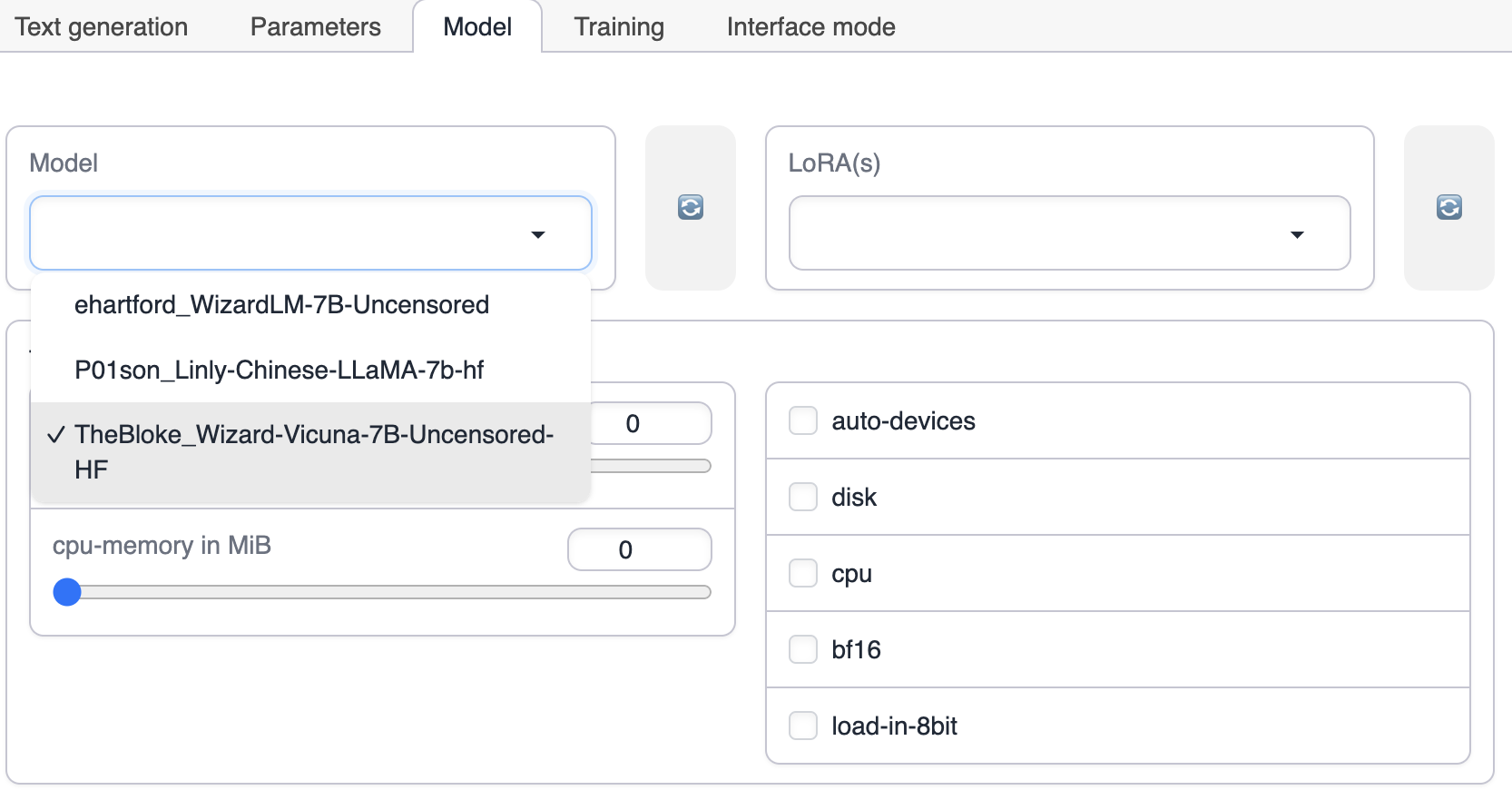
选择 LoRA,如果没有出现Lora的选择,请点击右边的刷新按钮或者检查LoRA模型是否已经放到text-generation-webui 的 LoRA目录下
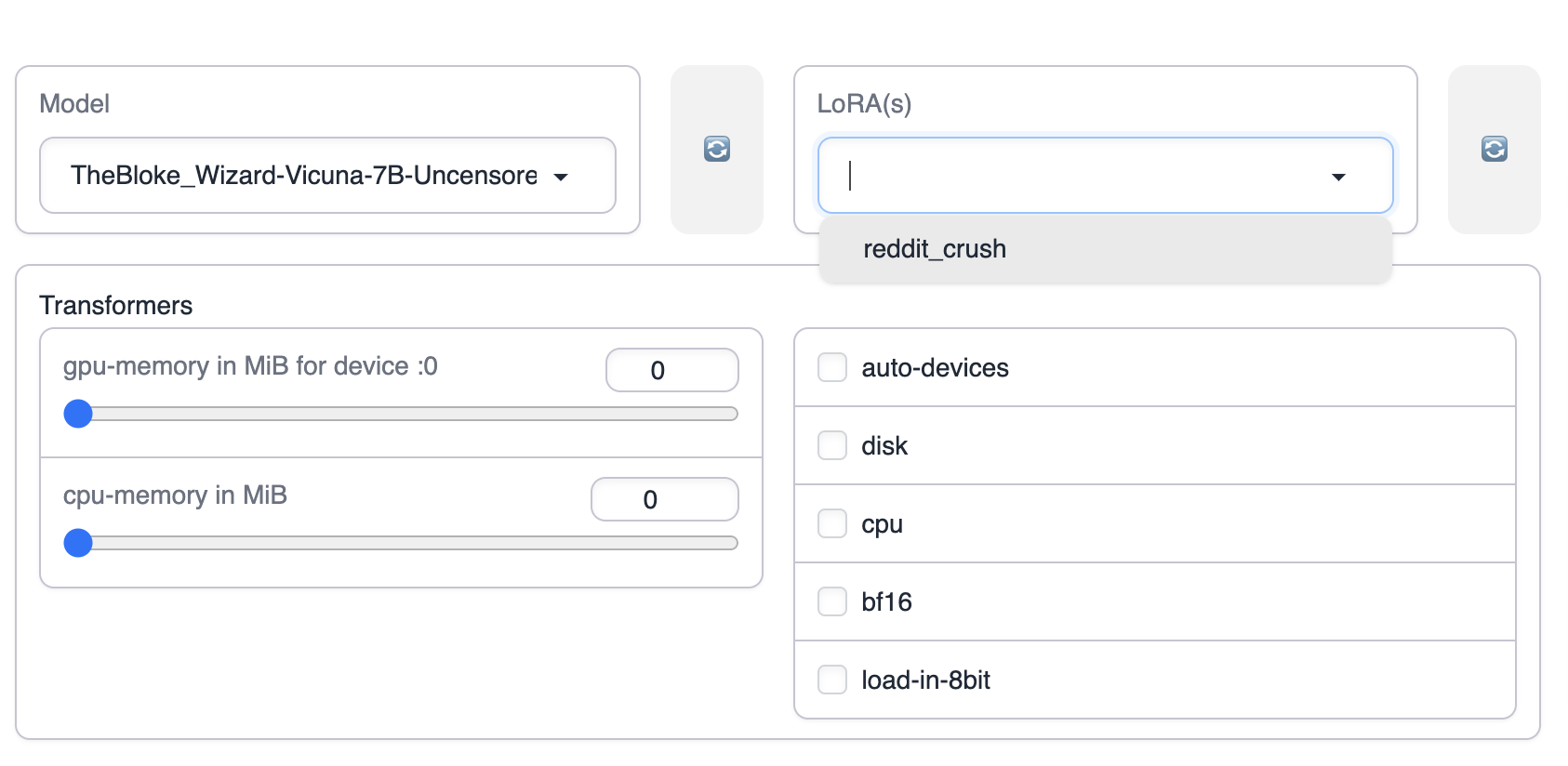
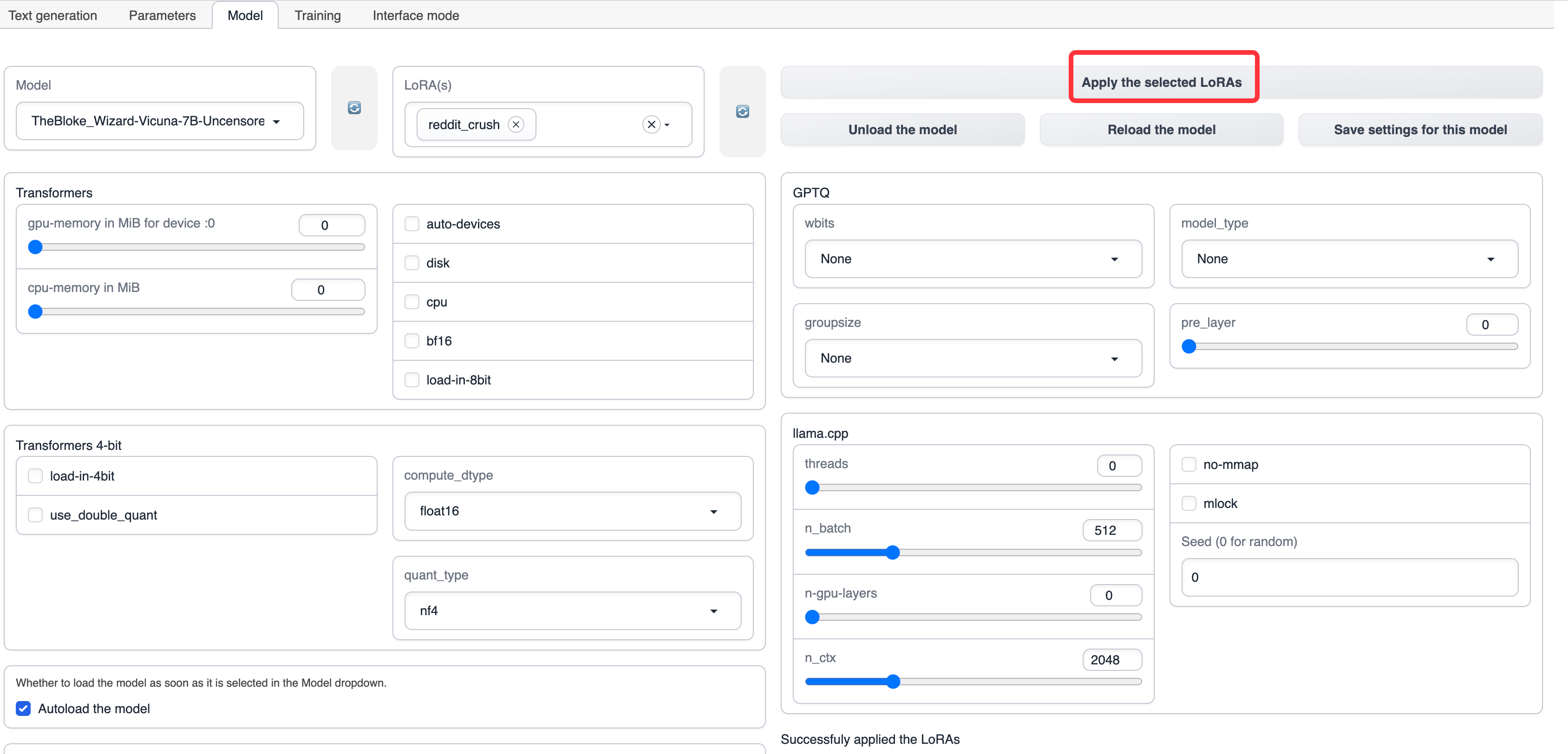
应用LoRA,点击 Apply the selected LoRAs
在应用成功后,可以看到提示
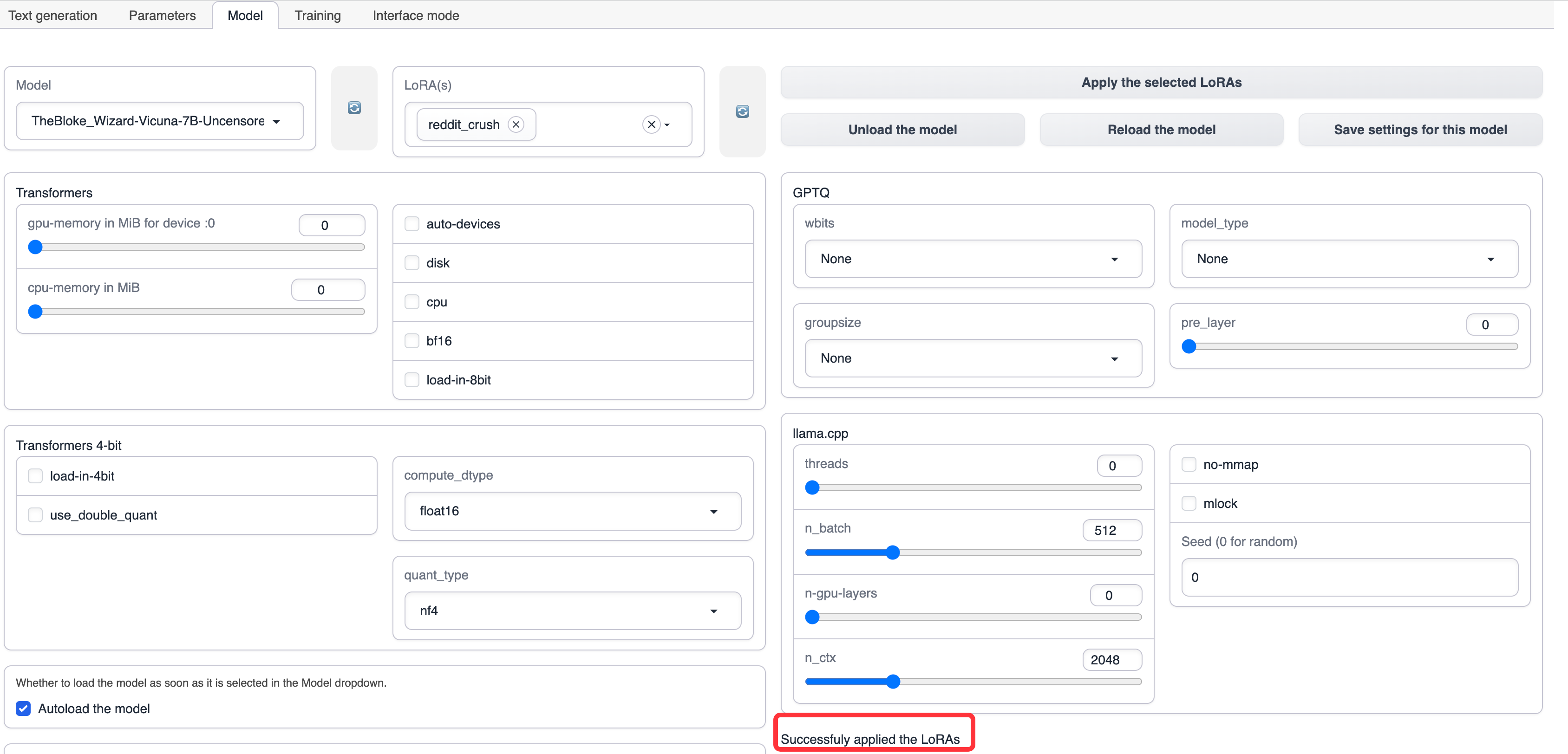
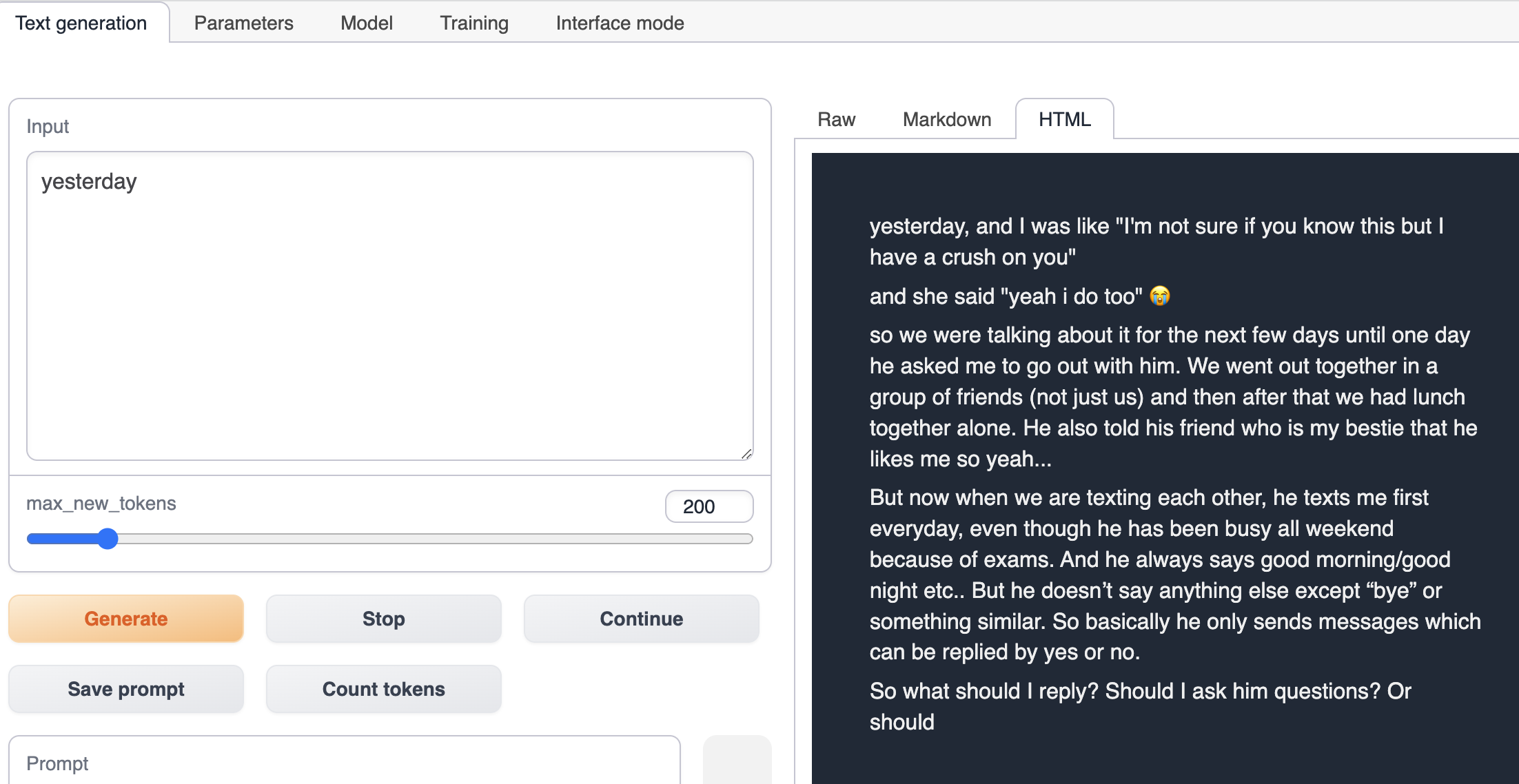
使用模型
切换到 Text generation 选项卡,然后输出故事的开头,点击Generate,会在右边自动生成故事的后续