テキストファインチューニングモデルのトレーニング
現在、LLamaやChatGLMなどの人気のあるテキスト生成モデルは、比較的小さいサイズでも、消費者向けのGPUで完全にファインチューニングするのは困難です。そのため、ここでは、テキストファインチューニングモデルの完全なパラメーターファインチューニングの実行方法については説明せず、軽量ファインチューニングの実行方法にのみ焦点を当てます。
トレーニングツール 🔧
画像生成モデルの分野では、Stable Diffusionに基づいており、通常同じネットワーク構造を持っています。異なるテキスト生成モデルは、異なる基本モデルから来る場合があります。ここでは、text-generation-webuiのトレーニングファインチューニングモデル機能のみを使用して、ファインチューニングモデルのトレーニング方法を説明します。
現在、text-generation-webuiは以下のような人気のあるモデルをサポートしています。(text-generation-webuiがサポートしていない他のモデルの場合、対応するモデルのファインチューニング方法を使用してトレーニングできます。製品はpeftのloraモデル形式である必要があります)
| 基本モデル | ファインチューニング |
|---|---|
| LLaMA | サポート |
| OPT | サポート |
| GPT-J | サポート |
| GPT-NeoX | サポート |
| RWKV | サポートされていません |
| ChatGLM | サポートされていません。サードパーティーのツールを使用してください |
モデル選択
LLaMAシリーズモデルは現在、最も主流のモデルです。
ただし、トレーニングで使用されるコーパスは主に英語なので、他の言語のサポートは弱いです。
英語の場合、WizardLM-7B-Uncensoredまたはvicuna-7b-1.1を使用して、独自のデータでさらにファインチューニングすることをお勧めします。
中国語の場合、Linly-Chinese-LLaMA-7b-hfを使用してファインチューニングすることをお勧めします。
韓国語の場合、kollama-7bを使用することをお勧めします。
| モデル | 言語 |
|---|---|
| WizardLM-7B-Uncensored | 英語 |
| vicuna-7b-1.1 | 英語 |
| Linly-Chinese-LLaMA-7b-hf | 中国語 |
| kollama-7b | 韓国語 |
データの準備 📚
テキストファインチューニングモデルには、2種類のデータがあります。
| データ | 形式 | 用途 | 使用する場合 | 欠点 | 関数 |
|---|---|---|---|---|---|
| 純粋なテキストコーパスデータ | 特別なデータ形式は必要ありません。すべてのテキストを1つまたは複数のtxtファイルに入れます。 | テキストの補完 | たとえば、物語作成モデルをファインチューニングする場合、物語の始まりを入力して、モデルに残りの内容を埋めさせます。 | ファインチューニング後、元の機能を失う可能性があります。 | |
| 指示データ | 特別なデータ形式が必要です | 対話、コマンド | モデルが人間の意図をよりよく理解するようにする |
指示データは、データセットによって調整され、モデルが人間の意図をよりよく理解できるようにします。
指示データであろうと純粋なテキストコーパスであろうと、テキストの補完タスクです。
指示データの場合、残りのテキストを完了するための指示を含むモデルの入力と見なすことができます。
text-generation-webuiは、現在、どちらのデータ形式に対してもloraファインチューニングをサポートしています。
ファインチューニングモデルのトレーニング
text-generation-webuiのインストールガイドに従って、text-generation-webuiをインストールします。
text-generation-webuiを起動し、トップタブからモデルタブを選択します。
モデルタブの下で、ehartford/WizardLM-7B-Uncensoredなどの対応する基本モデルの名前を入力し、ダウンロードをクリックして基本モデルをダウンロードします(モデルを手動でダウンロードして、text-generation-webuiのインストールディレクトリのmodelsディレクトリに置くこともできます)。
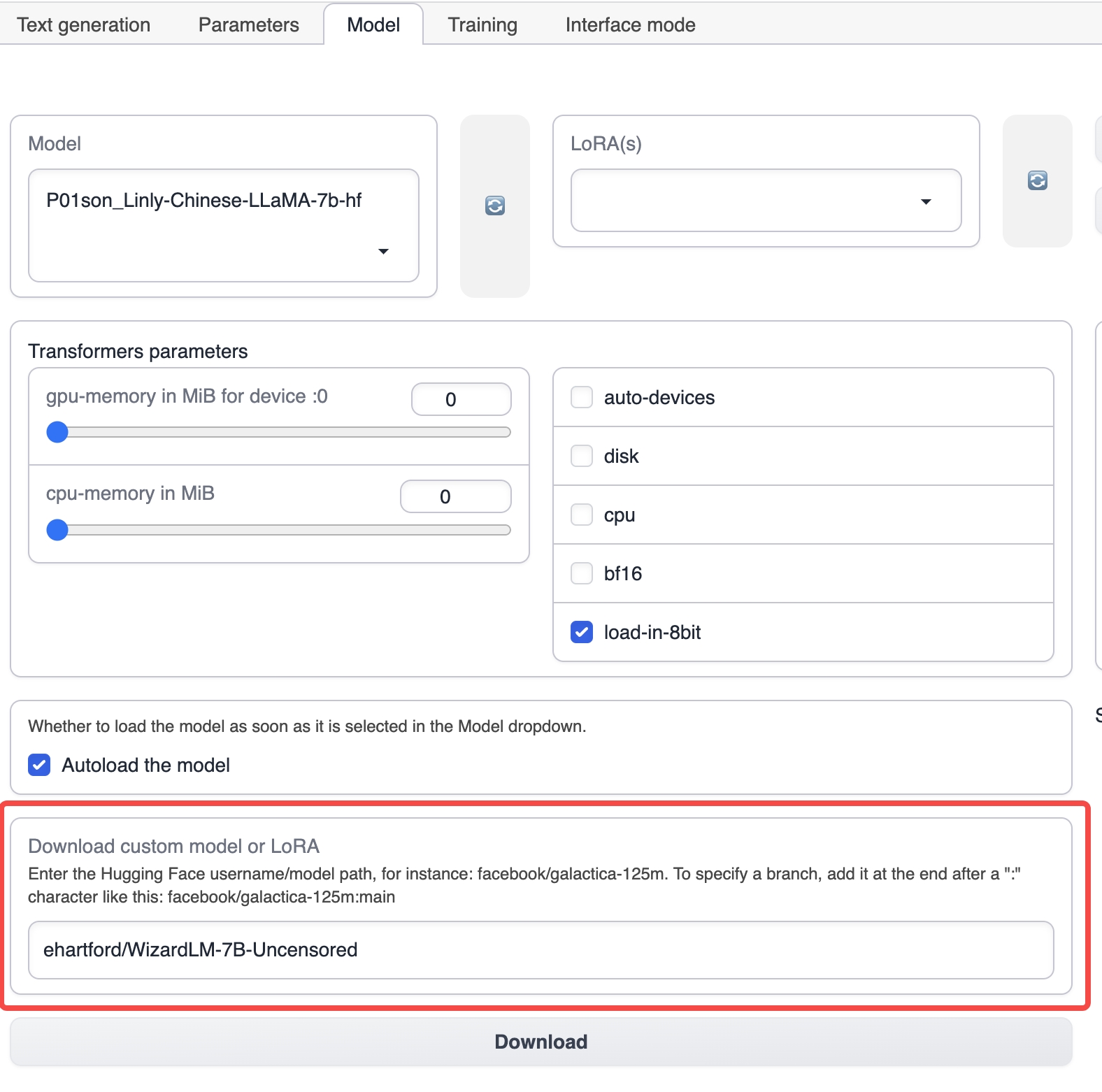
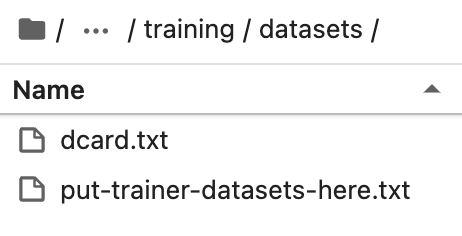
準備したデータセットをtext-generation-webuiのインストールディレクトリのtraining/datasetsディレクトリに置きます。
text-generation-webuiのトレーニングタブに切り替えて、準備したデータを選択します。
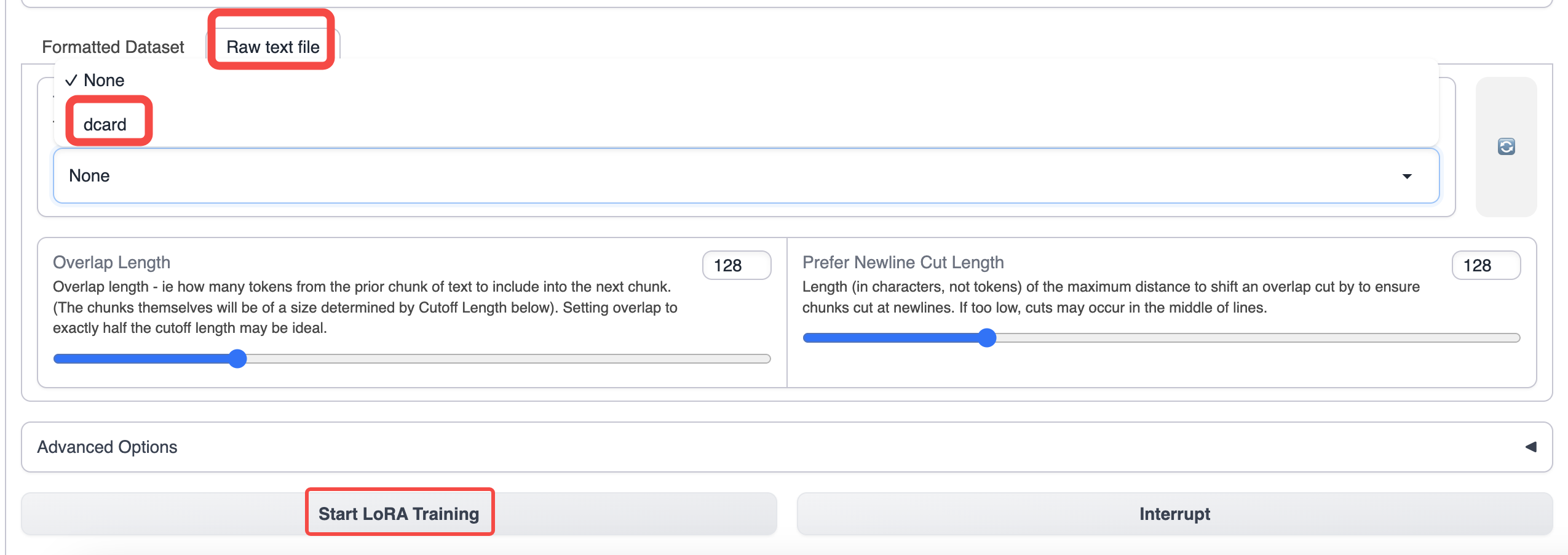
トレーニングにはデフォルトのパラメータを使用します。コンテキストの長さを増やしたい場合は、cutoffパラメータを増やすことができます。
トレーニングを開始すると、text-generation-webuiでトレーニングの進捗状況を確認できます。
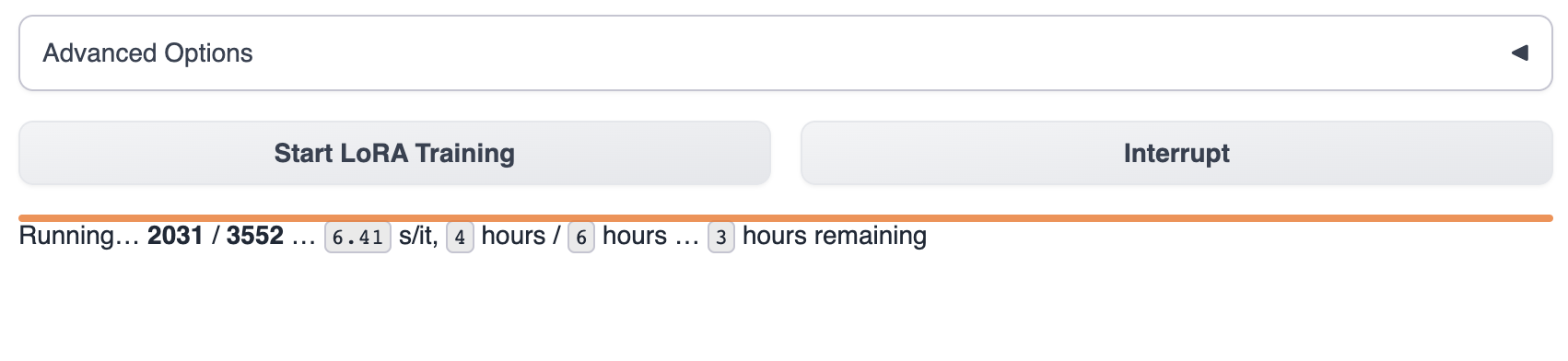
通常、トレーニングが完了するまで1〜8時間かかります。トレーニングデータのサイズ、トレーニングパラメータ、およびGPUモデルの違いは、モデルのトレーニング速度に影響を与えます。
トレーニングプロセス中の製品はloraディレクトリに保存されます。トレーニングを途中で中断し、loraディレクトリの既存のチェックポイントモデルを使用することもできます。
loraディレクトリに、使用したいloraモデルの名前でフォルダを手動で作成します。
フォルダから最新のチェックポイントモデルをloraディレクトリにコピーします。
次に、text-generation-webuiでloraモデルを選択して使用します。
モデルの使用方法については、「モデルの概要/テキストモデルの使用」を参照してください。
モデルのファインチューニング方法についてまだ疑問がある場合は、2つの実際のファインチューニングケースプロセスを参照してください。
📄️ Dcard Sentiment Fine-tuning (Chinese)
オンライン体験
📄️ Reddit Crushes Post Fine-tune
オンライン体験