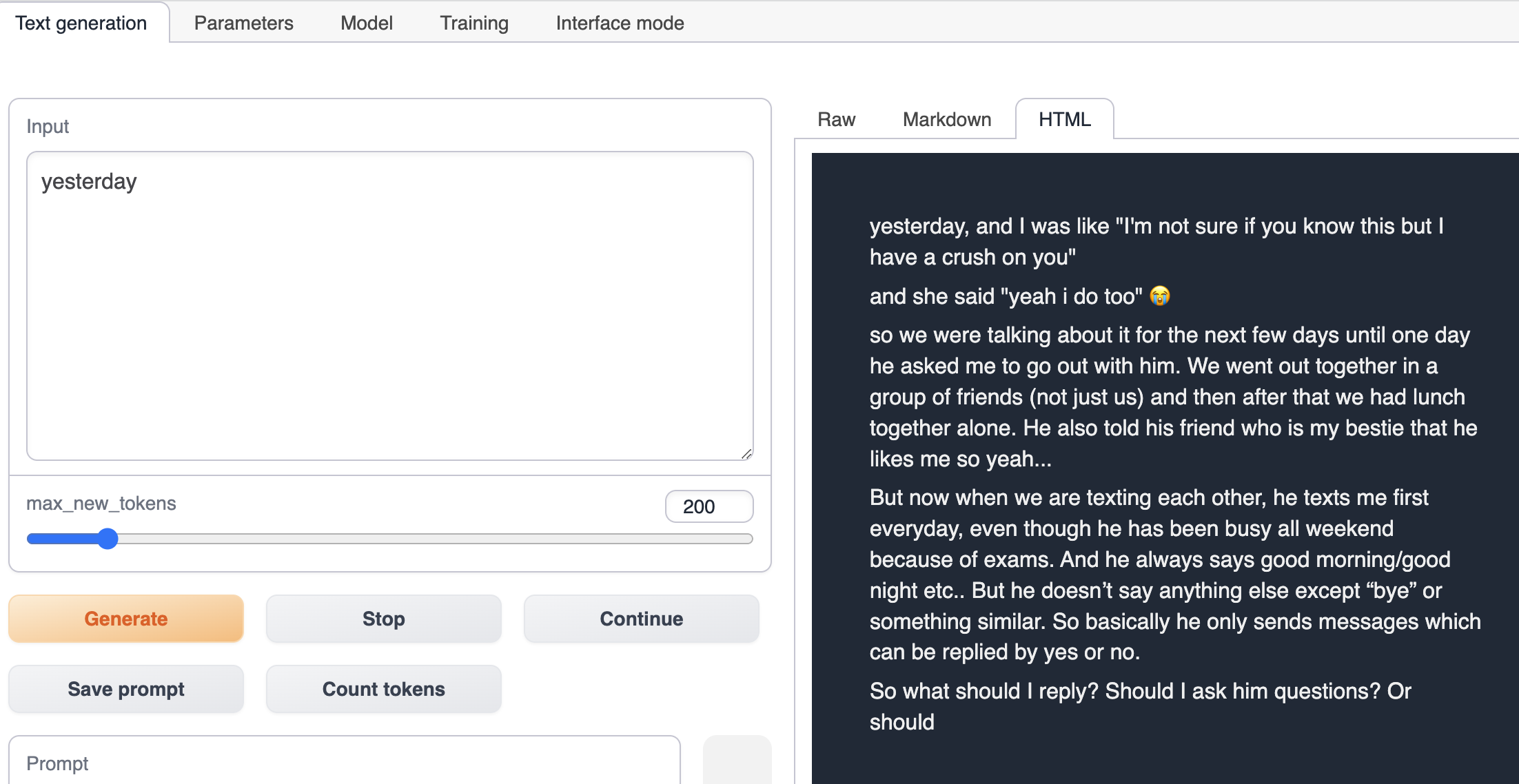
Reddit Crushes Post Fine-tune
オンライン体験
結果
データの説明
訓練データはReddit Crushes subredditから取得されました。
Crushesトピックのすべての投稿が収集されました。
簡単な紹介
Reddit Crushからポストデータを収集し、プレーンテキストデータに変換し、TheBloke/Wizard-Vicuna-7B-Uncensored-HFモデルでファインチューニングトレーニングを行います。
チュートリアル
ファインチューニングモデルのトレーニング
text-generation-webuiのインストール
text-generation-webuiのインストールガイドに従って、text-generation-webuiをインストールしてください。
text-generation-webuiを起動し、上部のタブからModelを選択します。
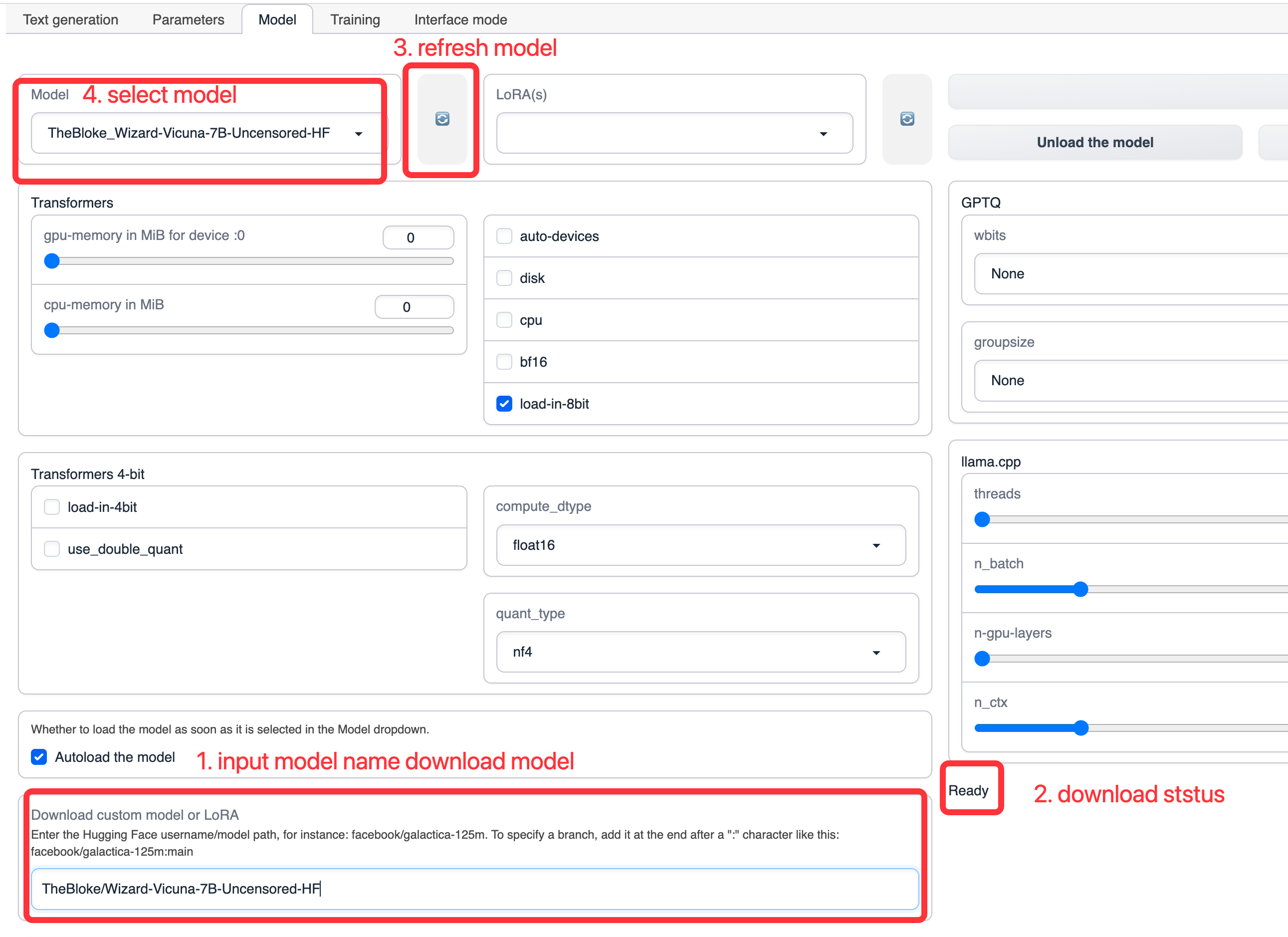
Modelタブで、TheBloke/Wizard-Vicuna-7B-Uncensored-HFを入力し、Downloadをクリックしてベースモデルをダウンロードします(モデルを手動でダウンロードして、text-generation-webuiのインストールディレクトリのmodelsディレクトリに配置することもできます)。
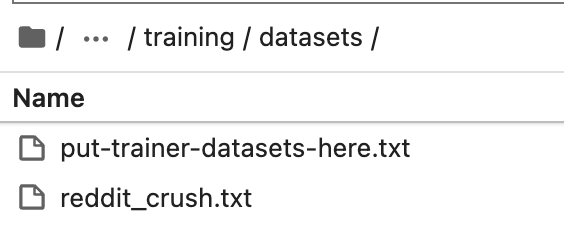
準備されたreddit crush datasetをダウンロードし、text-generation-webuiのインストールディレクトリのtraining/datasetsディレクトリにデータセットを配置します。
text-generation-webuiのトレーニングタブに切り替えます。
reddit crush datasetを選択します。
Raw text fileに切り替えて、reddit crush datasetを選択します。
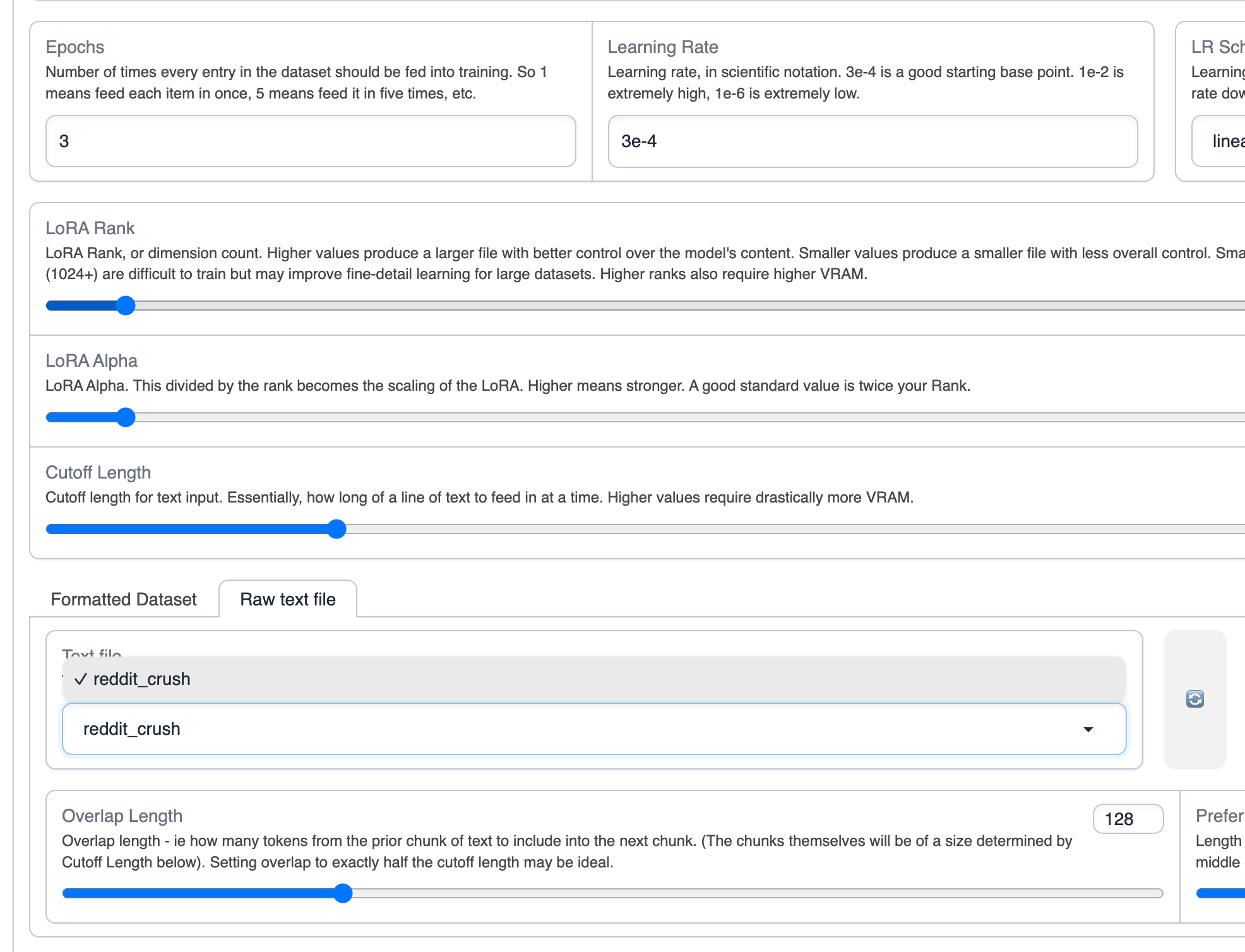
トレーニングを開始します。
トレーニングにはデフォルトのパラメータを使用します。コンテキストの長さを増やしたい場合は、cutoffパラメータを増やすことができます。
Start LoRA Trainingをクリックしてトレーニングを開始します。
トレーニングが開始されたら、text-generation-webuiでトレーニングの進捗状況を確認できます。
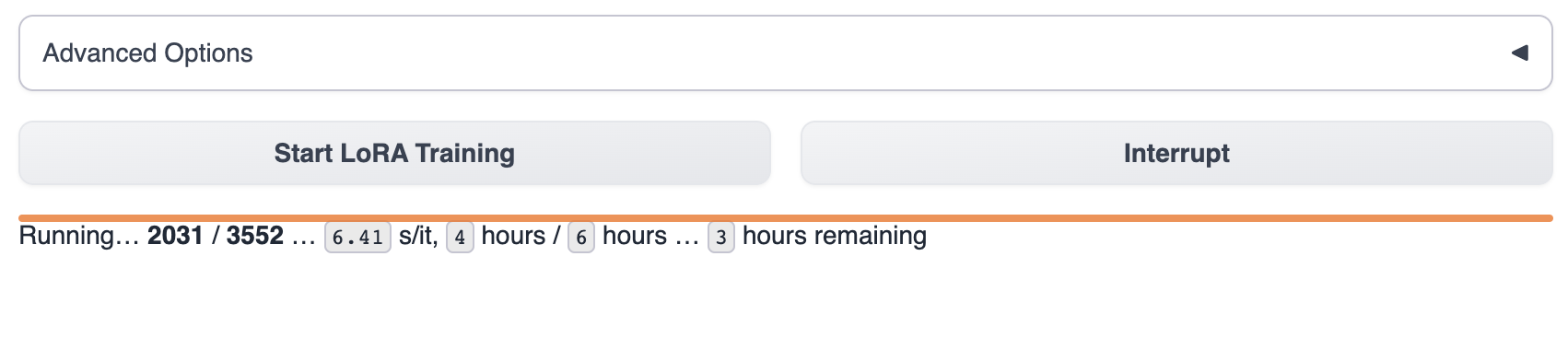
モデルのトレーニングが完了するまで待ちます。通常、これには1〜8時間かかります。
トレーニングプロセスの製品はloraディレクトリに保存されます。トレーニングを中断して、loraディレクトリの既存のチェックポイントモデルを使用することもできます。
モデルの使用
loraディレクトリにreddit_crushという名前のフォルダを手動で作成します。
最新のチェックポイントモデルをフォルダからloraディレクトリにコピーします。
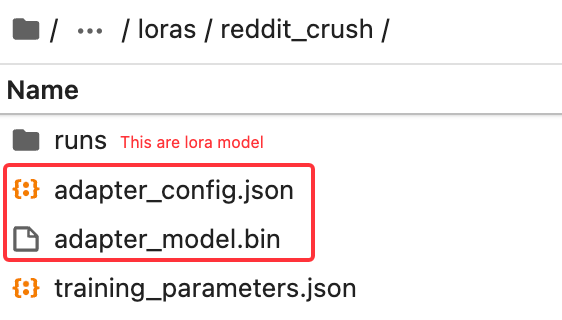
ファインチューニングモデルの使用
Modelタブに切り替えて、Modelを最初に選択します。
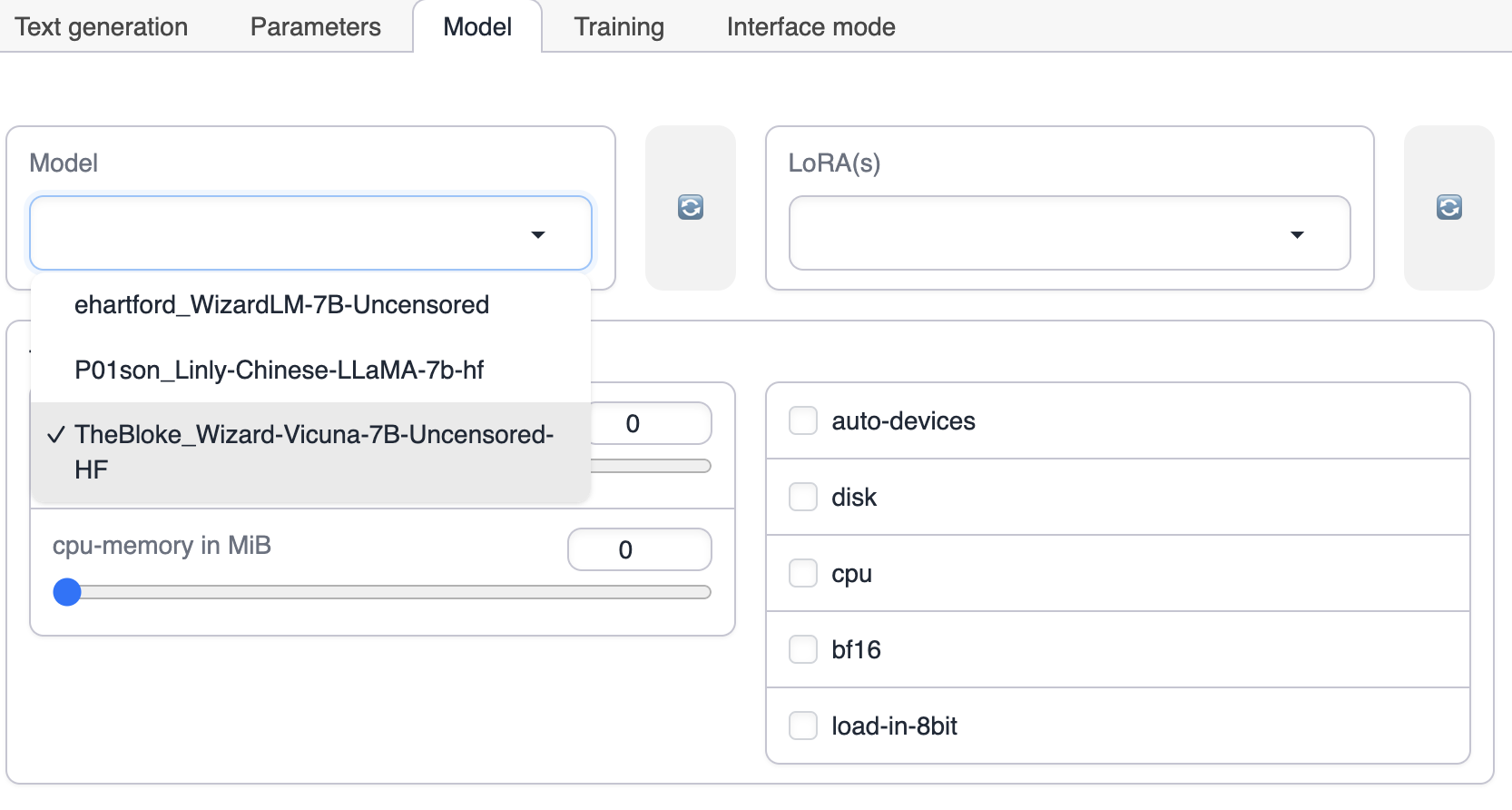
LoRAを選択します。LoRAの選択肢が表示されない場合は、右側の更新ボタンをクリックするか、text-generation-webuiのLoRAディレクトリにLoRAモデルが配置されているかどうかを確認してください。
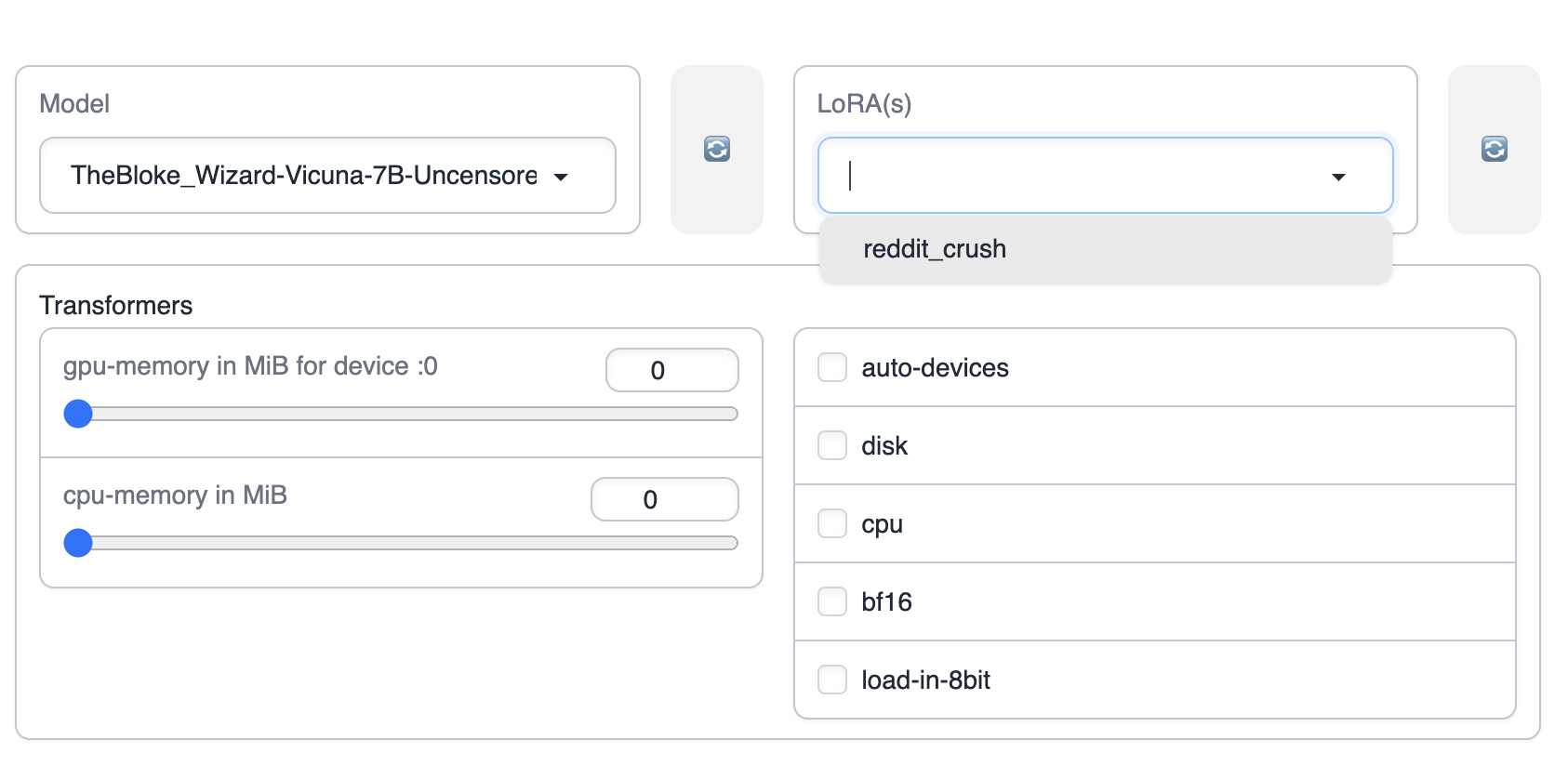
LoRAを適用し、選択したLoRAを適用するをクリックします。
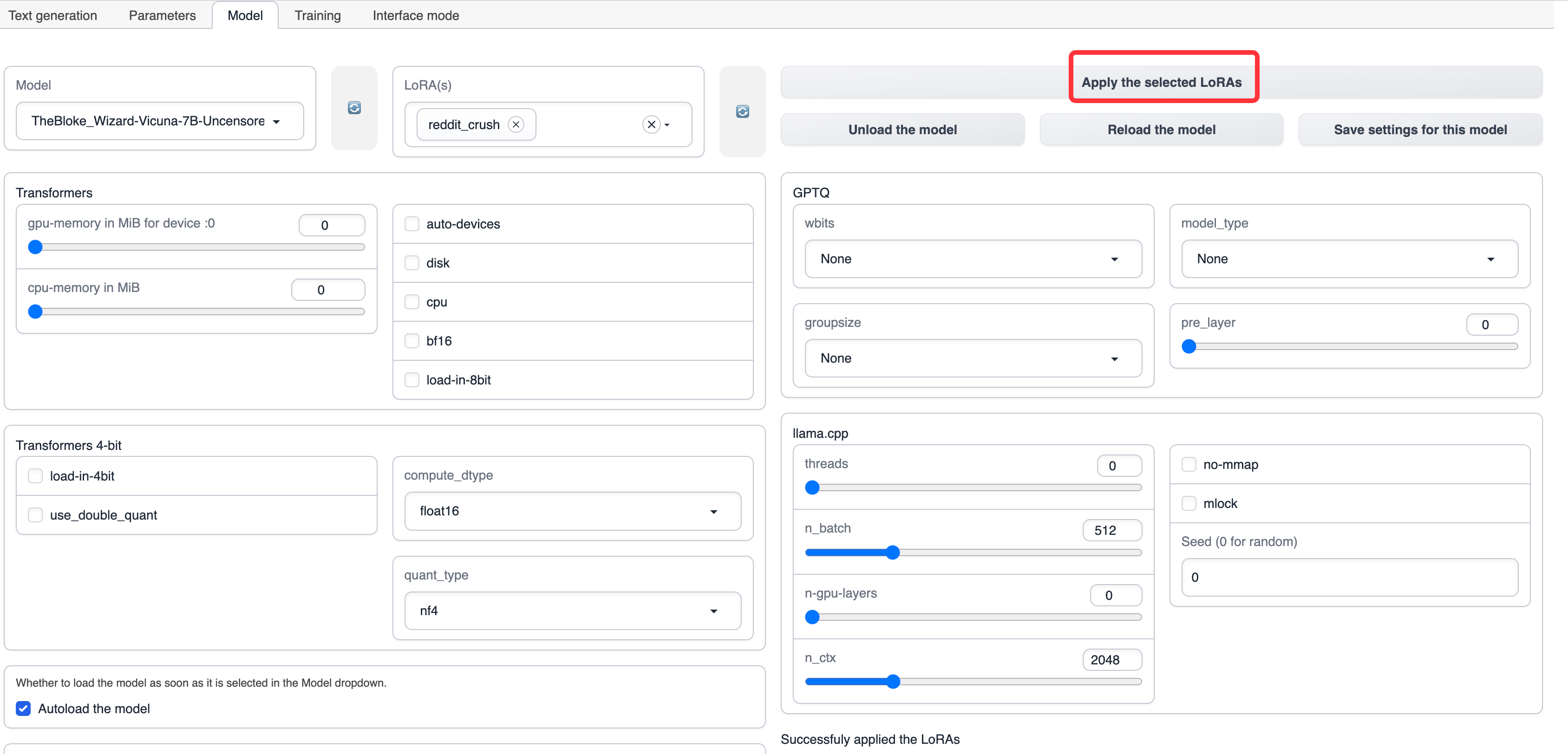
アプリケーションが成功したら、プロンプトが表示されます。
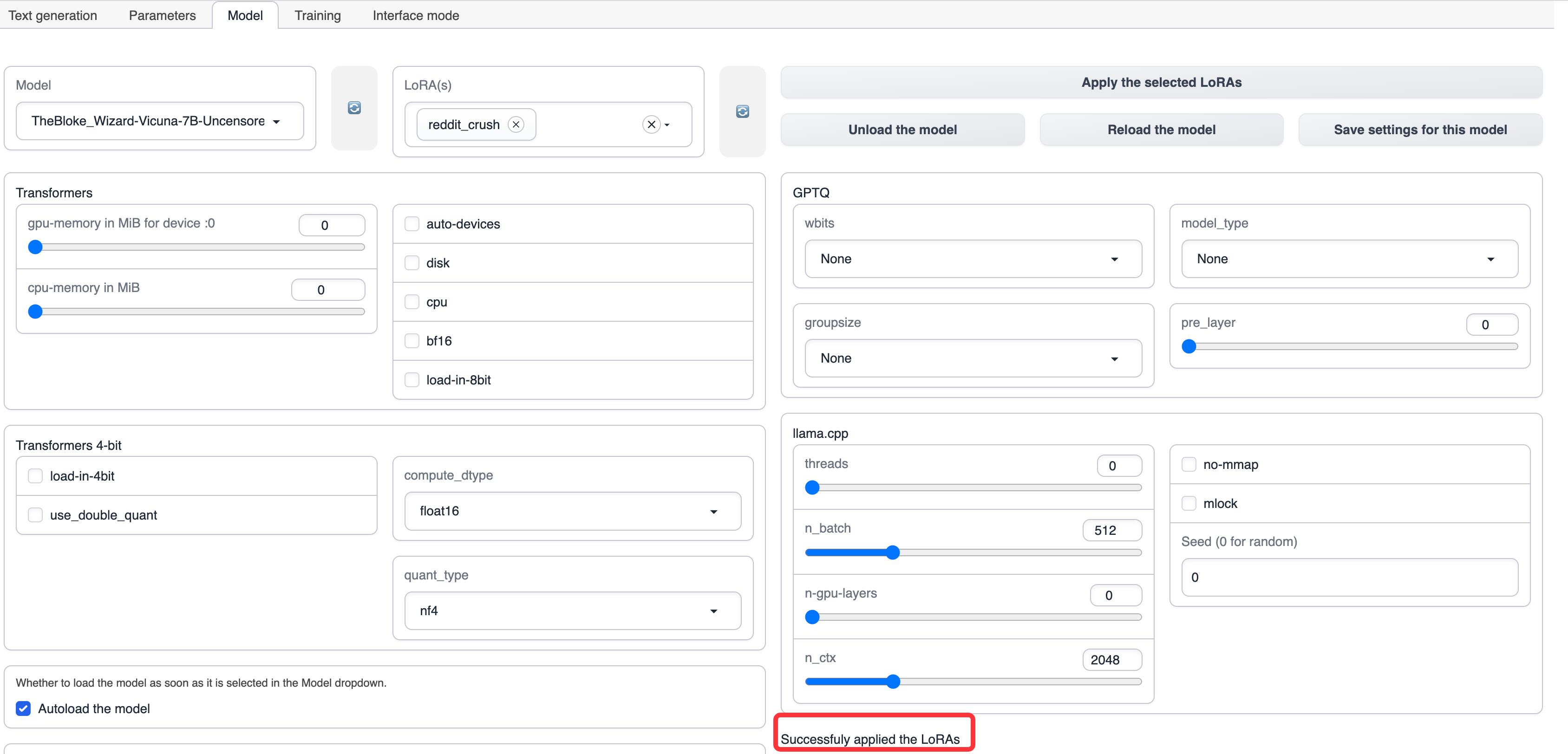
モデルを使用する
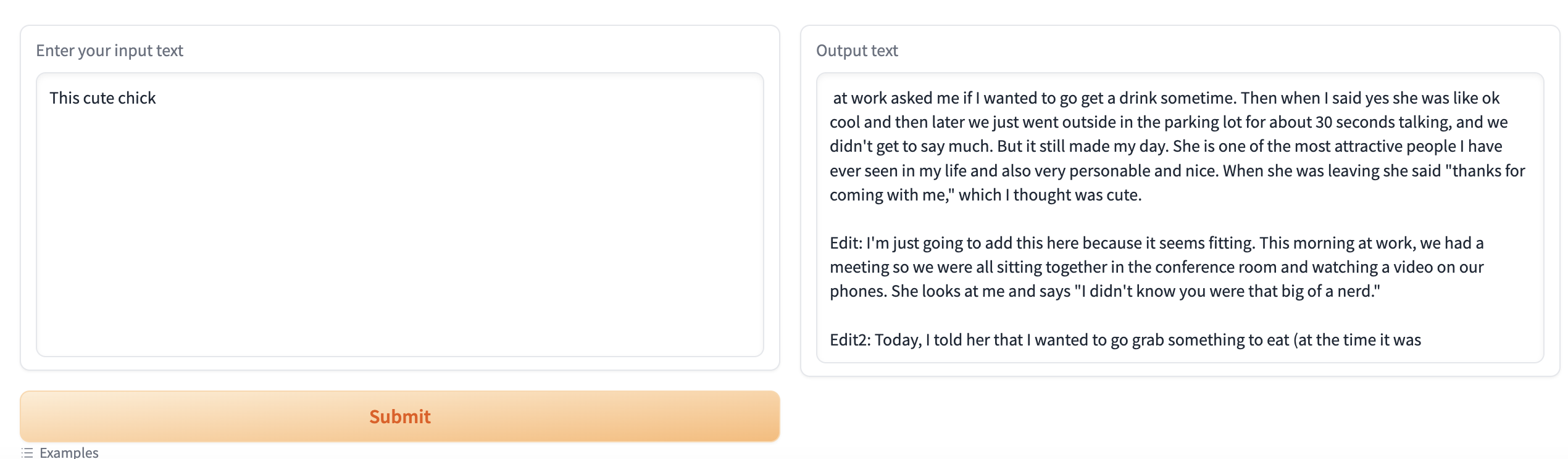
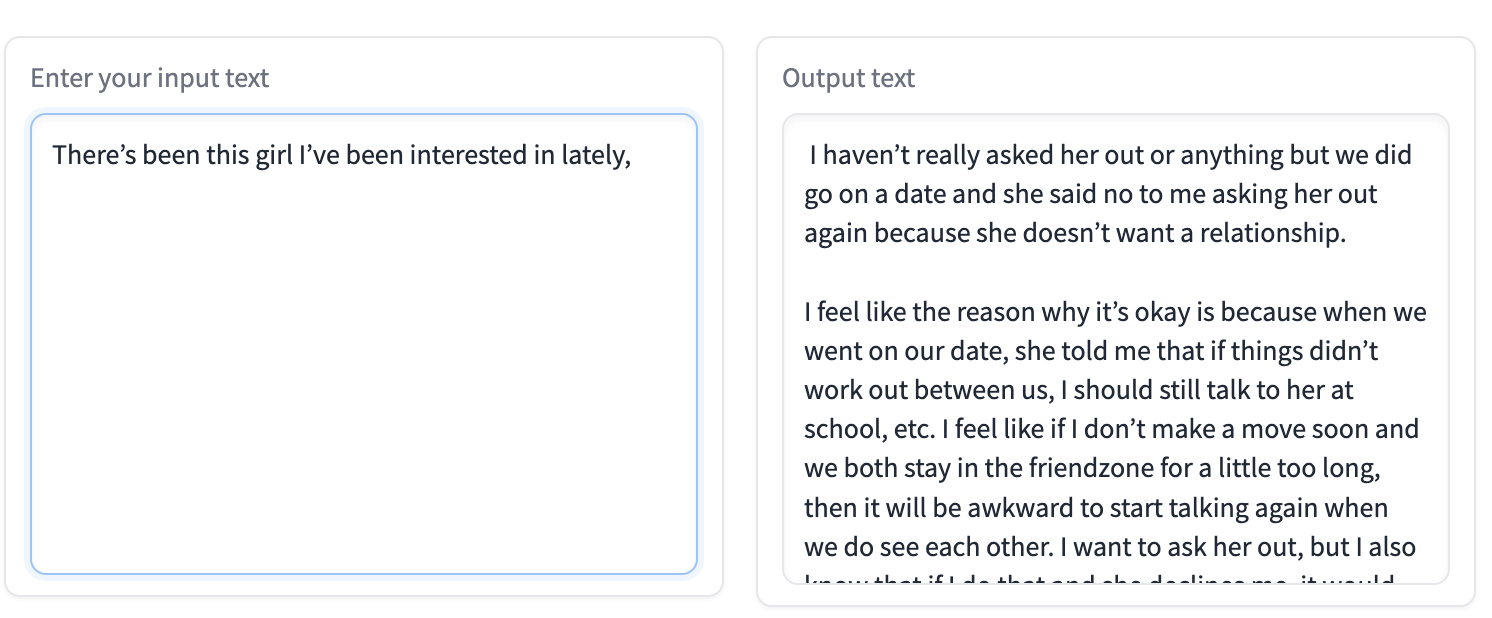
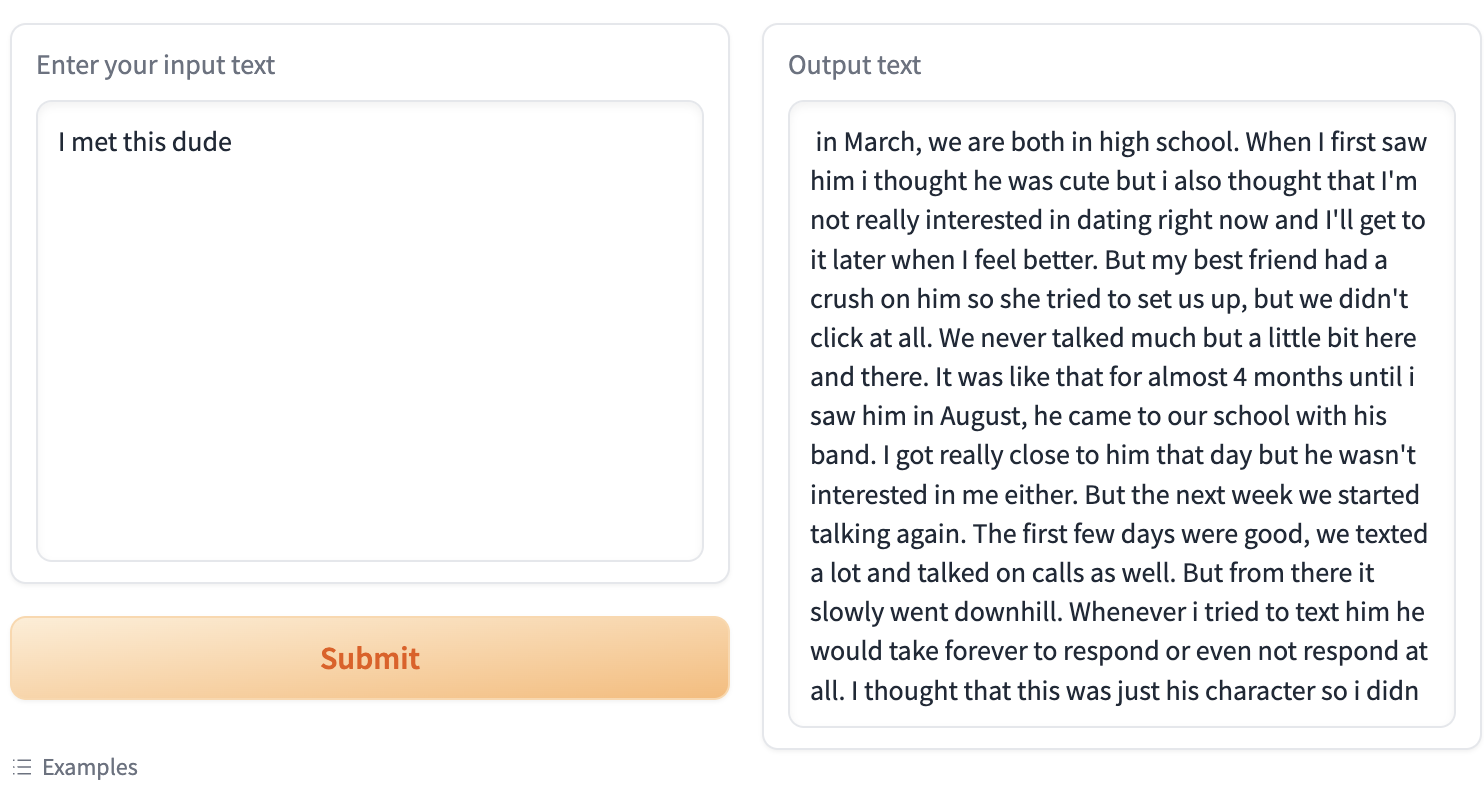
Text generationタブに切り替えて、物語の始まりを出力し、Generateをクリックすると、物語の続きが自動的に右側に生成されます。