Audio Generate
⚠️ Audio generation is currently in the exploration stage and the results are relatively poor.
Currently, in the field of audio generation, there are no mature products or paradigms. One product worth paying attention to is suno-ai/bark.
Traditional text-to-audio conversion is limited to text-to-speech. However, if we want to generate new music through text descriptions, text-to-speech technology cannot meet the demand.
Bark is a new model that explores how to generate audio through text descriptions in the audio field. Currently, Bark can generate multi-language speech and other audio, including music, background noise, and simple sound effects.
It uses a paradigm similar to Stable Diffusion: generate audio through text descriptions and specific grammar.
We will use an example to let you experience its functionality.
Advanced TTS
Open the online experience page. You can enter the text to be converted to speech in the input box on the left. The difference from ordinary text-to-speech technology is that Bark supports specific grammar and can add other sound effects to the speech. For example, laughter, knocking, sighing, etc.
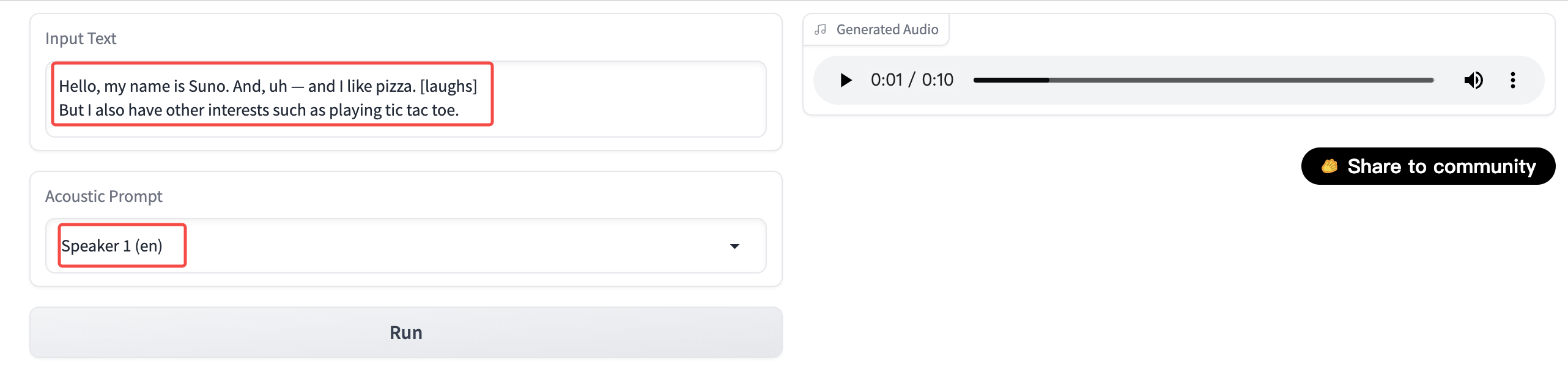
| Grammar | Effect | Example input | Note |
|---|---|---|---|
| [laughter] | Add laughter sound effect | Hello, my name is Suno. [laughter] | |
| [laughs] | Add laughter sound effect | Hello, my name is Suno. [laughs] | |
| [sighs] | Add sighing sound effect | It's so bad [sighs] | |
| ♪ xxxxx ♪ | Singing | ♪ It's not so long, And I'm not there ♪ | If using other Speakers is ineffective, please use Unconditional |
It should be noted that the speaker and the input text need to be of the same type.
Currently, the effect of Bark is relatively poor, and there is still some way to go before it can be truly applied. However, this paradigm of music generation through text description+DSL (specific grammar language) may be worth learning from.
We will continue to pay attention to this area, and if there are any updates or technological breakthroughs, we will follow up.