Reddit Crush Post
Reddit is the most popular community on the internet, organized into smaller topic groups called subreddits, each with various posts where users can reply.
We collected data from some Reddit Crush topics and fine-tuned them on the LLama model, creating a sample application for generating Reddit posts. (The online experience only supports one user at a time. If you can't use it, please try the simplified version.)
Generate Your First Reddit Crush Post
Please open the online experience page, enter the beginning of your story, such as "I meet."
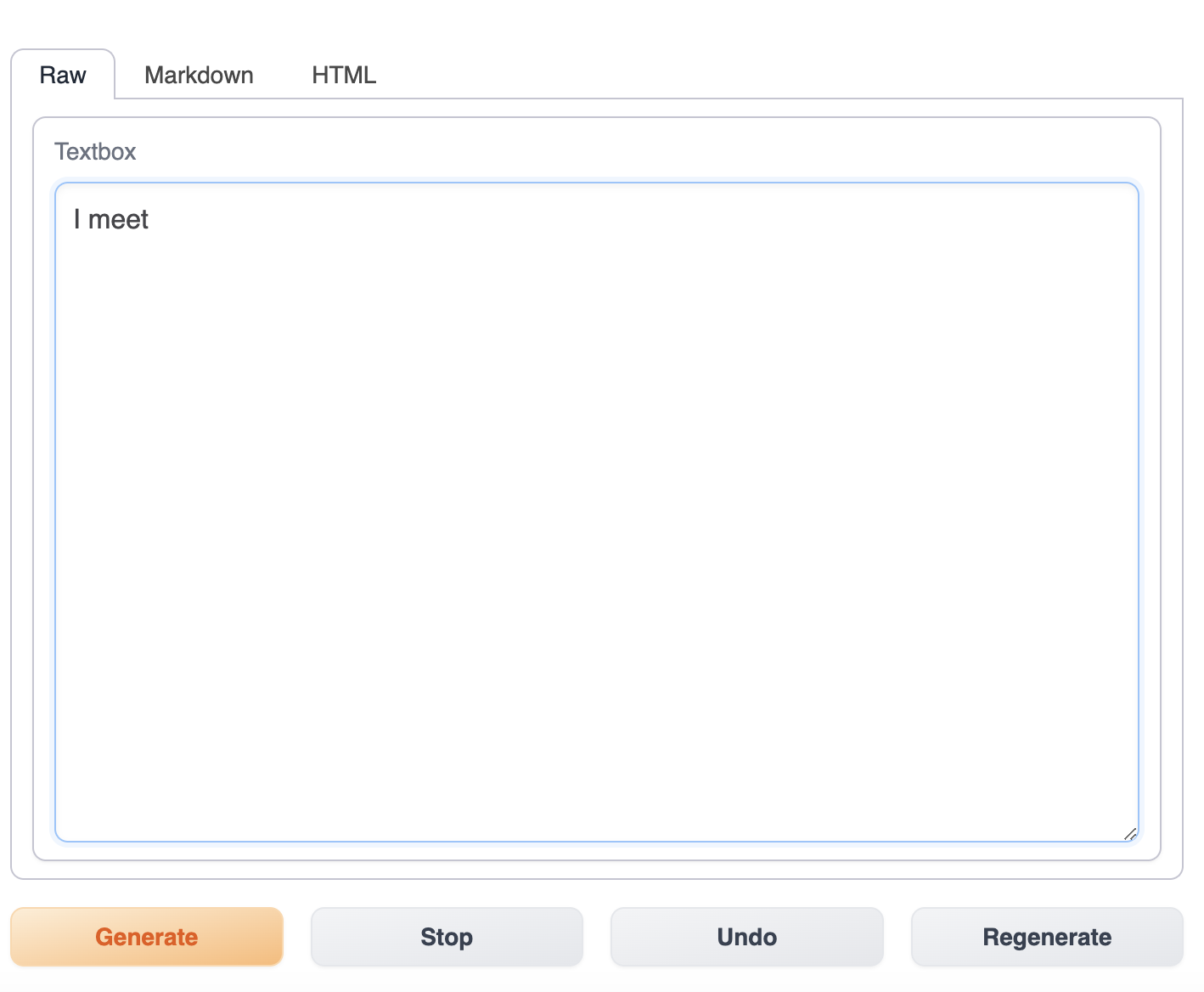
Then click Generate, and the model will automatically complete the rest of the story. If you're not satisfied with the plot, you can stop generating at any time, modify the story yourself, and continue generating.
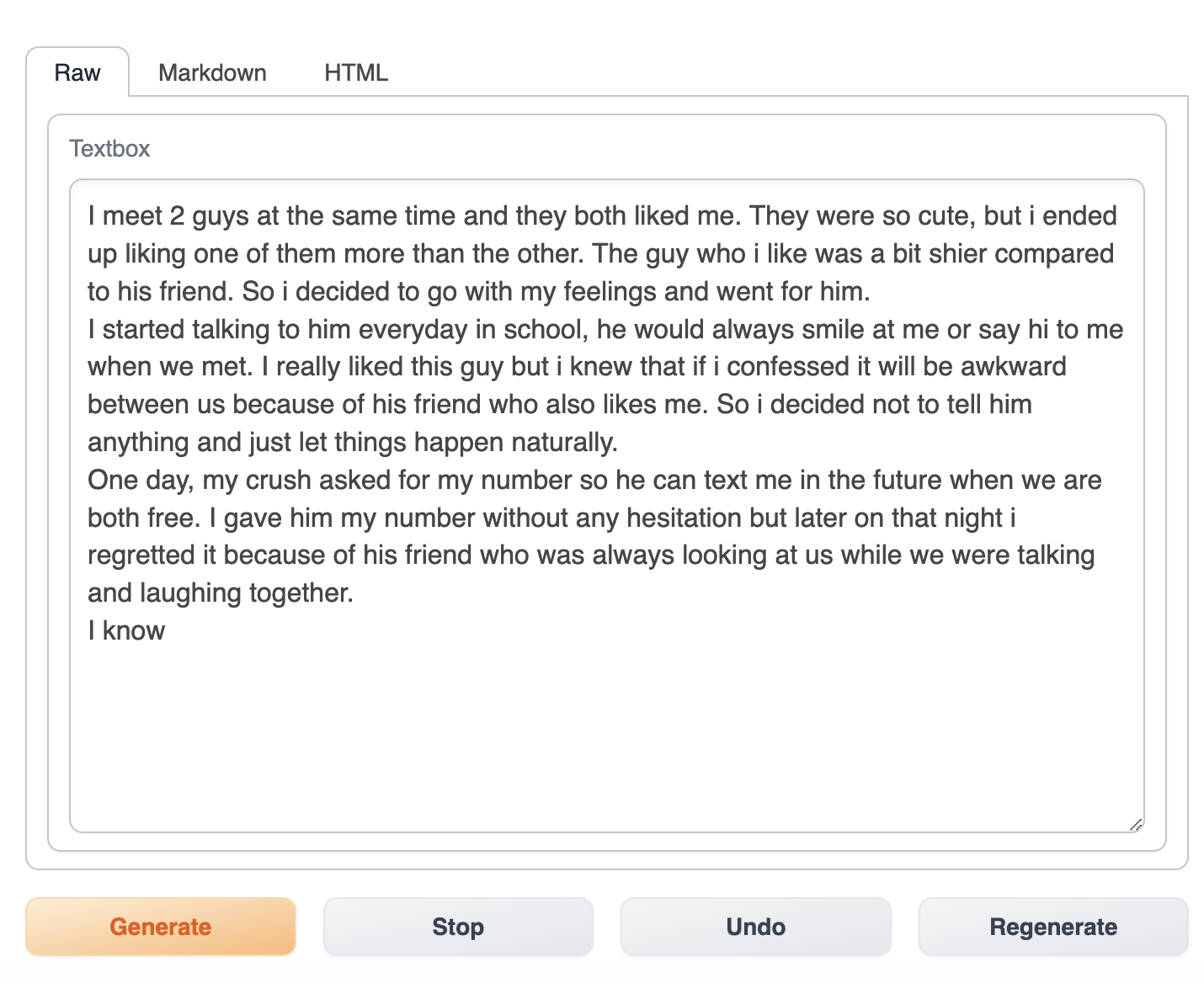
You can come up with whatever story beginnings you like, such as "yesterday" or "recently," and the model will complete the story for you.
Text Generation Process
Using this application as an example, let's experience the process of text generation.
The logic of text generation is relatively simple: input the beginning of your story, and the model will continue writing it. You can pause the generation at any time, modify the story, and then continue generating.
Text Generation
First, when generating text, we need to give an opening as input, such as "yesterday," "This cute chick," "..." and so on. Then click the Generate button below to start generating. If you need to stop generating, click the Stop button. Use the max_new_tokens on the far right to control the maximum length of the generated text.
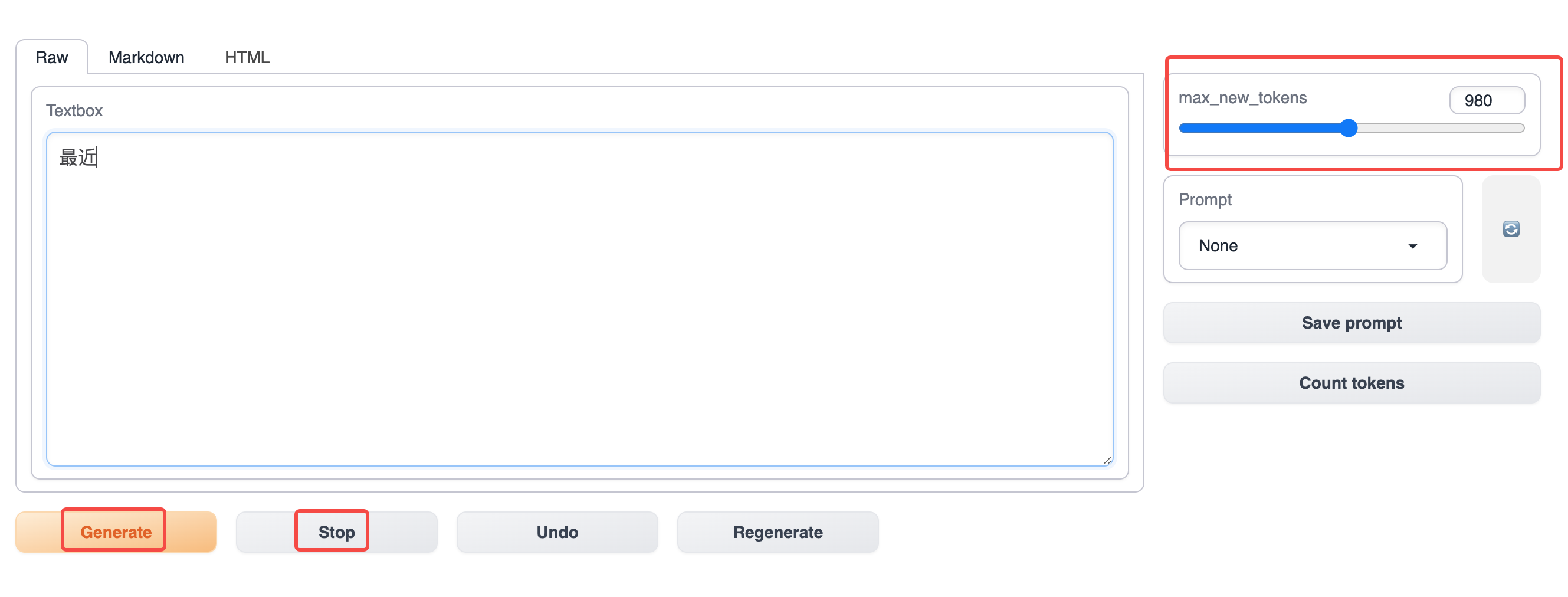
Parameter Adjustment
You can adjust the parameters to produce different results.
Switch to the Parameters tab.
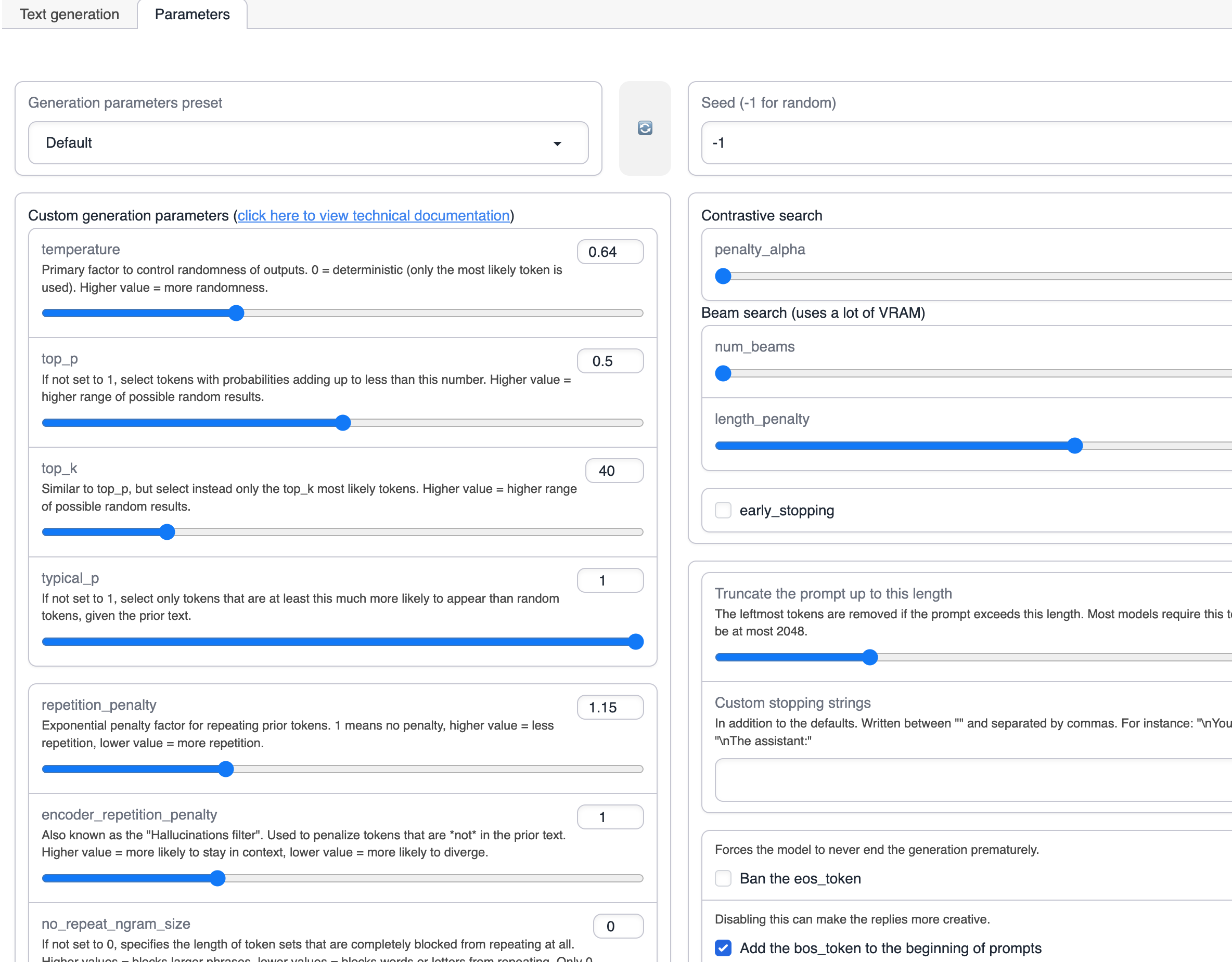
By adjusting these parameters, you can control the diversity of the generated text.
The specific meanings of the parameters are shown in the table below.
| Parameter | Function | Explanation |
|---|---|---|
| seed | Random seed | |
| temperature | Main factor controlling output randomness | 0 = determinism (only use the most likely token) Higher values = more randomness |
| Top-P | Factor controlling output randomness | If set to float<1, only the minimum set of probabilities that add up to Top-K or higher of the most likely tokens are retained for generation. Higher values = a wider range of possible random results. |
| Top-K | Factor controlling output randomness | Choose the next word from a list of the k most likely next words. If Top-K is set to 10, it will only choose from the 10 most likely possibilities. |
| typical_p | Factor controlling output randomness | When the "typical_p" parameter is set to a value less than 1, the algorithm selects tokens that appear more often than random tokens based on previous text content. This can be used to filter out some less common or irrelevant tokens and only select those that are more meaningful or relevant. When the "typical_p" parameter is set to 1, all tokens are selected regardless of their relative probability with random tokens. |
| repetition_penalty | Parameter controlling output repetition | 1 means no penalty Higher values = less repetition Lower values = more repetition |
| encoder_repetition_penalty | Affects the coherence between the generated text and previous text | 1.0 means no penalty Higher values indicate a greater tendency to stay in context related to previous text; Lower values make it easier to deviate from context related to previous text. |
| no_repeat_ngram_size | Controls whether repeated fragments are allowed in the generated text | Higher values prevent longer phrases from appearing repeatedly in the generated text, making the generated text more diverse. Lower values prevent repetition of words or letters, making the generated text more unique. |
| min_length | Minimum length of generated text |