Overview of AIGC Models
The core of AIGC technology is various deep learning models.
A deep learning model is a complex structure composed of a network structure and parameters.
Here, we will not go into too much technical explanation of the model. For users, the model can be treated as a black box. Users input something (such as text input), and the model outputs content in a certain form (such as images and text related to the input).
From the perspective of ordinary users, the model is a file downloaded from the Internet, usually ending in .pt, .safetensor, or .checkpoint.
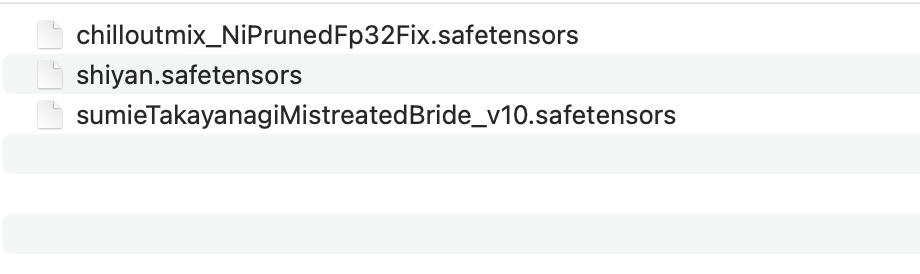
The model cannot be directly double-clicked to execute like ordinary software. It needs to be loaded by other software to be used. Usually, we have a workstation software to load and use the model, such as:
- Workstation for image generation stable-diffusion-webui
- Workstation for text generation text-generation-webui
Users download various models to their local computers, place them in the directory specified by the workstation software, and then start the workstation.
In the workstation, users can specify to use a certain model. The software will load the selected model file. After loading, a specific model can be used.
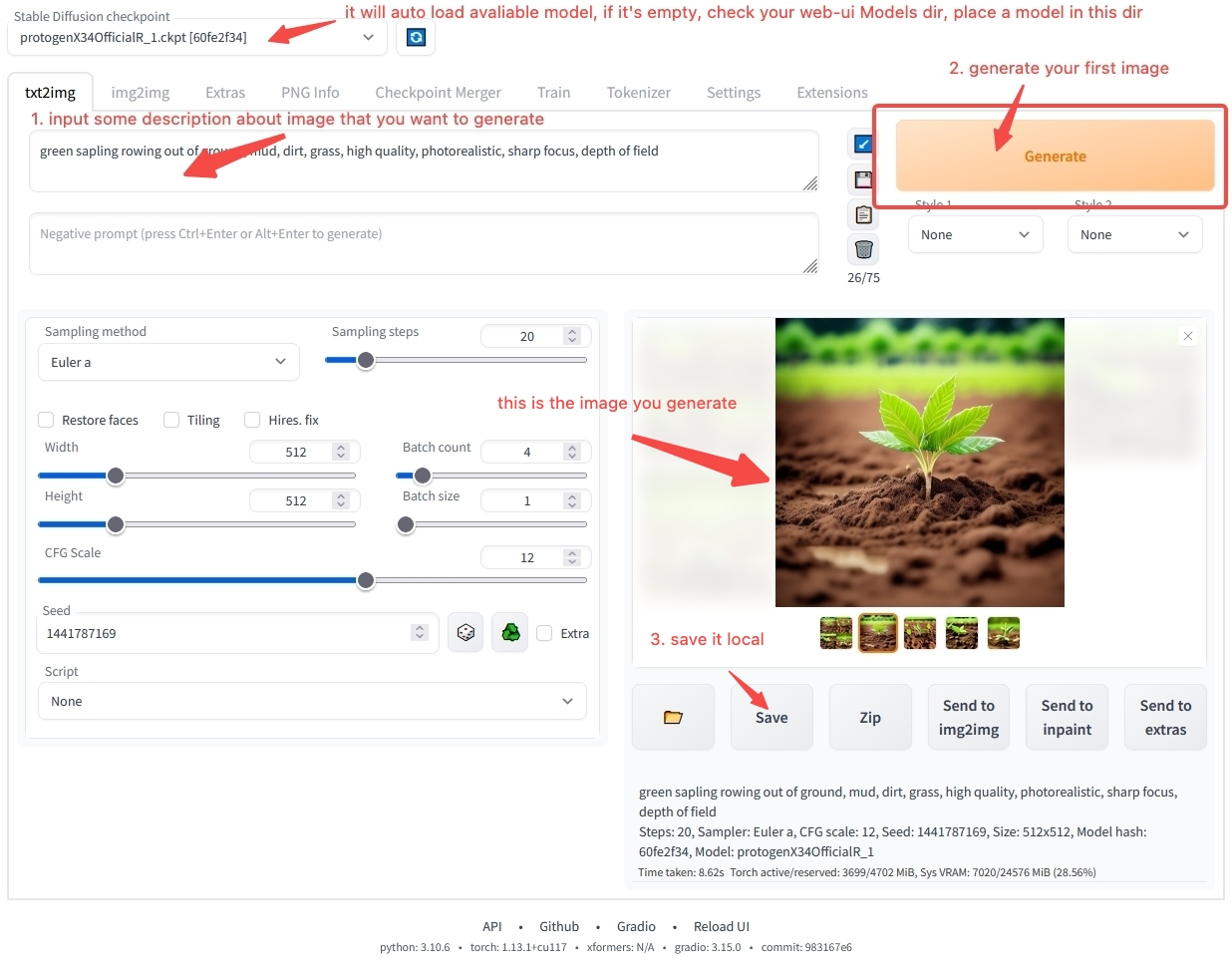
You may still have many doubts about how to use the workstation software. Don't worry, in the Model Usage Overview chapter, we will guide you step by step to install and operate the software. If you can't wait to generate your first AI art, you can jump directly to Quick Start and start with our online environment to quickly get started. If you want to learn more about model-related content, let's continue.
Model Classification
You may have heard of various model names such as Stable Diffusion, ChilloutMix, and KoreanDollLikeness on the Internet. Why are there so many models? What are their differences?
From the perspective of users, models can be divided into basic models, full-parameter fine-tuning models, and lightweight fine-tuning models.
| Category | Function | Introduction | Example |
|---|---|---|---|
| Basic model | Can be directly used for content generation | Usually a model with a new network structure released by research institutions/technology companies | Stable Diffusion 1.5, Stable Diffusion 2.1 |
| Full-parameter fine-tuning model | Can be directly used for content generation | A new model obtained by fine-tuning the basic model on specific data, with the same structure as the original basic model but different parameters | ChilloutMix |
| Lightweight fine-tuning model | Cannot be directly used for content generation | The model is fine-tuned using lightweight fine-tuning methods | KoreanDollLikeness, JapaneseDollLikeness |
Fine-tuning refers to retraining the basic model on specific data to obtain a fine-tuned model. The fine-tuned model performs better than the original basic model in specific scenarios.
Image Models
Taking image content models as an example, almost all models currently on the market are derived from the Stable Diffusion series of models. Stable Diffusion is an open-source image content generation model released by stability.ai. From August 2022 to now, four versions have been released.
- Stable Diffusion
- Stable Diffusion 1.5
- Stable Diffusion 2.0
- Stable Diffusion 2.1
Currently, most of the mainstream derived models in the community are based on Stable Diffusion 1.5 for fine-tuning.
In the field of image generation, Stable Diffusion series models have become the de facto standard.
Text Models
In the field of text, there is currently no unified standard. With the release of ChatGPT in November, some research institutions and companies have released their own fine-tuned models, each with its own characteristics. Among them, the more famous ones include LLaMA released by Meta and StableLM released by stability.ai.
Currently, there are several core issues in text content generation:
- Short dialogue context length, if the text for dialogue with the model is too long, the model will forget the previous content. Currently, only RWKV can achieve long context due to the large difference in model structure with other models. Most text models are currently based on transformer structures, and the context is often short.
- Models are too large, the larger the model, the more parameters, and the more computing resources required for content generation.
Audio Models
In the field of audio, there are some peculiarities. For a single audio content, it can be divided into three categories: voice actor voice, sound, and music.
- Voice: Traditionally, speech technology usually uses text-to-speech (TTS) technology for generation, lacking artistic imagination. Currently, there are few people paying attention to it, and there is no mature open-source tool for data->model, model->content paradigm.
- Music🎵: Music is a more imaginative field. As early as 16 years ago, commercial companies began to provide AI models to generate music. With the popularity of Stable Diffusion, some developers have also proposed using Stable Diffusion to generate music, such as Riffusion. However, the current effect is not amazing enough. In October 2022, Google released AudioLDM, which can continue writing after a music segment. In April 2023, suno.ai released the bark model. The music field is still in the development stage. Perhaps after half a year to a year of development, it will also break through the critical point of application like the image field.
- Sound: For simple sounds, such as knocking on a door and the sound of waves, they are relatively easy to generate. Existing AudioLDM and bark can generate simple sounds.
Video Models
Currently, video models are still in the early stages of development. Compared with images, videos have contextual information, and the resources required for video generation are often much more than those for images. When the technology is not mature enough, it often wastes computing resources to generate low-quality content. At present, there are no relatively mature video generation software for ordinary users. Therefore, we do not recommend that ordinary users try to generate videos by themselves. If you still want to experience video generation, you can use the online services provided by RunwayML to try it out.
3D Content Models
In modern 3D games, a large number of 3D model resources are often required. In addition, we can use 3D printing technology to print 3D models into real-world art objects.
In the field of 3D content generation, the demand is relatively small, and there is currently no complete paradigm. Some projects that can be used as references include:
Currently, 3D content generation technology is close to the application critical point on some saas services. However, there is no open-source product with relatively high quality yet.
Other Models
In addition to models that generate basic content, there are also models that may integrate multiple modalities and can understand and generate multiple modal content. Currently, this part of the technology is in the development stage.
Some projects that can be used as references include: