Génération audio
⚠️ La génération audio est actuellement à l'étape d'exploration et les résultats sont relativement médiocres.
Actuellement, dans le domaine de la génération audio, il n'y a pas de produits ou de paradigmes matures. Un produit qui mérite d'être suivi est suno-ai/bark.
La conversion traditionnelle de texte en audio se limite à la synthèse de la parole. Cependant, si nous voulons générer de la nouvelle musique à partir de descriptions textuelles, la technologie de synthèse de la parole ne peut pas répondre à la demande.
Bark est un nouveau modèle qui explore comment générer de l'audio à partir de descriptions textuelles dans le domaine de l'audio. Actuellement, Bark peut générer de la parole multilingue et d'autres types d'audio, y compris de la musique, du bruit de fond et des effets sonores simples.
Il utilise un paradigme similaire à Stable Diffusion : générer de l'audio à partir de descriptions textuelles et d'une grammaire spécifique.
Nous allons utiliser un exemple pour vous faire découvrir sa fonctionnalité.
TTS avancé
Ouvrez la page expérience en ligne. Vous pouvez entrer le texte à convertir en parole dans la zone de saisie à gauche. La différence avec la technologie de synthèse de la parole ordinaire est que Bark prend en charge une grammaire spécifique et peut ajouter d'autres effets sonores à la parole. Par exemple, le rire, les coups, le soupir, etc.
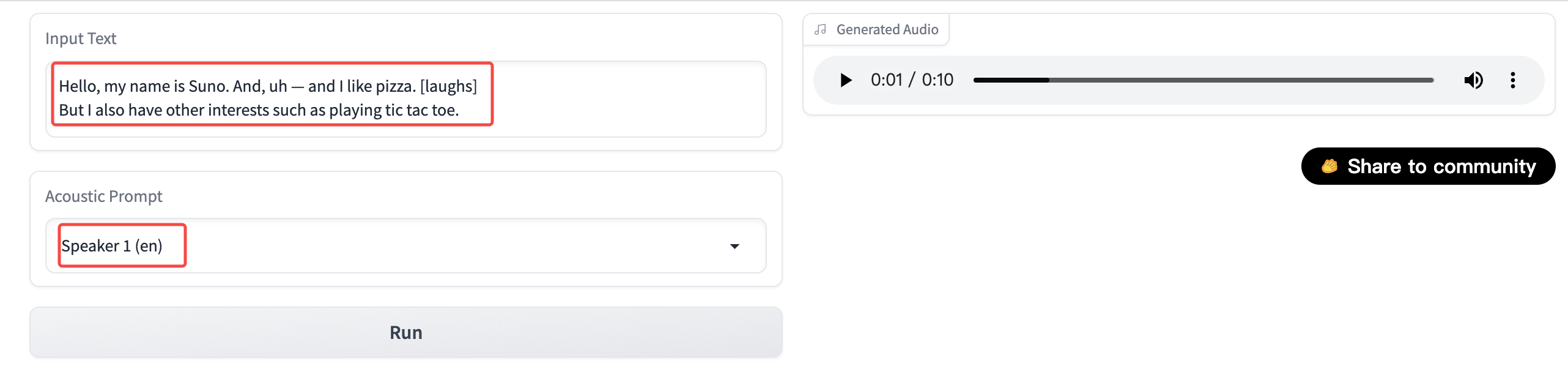
| Grammaire | Effet | Exemple d'entrée | Note |
|---|---|---|---|
| [rire] | Ajouter un effet sonore de rire | Bonjour, je m'appelle Suno. [rire] | |
| [rires] | Ajouter un effet sonore de rire | Bonjour, je m'appelle Suno. [rires] | |
| [soupirs] | Ajouter un effet sonore de soupir | C'est tellement mauvais [soupirs] | |
| ♪ xxxxx ♪ | Chanter | ♪ Ce n'est pas si long, et je ne suis pas là ♪ | Si l'utilisation d'autres haut-parleurs est inefficace, veuillez utiliser Inconditionnel |
Il convient de noter que le haut-parleur et le texte d'entrée doivent être du même type.
Actuellement, l'effet de Bark est relativement médiocre, et il reste encore du chemin à parcourir avant qu'il puisse être réellement appliqué. Cependant, ce paradigme de génération de musique par description textuelle+DSL (langage de grammaire spécifique) peut valoir la peine d'être appris.
Nous continuerons à surveiller ce domaine, et s'il y a des mises à jour ou des percées technologiques, nous ferons un suivi.