Audio Generate
⚠️ 音频生成目前还处于探索阶段,效果比较差
目前,在音频生成领域,暂无较为成熟的产品和范式,一个值得关注的产品是 suno-ai/bark
传统的文字和音频转换,局限于文字转语音。但是,如果我们希望通过文字描述,生成新的音乐,文字转语音技术就无法满足需求了
bark 是一个新的模型,探索如何在音频领域,通过文字描述生成音频,目前 bark 可以生成多语言语音以及其他音频,包括音乐、背景噪音和简单的音效
它使用一种类似于 Stable Diffusion 的范式:通过文字描述和特定的语法生成音频
我们会使用一个样例来带您体验它的功能
高级TTS
打开在线体验的页面,你可以在左边的输入框内,输入要被转为语音的文字,和普通文字转语音技术的不同之处在于,bark 支持特定的语法,可以在语音中加入其他音效。例如人物的笑声,敲门声,叹气声等等
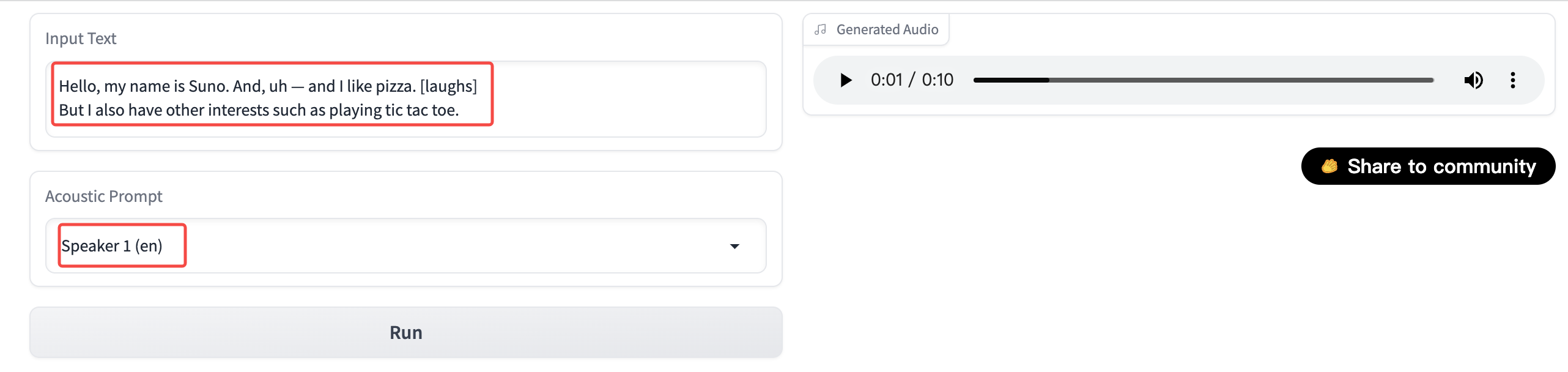
| 语法 | 效果 | 样例输入 | 备注 |
|---|---|---|---|
| [laughter] | 添加笑声音效 | Hello, my name is Suno. [laughter] | |
| [laughs] | 添加笑声音效 | Hello, my name is Suno. [laughs] | |
| [sighs] | 添加叹气音效 | It's so bad [sighs] | |
| ♪ xxxxx ♪ | 唱歌 | ♪ It's not so long, And I'm not there ♪ | 如果使用其他的Speaker 无效,请使用Unconditional |
需要注意的是,Speaker 和输入的文字需要是同一类型
目前 bark 的效果相对较差,距离真正应用还有一段的空间,不过这种通过文字描述+DSL(特定语法的语言)进行音乐生成的范式或许能够被借鉴
我们会持续关注这块,如果有更新的技术突破的话,我们会进行跟进