オーディオ生成
⚠️ オーディオ生成は現在探索段階にあり、結果は比較的悪いです。
現在、オーディオ生成の分野では、成熟した製品やパラダイムはありません。注目すべき製品の1つは、suno-ai/barkです。
従来のテキストから音声への変換は、テキスト読み上げに限定されています。しかし、テキストの説明から新しい音楽を生成したい場合、テキスト読み上げ技術では需要に応えることができません。
Barkは、オーディオ分野のテキスト説明からオーディオを生成する方法を探る新しいモデルです。現在、Barkは、多言語音声や音楽、背景音、簡単な効果音など、他のオーディオも生成することができます。
それは、Stable Diffusionに似たパラダイムを使用しています:テキスト説明と特定の文法を通じてオーディオを生成する。
その機能を体験するための例を使用します。
高度なTTS
オンライン体験ページを開きます。左側の入力ボックスに変換するテキストを入力できます。通常のテキスト読み上げ技術との違いは、Barkは特定の文法をサポートし、音声に他の効果音を追加することができることです。例えば、笑い声、ノック音、ため息などです。
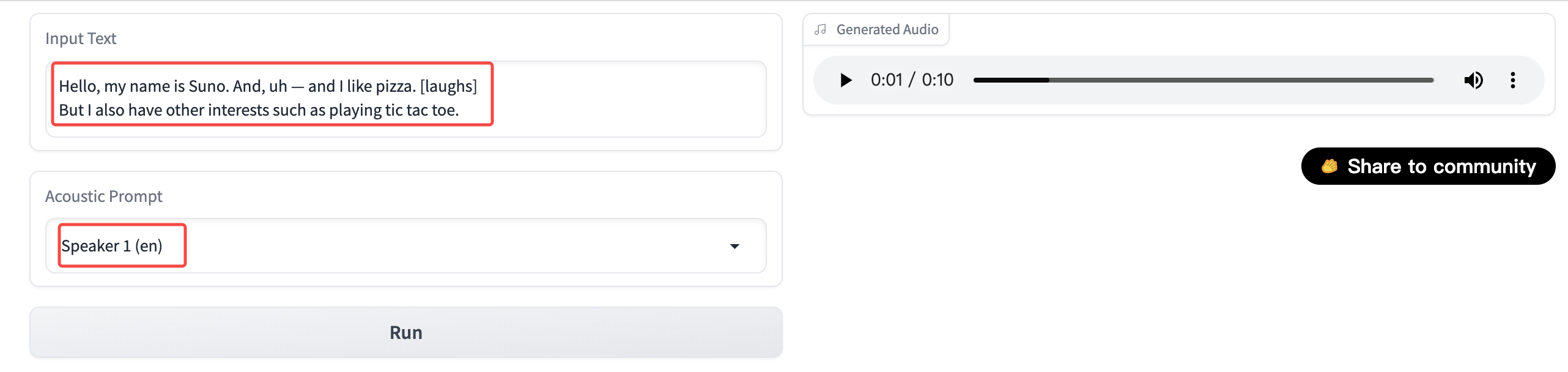
| 文法 | 効果 | 例 | 注記 |
|---|---|---|---|
| [laughter] | 笑い声の効果音を追加 | こんにちは、私の名前はSunoです。[laughter] | |
| [laughs] | 笑い声の効果音を追加 | こんにちは、私の名前はSunoです。[laughs] | |
| [sighs] | ため息の効果音を追加 | とても悪いです[sighs] | |
| ♪ xxxxx ♪ | 歌唱 | ♪ それほど長くない、私はそこにいない ♪ | 他のスピーカーを使用しても効果がない場合は、無条件で使用してください |
スピーカーと入力テキストは同じタイプである必要があることに注意してください。
現在、Barkの効果は比較的悪いです。本当に適用できるようになるには、まだ多くの改善が必要です。しかし、このテキスト説明+DSL(特定の文法言語)による音楽生成のパラダイムは、学ぶ価値があるかもしれません。
私たちはこの分野に引き続き注目し、更新や技術的な突破口があれば、追跡していきます。