Dcard Emotion Post 中文
无论时代如何变迁,八卦和情感类话题永远扮演着人们生活中不可或缺的角色
Dcard 是一个台湾的流行社区,由板块和帖子组成,Dcard分为”情感”,”美妆”,“心情”等各种板块,每个板块组内有各种各样的帖子,用户可以在帖子里进行回复
我们采集了一些Dcard论坛的数据,然后在 LLama 模型上进行了微调,构建了一个生成 Dcard Post的样例应用(当前在线体验同一时刻只支持一个人使用,如果无法使用,请使用简化版进行体验)
生成你的第一个 Dcard 情感贴
请打开在线体验页面,输入故事的开头,例如 “女友生气”
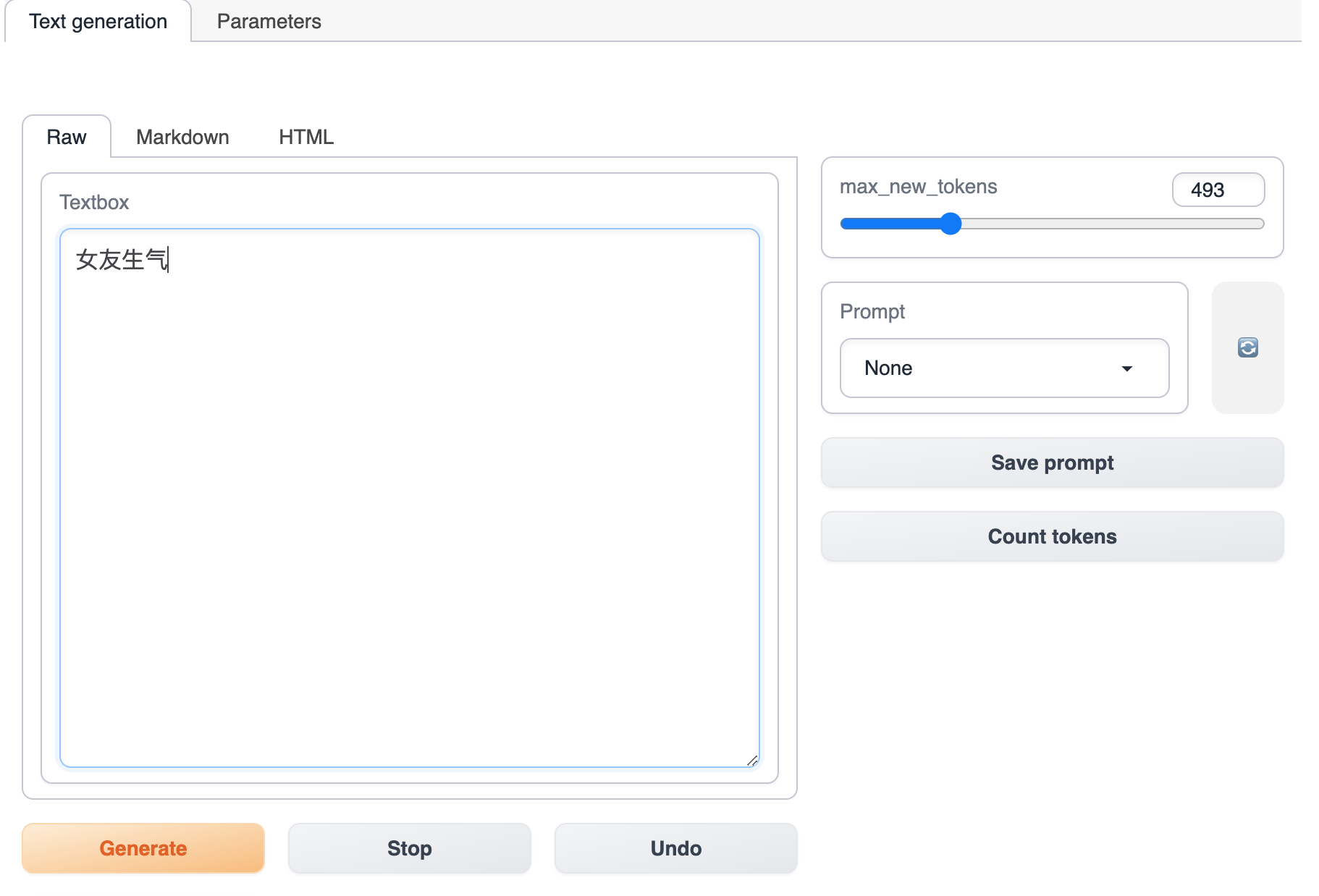
然后点击 Generate ,模型将会自动补全后续的故事,如果你对于故事的剧情不满意,你可以随时停止生成,然后自己修改故事,再继续进行生成
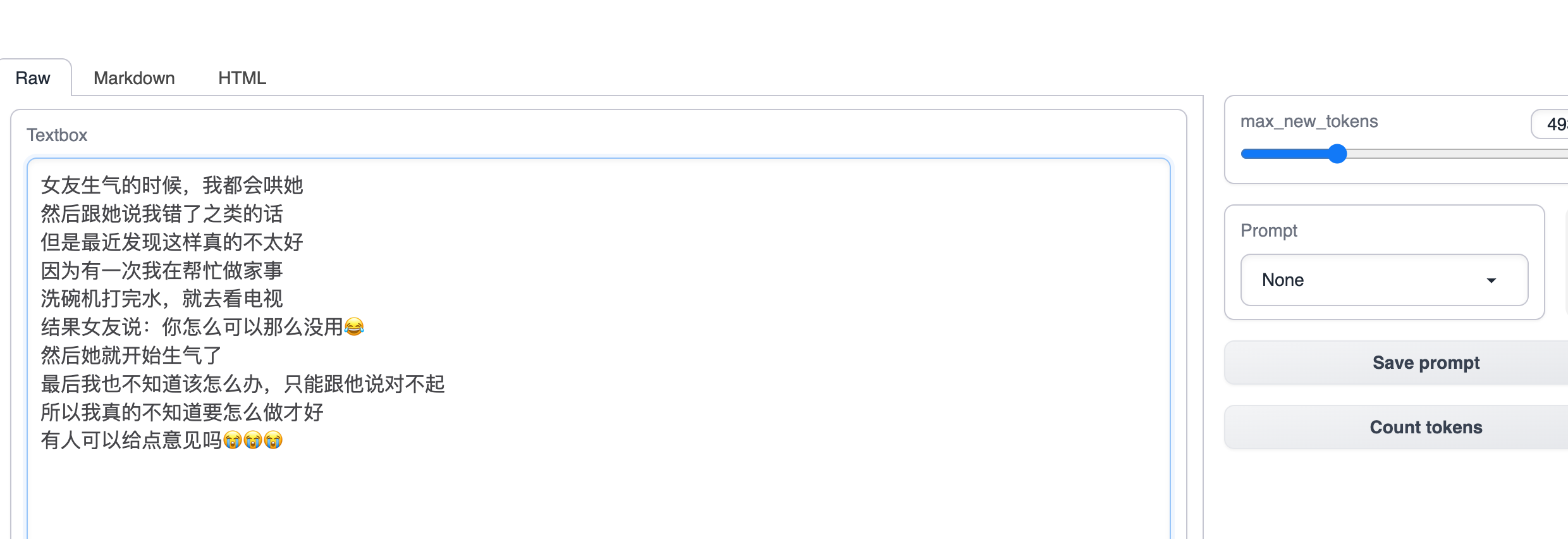
你可以自己随便想一些故事的开头,例如“停电了,男友”,“昨天”,“最近学校有一些流言”,等等,模型会为你进行故事的补充
生成文字的流程
以这个应用为例,我们来简单体验一下文字生成的流程
文字生成的逻辑相对简单,输入故事的开头,模型续写故事,同时,你可以随时暂停生成,修改故事,然后让模型继续生成
文字生成
首先在生成文字的时候,我们需要给一个开头作为输入,”男友”, “女友”, “最近”, “…”等等,然后点击下面的 Generate 按钮开始生成,如果你需要停止生成,点击 Stop 按钮,通过最右边的 max_new_tokens 控制最长生成长度
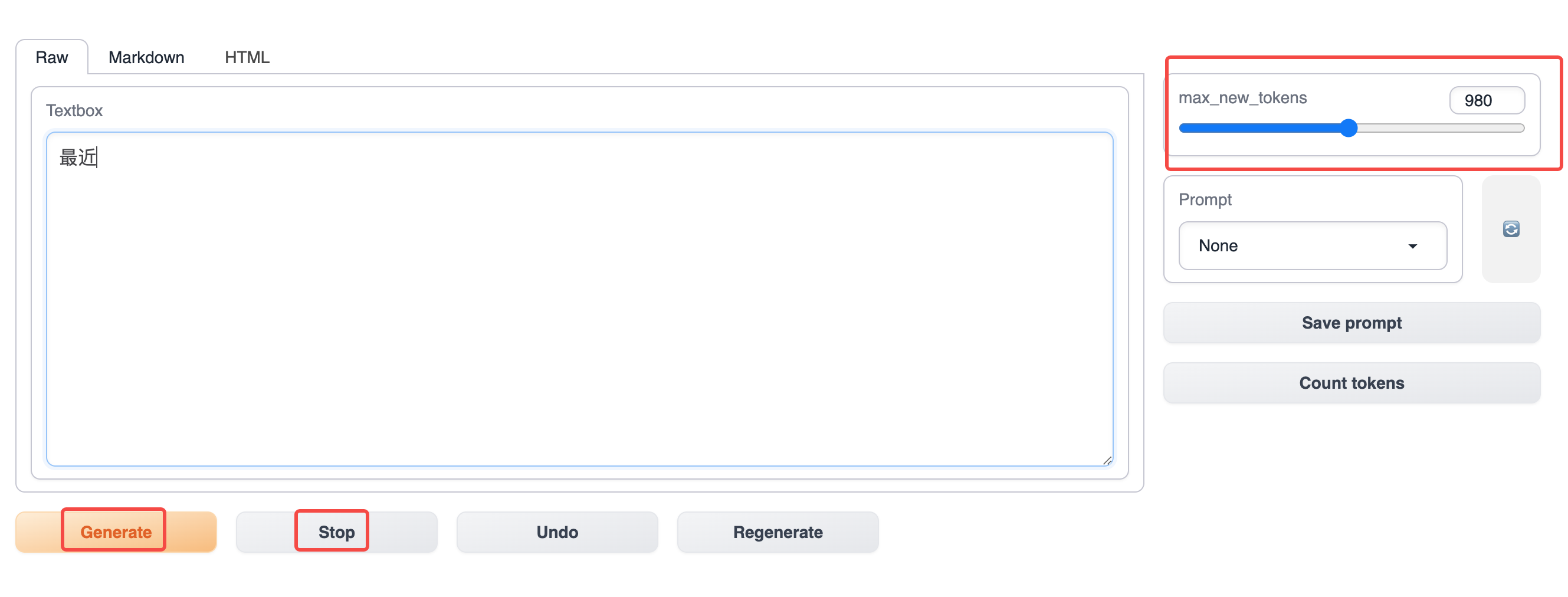
参数调整
你可以调整参数来让模型生成的结果出现不同的差异
切换到 Parameters 选项卡
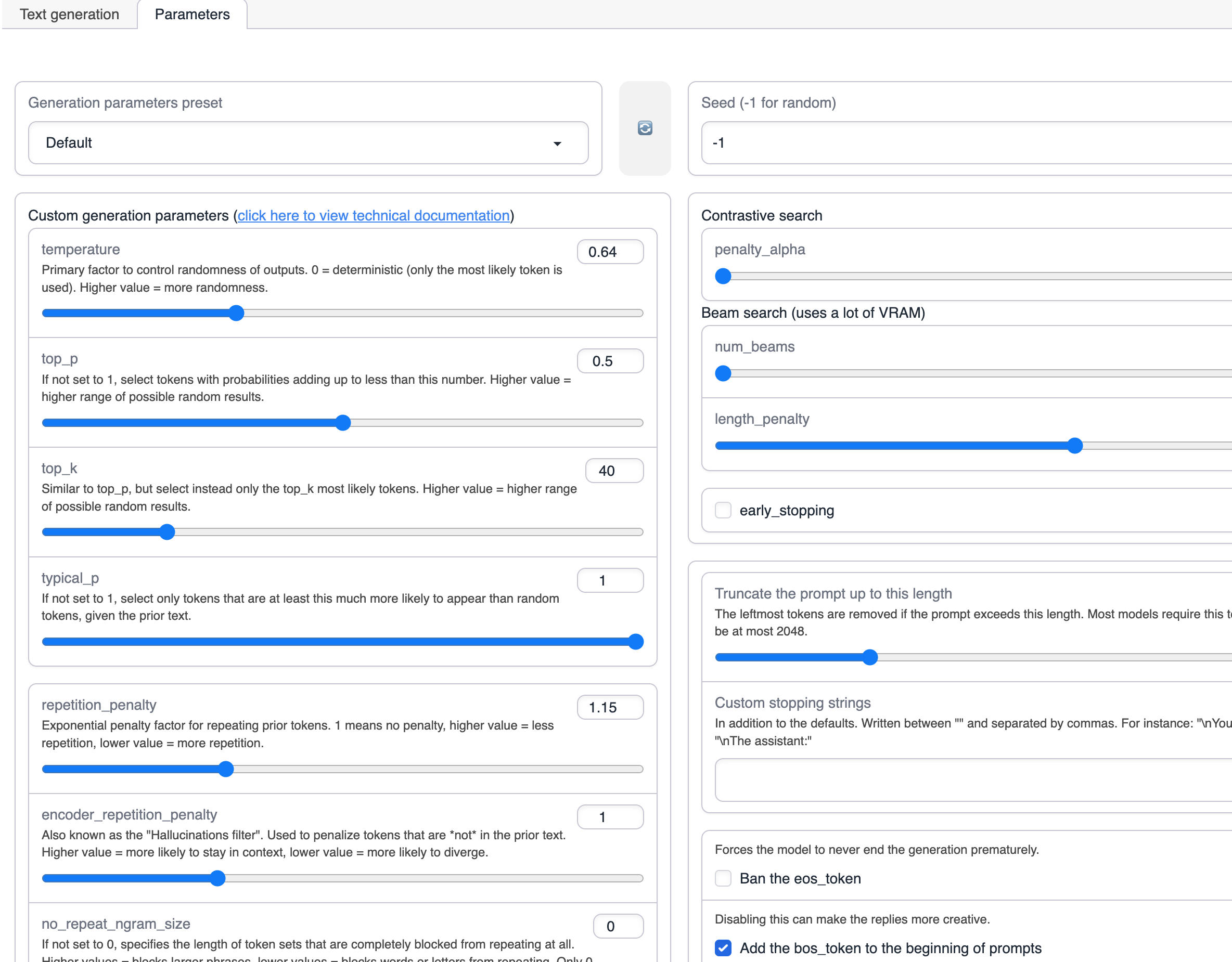
通过调整这些参数,你可以控制生成文字的多样性
参数的具体含义见下表
| 参数 | 功能 | 解释 |
|---|---|---|
| seed | 随机种子 | |
| temperature | 控制输出随机性的主要因素 | 0 = 确定性 (仅使用最有可能的标记) 更高的值 = 更多的随机性 |
| Top-P | 控制输出随机性的的因素 | 如果设置为 float<1 , 则只有概率加起来等于Top-K 或更高的最可能标记的最小集合被保留用于生成 更高的值 = 更大范围的可能随机结果。 |
| Top-K | 控制输出随机性的的因素 | 从k个最有可能的下一个单词列表中选择下一个单词。如果 Top-K 设置为 10,它只会从 10 个最有可能的可能性中挑选。 |
| typical_p | 控制输出随机性的的因素 | 当"typical_p"参数设置为一个小于1的值时,算法会根据先前的文本内容,选择那些在出现概率上超过随机标记的标记。这可以用来过滤掉一些不太常见或不相关的标记,只选择那些更有意义或更相关的标记。而当"typical_p"参数设置为1时,将选择所有的标记,不考虑它们与随机标记的相对概率。 |
| repetition_penalty | 控制输出重复度的参数 | 1 表示没有惩罚 更高的值 = 更少的重复 更低的值 = 更多的重复 |
| encoder_repetition_penalty | 影响模型生成的文本与先前文本之间的连贯性 | 1.0 意味着没有惩罚 取值越高,表示更倾向于保持在与先前文本相关的上下文中; 取值越低,则更容易偏离与先前文本相关的上下文。 |
| no_repeat_ngram_size | 控制生成的文本中是否允许出现重复的片段 | 较高的值会阻止更长的短语在生成的文本中重复出现,从而促使生成的文本更加多样化。 较低的值则会阻止单词或字母的重复,使得生成的文本更加独特。 |
| min_length | 生成文本的最小长度 |