AIGC模型概述
AIGC技术的核心是各种深度学习模型
深度学习模型是一个网络结构和参数组成的复杂结构
在这里不对模型进行过多技术原理上的讲解,对于使用者来说,可以将模型当作一个黑盒,使用者输入一些东西(例如输入文字),模型输出某种形态的内容(例如和输入相关的图片,文字)
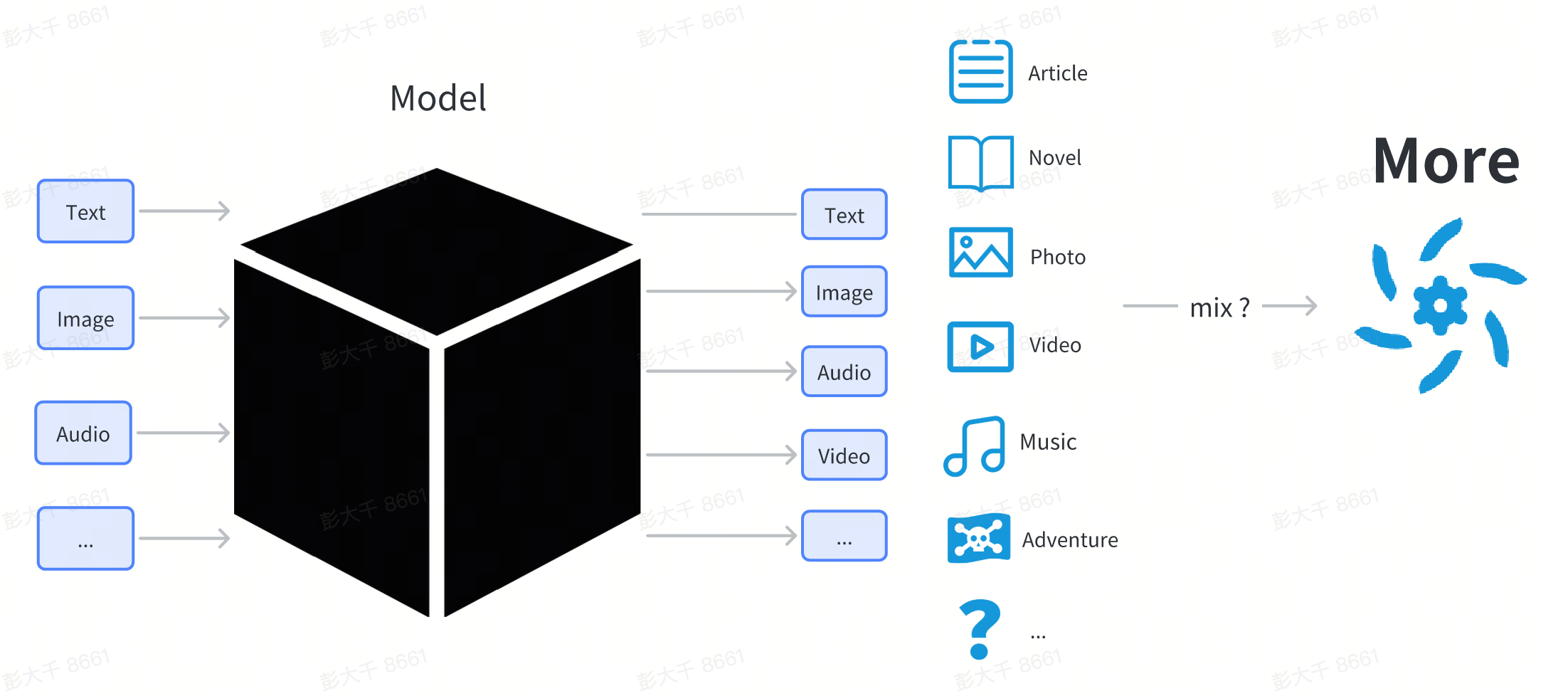
从普通用户的视角来看,模型就是从网上下载下来的一个文件,通常以 .pt 或 .safetensor 或 .checkpoint 结尾
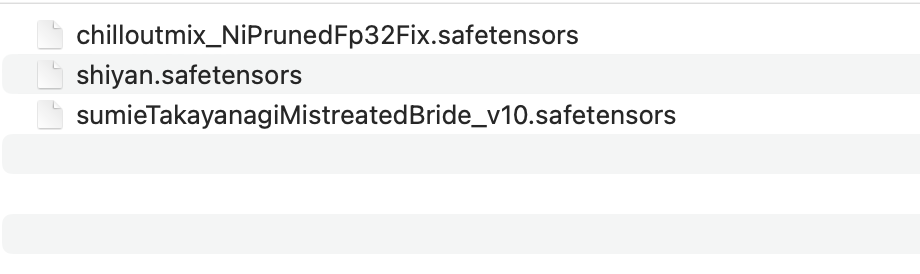
模型无法像普通软件一样直接双击执行,需要被其他软件加载才能进行使用,通常我们会有一个工作台软件用于加载模型并使用,例如
- 用于图像生成的工作台 stable-diffusion-webui
- 用于文字生成的工作台 text-generation-webui
用户将各种模型下载到本地,放入工作台软件指定的目录下,然后启动工作台
在工作台内,用户可以指定使用某一个模型,软件会加载用户选择的模型文件,加载完后,就可以开始使用某一个模型了
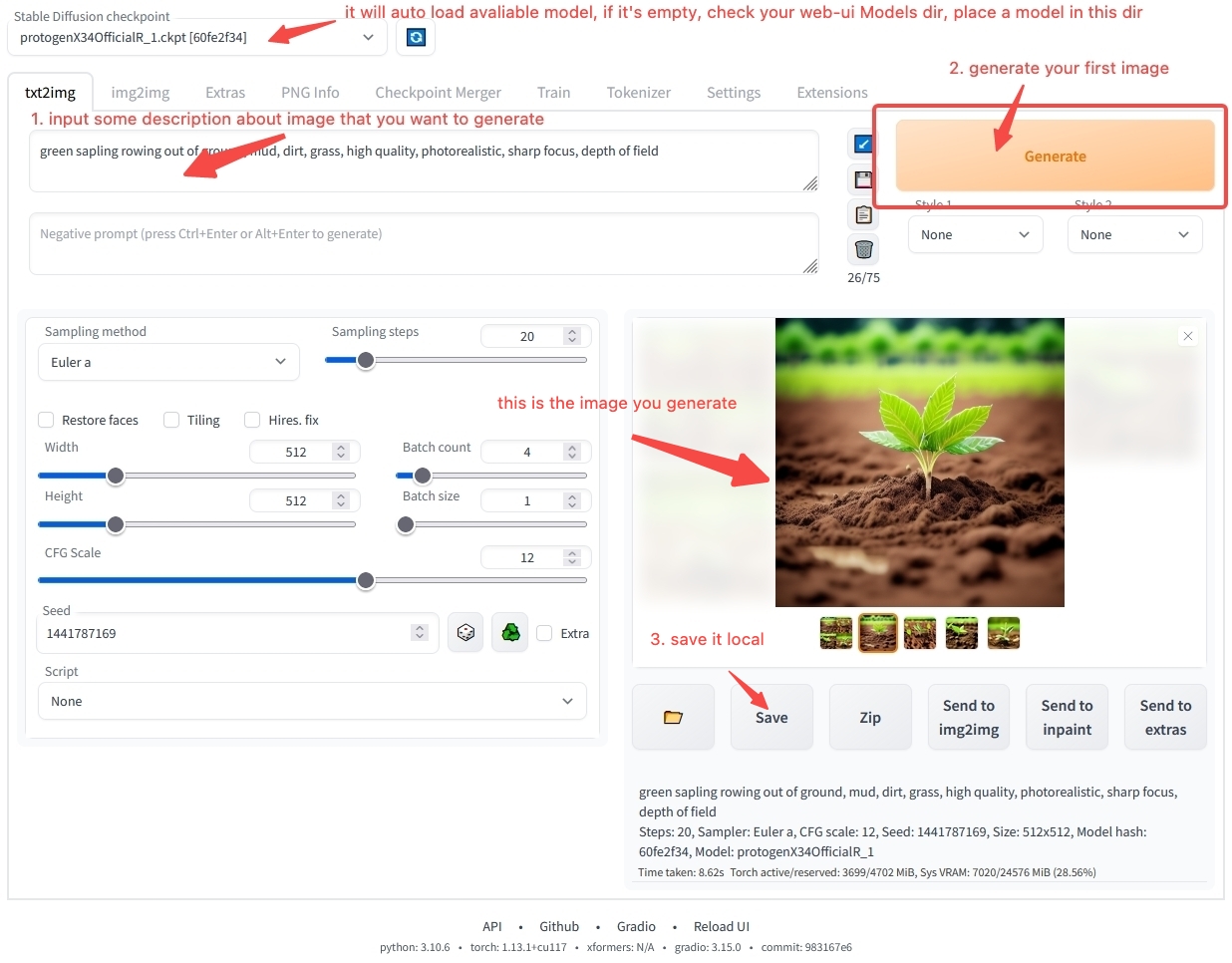
你可能对于如何使用工作台软件仍然存在很多疑惑,别着急,在模型使用概述这一章,我们会一步一步的指导你进行软件的安装和操作,如果你已经迫不及待的想要生成你的第一个AI艺术,可以直接跳到快速开始马上开始,我们提供在线的环境能够帮你快速上手体验,如果你还想了解更多模型相关的内容,让我们继续。
模型分类
你可能已经从互联网上听说过Stable Diffusion,ChilloutMix,KoreanDollLikeness等等各种模型的名称,为什么会有这么多模型呢?他们各自有什么区别?
从使用者的角度来看,模型可以分为基础模型,全参数微调模型,轻量微调模型
| 类别 | 功能 | 介绍 | 例子 |
|---|---|---|---|
| 基础模型 | 可以直接用于内容生成 | 通常是研究机构/科技公司发布一种具有新的网络结构的模型 | Stable Diffusion 1.5, Stable Diffusion 2.1 |
| 全参数微调模型 | 可以直接用于内容生成 | 基础模型在特定的数据上进行微调训练得倒的新模型,和原来的基础模型结构相同,参数不同 | ChilloutMix |
| 轻量微调模型 | 无法直接用于内容生成 | 使用轻量微调方法微调模型 | KoreanDollLikeness, JapaneseDollLikeness |
微调是指: 在特定的数据上,重新训练基础模型,使微调后的模型在特定的场景下,效果比原有的基础模型更好
图像模型
以图像类内容的模型为例,目前几乎市场上所有的模型都是从 Stable Diffusion 系列模型派生而来Stable Diffusion 是 stability.ai 开源的一个图像类内容生成模型,从2022年8月到现在,已经发布了4个版本
- Stable Diffusion
- Stable Diffusion 1.5
- Stable Diffusion 2.0
- Stable Diffusion 2.1
目前社区主流的派生模型都是基于 Stable Diffusion 1.5 进行微调从而得到的
在图像生成领域,Stable Diffusion 系模型基本成为事实标准
文字模型
在文字领域,目前没有一个统一的标准,随着11月份 ChatGPT 的发布,一些研究机构和公司各自发布了自己的微调模型,它们各有各的特点,其中比较有名的包括Meta发布的LLaMA,stability.ai发布的StableLM
当前,在文字内容生成领域存在几个核心问题
- 对话上下文长度较短,如果和模型对话的文字过长,模型会遗忘之前的内容,目前只有 RWKV 因为模型结构和其他模型存在较大的差异,能实现长上下文,大多数文字模型目前都基于 transformer 结构,上下文往往较短
- 模型太大,模型越大,参数越多,内容生成所需要的计算资源也越多
音频模型
在音频领域,存在一些特殊性,单一的音频内容来说,可以分为声优语音,声音,音乐三个大类
- 语音:语音技术传统来说,通常使用文字转语音(Text To Speech)TTS 技术进行生成,缺少艺术的想象力,目前关注的人较少,暂时没有较为成熟的开源工具,缺少数据→模型,模型→内容的范式
- 音乐🎵:音乐是一个更具想象力的领域,早在16年之前,就有商业公司开始提供AI模型生成音乐的服务,随着 Stable Diffusion 的流行,一些开发者也提出使用 Stable Diffusion 来生成音乐,例如 Riffusion ,不过目前效果还不够惊艳,2022年10月,Google 发布了AudioLDM 能够在片段音乐后进行续写,2023年4月份,suno.ai 发布了 bark 模型,目前音乐领域还在发展期,或许经过半年到一年的发展后,也会和图像领域一样突破应用的临界点
- 声音:单纯的声音,例如敲门声,海浪声,因为元素比较单一,相对比较容易生成,现有的AudioLDM,bark已经能够生成简单的声音
视频模型
当前视频模型还处于发展的初期,和图像相比,视频具有上下文信息,同时生成视频需要的资源往往远多于图片,在当前技术不够成熟的时候,往往会空耗计算资源生成低质量的内容。同时,目前暂时较为成熟的面向普通用户的视频生成软件,因此我们不建议普通用户自己尝试进行视频生成,如果你还是希望体验视频生成的话,可以使用 RunwayML 提供的在线服务进行尝试
3D内容模型
在现代3D游戏中,往往需要大量的3D模型资源,此外我们也能使用3D打印技术,将3D模型打印变成现实世界中的实物艺术品
在3D内容生成领域,需求相对较小,同时3D内容,目前暂时没有较为完整的范式
一些可以作为参考的项目包括
目前3D内容生成技术,在部分 saas 服务上已经接近于应用临界点,不过开源的产品中,暂时没有质量相对较高的
其他模型
除了生成基础内容的模型之外,还有一些模型或许融合了多种模态,能进行多种模态内容的理解和生成,当前这部分技术处于发展阶段
一些可以作为参考的项目包括