Présentation des modèles AIGC
Le cœur de la technologie AIGC est constitué de divers modèles d'apprentissage en profondeur.
Un modèle d'apprentissage en profondeur est une structure complexe composée d'une structure de réseau et de paramètres.
Ici, nous n'entrerons pas dans une explication technique trop détaillée du modèle. Pour les utilisateurs, le modèle peut être considéré comme une boîte noire. Les utilisateurs saisissent quelque chose (comme une saisie de texte), et le modèle génère du contenu sous une certaine forme (comme des images et du texte liés à la saisie).
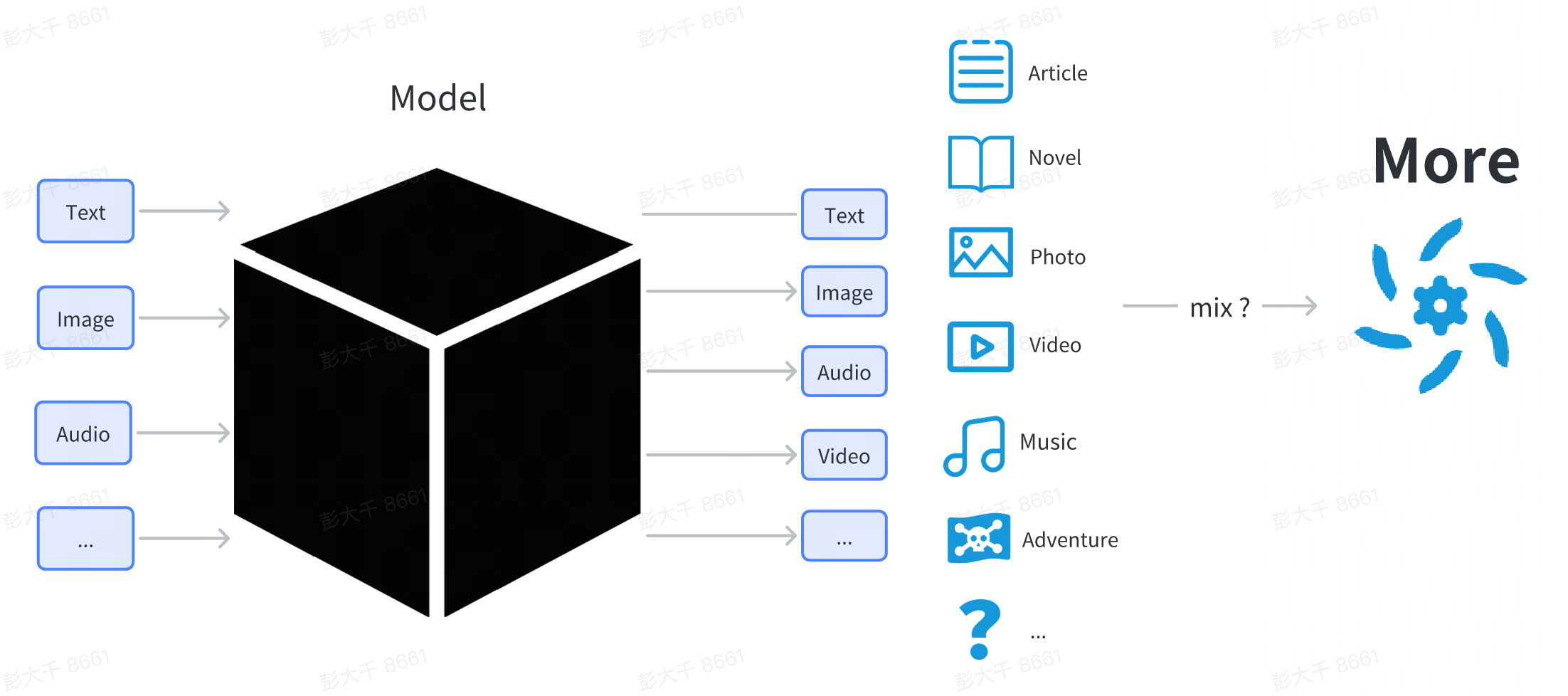
Du point de vue des utilisateurs ordinaires, le modèle est un fichier téléchargé depuis Internet, se terminant généralement par .pt, .safetensor ou .checkpoint.
Le modèle ne peut pas être directement double-cliqué pour être exécuté comme un logiciel ordinaire. Il doit être chargé par un autre logiciel pour être utilisé. Habituellement, nous avons un logiciel de poste de travail pour charger et utiliser le modèle, tel que :
- Poste de travail pour la génération d'images stable-diffusion-webui
- Poste de travail pour la génération de texte text-generation-webui
Les utilisateurs téléchargent divers modèles sur leurs ordinateurs locaux, les placent dans le répertoire spécifié par le logiciel de poste de travail, puis démarrer le poste de travail.
Dans le poste de travail, les utilisateurs peuvent spécifier l'utilisation d'un certain modèle. Le logiciel chargera le fichier de modèle sélectionné. Après le chargement, un modèle spécifique peut être utilisé.
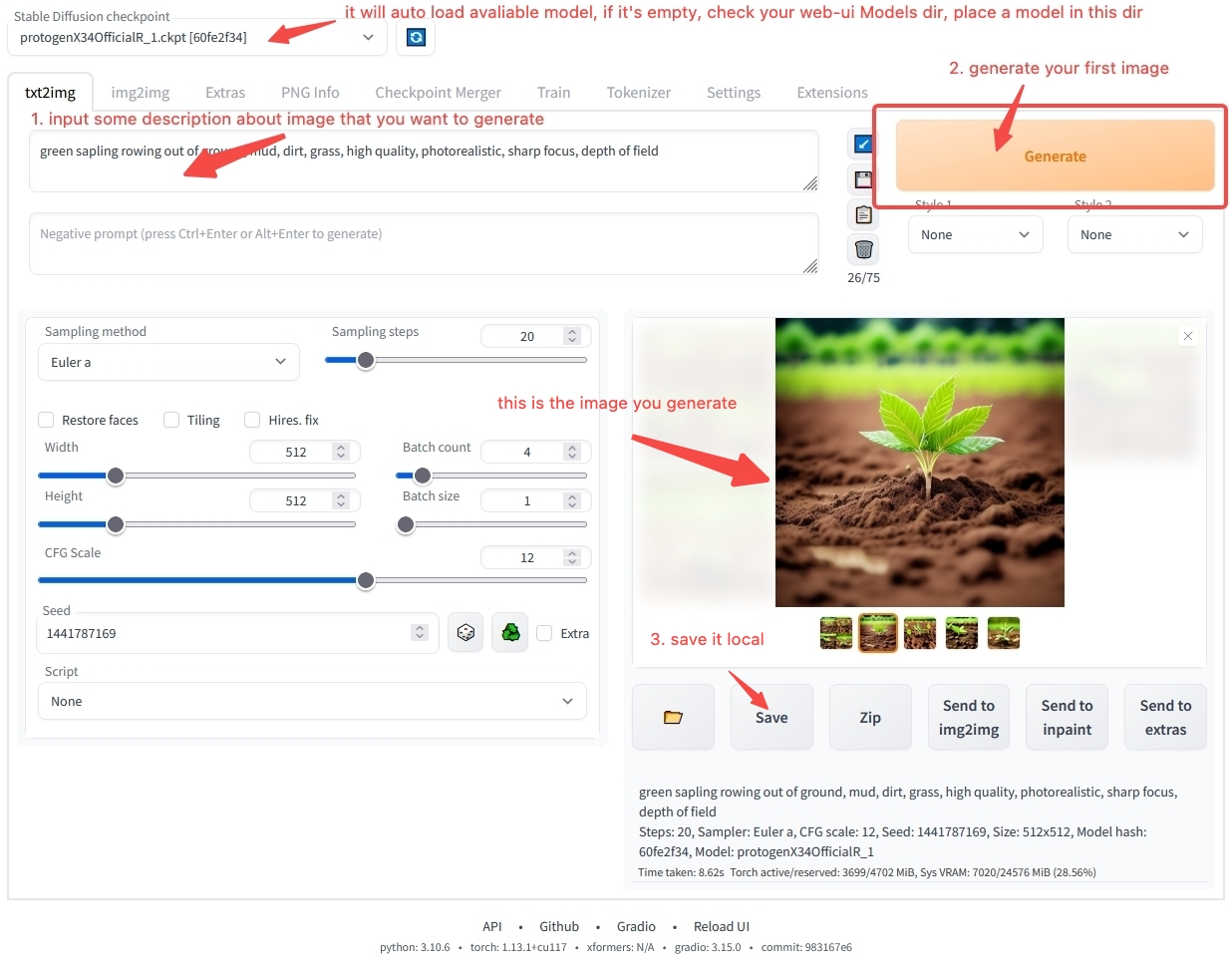
Vous pouvez encore avoir de nombreuses questions sur la façon d'utiliser le logiciel de poste de travail. Ne vous inquiétez pas, dans le chapitre Aperçu de l'utilisation du modèle, nous vous guiderons pas à pas pour installer et utiliser le logiciel. Si vous ne pouvez pas attendre pour générer votre première œuvre d'art AI, vous pouvez passer directement à Démarrage rapide et commencer avec notre environnement en ligne pour vous lancer rapidement. Si vous voulez en savoir plus sur le contenu lié au modèle, poursuivez votre lecture.
Classification des modèles
Vous avez peut-être entendu parler de différents noms de modèles tels que Stable Diffusion, ChilloutMix, et KoreanDollLikeness sur Internet. Pourquoi y a-t-il autant de modèles ? Quelles sont leurs différences ?
Du point de vue des utilisateurs, les modèles peuvent être divisés en modèles de base, modèles de fine-tuning de paramètres complets et modèles de fine-tuning léger.
| Catégorie | Fonction | Introduction | Exemple |
|---|---|---|---|
| Modèle de base | Peut être directement utilisé pour la génération de contenu | Généralement un modèle avec une nouvelle structure de réseau publié par des institutions de recherche / des entreprises de technologie | Stable Diffusion 1.5, Stable Diffusion 2.1 |
| Modèle de fine-tuning de paramètres complets | Peut être directement utilisé pour la génération de contenu | Un nouveau modèle obtenu par fine-tuning du modèle de base sur des données spécifiques, avec la même structure que le modèle de base d'origine mais des paramètres différents | ChilloutMix |
| Modèle de fine-tuning léger | Ne peut pas être directement utilisé pour la génération de contenu | Le modèle est fine-tuné en utilisant des méthodes de fine-tuning légères | KoreanDollLikeness, JapaneseDollLikeness |
Le fine-tuning consiste à ré-entraîner le modèle de base sur des données spécifiques pour obtenir un modèle fine-tuné. Le modèle fine-tuné fonctionne mieux que le modèle de base d'origine dans des scénarios spécifiques.
Modèles d'images
En prenant les modèles de contenu d'image comme exemple, presque tous les modèles actuellement sur le marché sont dérivés de la série de modèles Stable Diffusion. Stable Diffusion est un modèle de génération de contenu d'image open source publié par stability.ai. Depuis août 2022 jusqu'à présent, quatre versions ont été publiées.
- Stable Diffusion
- Stable Diffusion 1.5
- Stable Diffusion 2.0
- Stable Diffusion 2.1
Actuellement, la plupart des modèles dérivés populaires dans la communauté sont basés sur Stable Diffusion 1.5 pour le fine-tuning.
Dans le domaine de la génération d'images, les modèles de la série Stable Diffusion sont devenus la norme de facto.
Modèles de texte
Dans le domaine du texte, il n'y a actuellement pas de norme unifiée. Avec la sortie de ChatGPT en novembre, certaines institutions de recherche et entreprises ont publié leurs propres modèles fine-tunés, chacun ayant ses propres caractéristiques. Parmi les plus célèbres, on peut citer LLaMA publié par Meta et StableLM publié par stability.ai.
Actuellement, il existe plusieurs problèmes clés dans la génération de contenu de texte :
- Longueur de contexte de dialogue courte, si le texte pour le dialogue avec le modèle est trop long, le modèle oubliera le contenu précédent. Actuellement, seul RWKV peut atteindre une longue contexte en raison de la grande différence de structure de modèle avec les autres modèles. La plupart des modèles de texte sont actuellement basés sur des structures de transformateur, et le contexte est souvent court.
- Les modèles sont trop grands, plus le modèle est grand, plus il y a de paramètres, et plus il faut de ressources de calcul pour la génération de contenu.
Modèles audio
Dans le domaine audio, il y a quelques particularités. Pour un seul contenu audio, il peut être divisé en trois catégories : voix d'acteur, son et musique.
- Voix : Traditionnellement, la technologie de la parole utilise généralement la technologie de synthèse de la parole (TTS) pour la génération, manquant d'imagination artistique. Actuellement, peu de gens y prêtent attention, et il n'y a pas d'outil open source mature pour le paradigme de données->modèle, modèle->contenu.
- Musique🎵 : La musique est un domaine plus imaginatif. Il y a 16 ans, les entreprises commerciales ont commencé à fournir des modèles d'IA pour générer de la musique. Avec la popularité de Stable Diffusion, certains développeurs ont également proposé d'utiliser Stable Diffusion pour générer de la musique, comme Riffusion. Cependant, l'effet actuel n'est pas assez étonnant. En octobre 2022, Google a publié AudioLDM, qui peut continuer à écrire après un segment musical. En avril 2023, suno.ai a publié le modèle bark. Le domaine de la musique est encore en phase de développement. Peut-être qu'après six mois à un an de développement, il franchira également le point critique d'application comme le domaine de l'image.
- Son : Pour les sons simples, comme le bruit d'une porte qui claque et le son des vagues, ils sont relativement faciles à générer. Les modèles AudioLDM et bark existants peuvent générer des sons simples.
Modèles vidéo
Actuellement, les modèles vidéo en sont encore aux premiers stades de développement. Par rapport aux images, les vidéos ont des informations contextuelles, et les ressources requises pour la génération de vidéos sont souvent beaucoup plus importantes que celles pour les images. Lorsque la technologie n'est pas assez mature, elle gaspille souvent des ressources de calcul pour générer du contenu de faible qualité. À l'heure actuelle, il n'y a pas de logiciel de génération de vidéo relativement mature pour les utilisateurs ordinaires. Par conséquent, nous ne recommandons pas aux utilisateurs ordinaires d'essayer de générer des vidéos par eux-mêmes. Si vous voulez quand même expérimenter la génération de vidéos, vous pouvez utiliser les services en ligne fournis par RunwayML pour l'essayer.
Modèles de contenu 3D
Dans les jeux 3D modernes, un grand nombre de ressources de modèles 3D sont souvent nécessaires. De plus, nous pouvons utiliser la technologie d'impression 3D pour imprimer des modèles 3D en objets d'art du monde réel.
Dans le domaine de la génération de contenu 3D, la demande est relativement faible, et il n'y a actuellement pas de paradigme complet. Certains projets pouvant servir de référence comprennent :
Actuellement, la technologie de génération de contenu 3D se rapproche du point critique d'application sur certains services saas. Cependant, il n'y a pas encore de produit open source de qualité relativement élevée.
Autres modèles
En plus des modèles qui génèrent un contenu de base, il existe également des modèles qui peuvent intégrer plusieurs modalités et peuvent comprendre et générer un contenu multimodal. Actuellement, cette partie de la technologie est en phase de développement.
Certains projets pouvant être utilisés comme références incluent: