레딧 크러쉬 게시물
레딧은 인터넷에서 가장 인기 있는 커뮤니티로, 각각 다른 게시물에 답글을 남길 수 있는 작은 주제 그룹인 서브레딧으로 구성됩니다.
우리는 일부 레딧 크러쉬 주제의 데이터를 수집하여 LLama 모델에서 파인튜닝하여 레딧 게시물 생성을 위한 샘플 애플리케이션을 만들었습니다. (온라인 경험은 한 번에 한 명의 사용자만 지원합니다. 사용할 수 없는 경우 간소화된 버전을 시도해보십시오.)
첫 번째 레딧 크러쉬 게시물 생성
온라인 경험 페이지를 열고 "나는 만났다"와 같은 이야기의 시작을 입력한 다음, 아래쪽의 "생성"을 클릭하면 모델이 자동으로 이야기를 완성합니다. 만족스럽지 않은 경우 언제든지 생성을 중지하고 이야기를 직접 수정한 후 계속 생성할 수 있습니다.
"어제"나 "최근에"와 같은 이야기의 시작을 떠올리면 모델이 이야기를 완성해 줄 수 있습니다.
텍스트 생성 과정
이 애플리케이션을 예로 들어 텍스트 생성 과정을 경험해 봅시다.
텍스트 생성의 로직은 비교적 간단합니다. 이야기의 시작을 입력하면 모델이 이어서 쓰게 됩니다. 생성을 언제든지 일시 중지하고 이야기를 수정한 후 다시 생성할 수 있습니다.
텍스트 생성
먼저 텍스트를 생성할 때는 "어제", "귀여운 병아리" 등의 시작을 입력해야 합니다. 그런 다음 아래쪽의 "생성" 버튼을 클릭하여 생성을 시작합니다. 생성을 중지하려면 "중지" 버튼을 클릭합니다. 최대 생성 토큰을 사용하여 생성된 텍스트의 최대 길이를 제어할 수 있습니다.
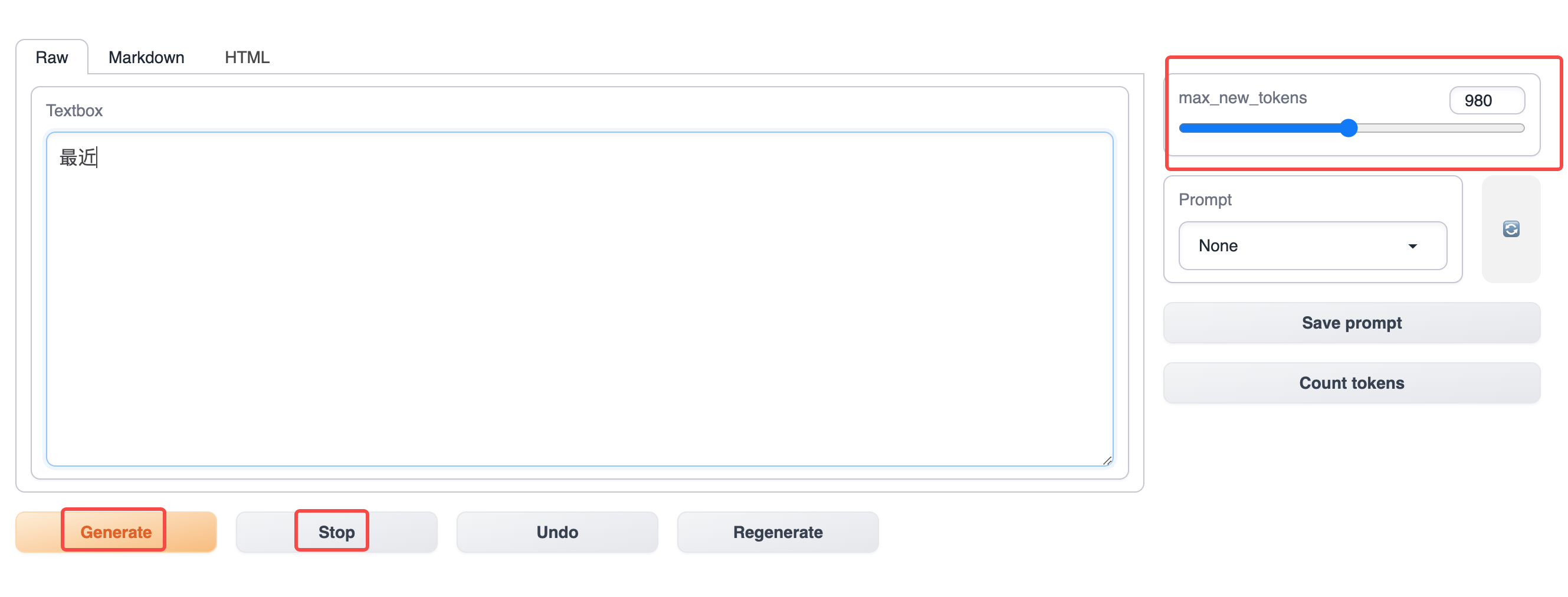
매개변수 조정
매개변수를 조정하여 다른 결과를 생성할 수 있습니다.
매개변수 탭으로 전환합니다.
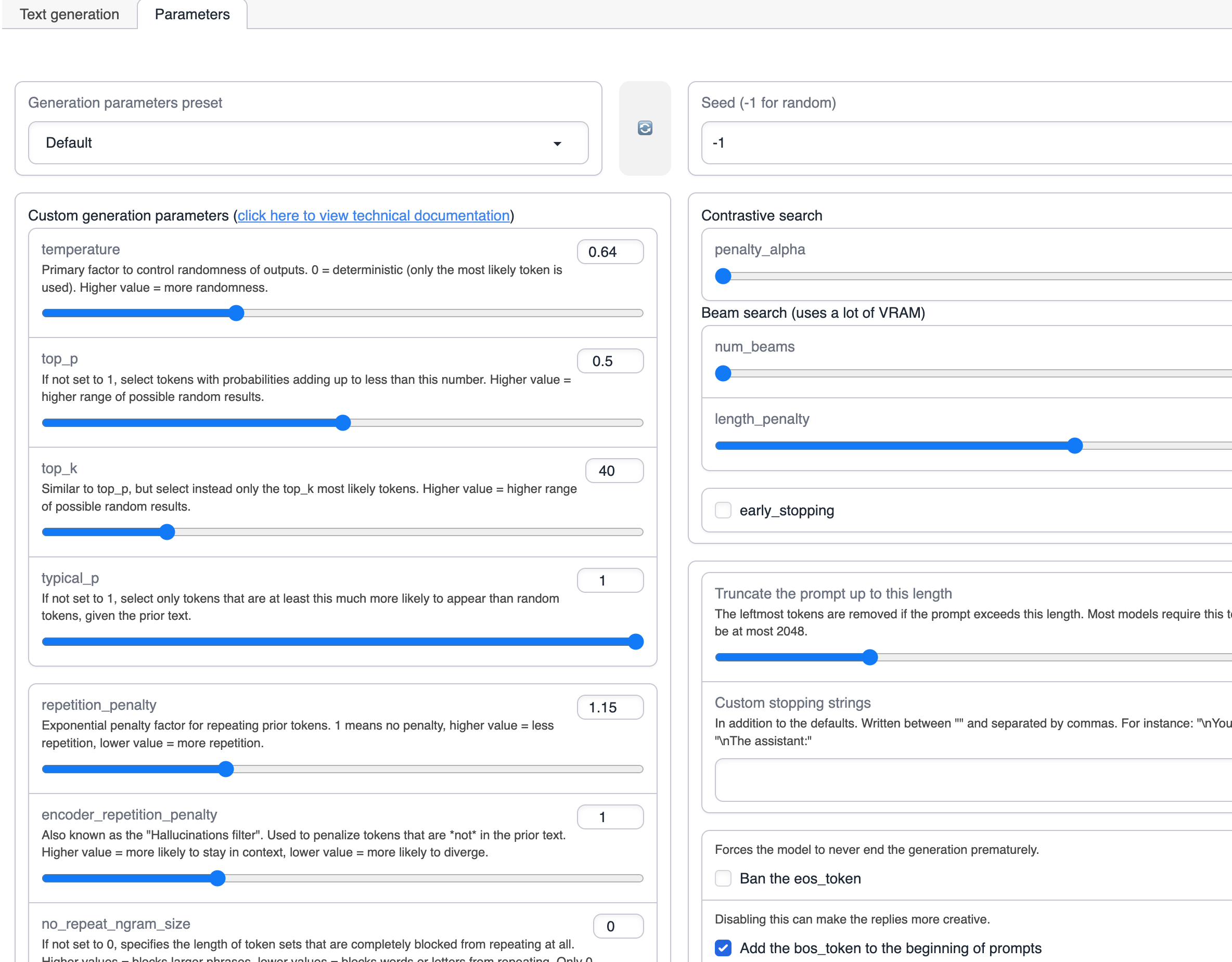
이러한 매개변수를 조정함으로써 생성된 텍스트의 다양성을 제어할 수 있습니다.
매개변수의 구체적인 의미는 다음 표와 같습니다.
| 매개변수 | 기능 | 설명 |
|---|---|---|
| seed | 랜덤 시드 | |
| temperature | 출력 무작위성을 제어하는 주요 요소 | 0 = 결정론적 (가장 가능성이 높은 토큰만 사용) 값이 높을수록 더 많은 무작위성이 발생합니다. |
| Top-P | 출력 무작위성을 제어하는 요소 | 1보다 작은 float로 설정하면 가장 가능성이 높은 토큰의 최소 확률 집합만 유지하여 생성합니다. 값이 높을수록 더 넓은 범위의 가능한 무작위 결과가 생성됩니다. |
| Top-K | 출력 무작위성을 제어하는 요소 | 다음 단어를 가장 가능성이 높은 k개의 후보 중에서 선택합니다. Top-K가 10으로 설정된 경우, 가능성이 가장 높은 10개의 후보 중에서만 선택합니다. |
| typical_p | 출력 무작위성을 제어하는 요소 | "typical_p" 매개변수가 1보다 작은 값으로 설정된 경우, 알고리즘은 이전 텍스트 내용을 기반으로 임의의 토큰보다 더 자주 나타나는 토큰을 선택합니다. 이는 일부 덜 일반적이거나 관련성이 적은 토큰을 걸러내고 의미 있는 또는 관련성이 높은 토큰만 선택하는 데 사용될 수 있습니다. "typical_p" 매개변수가 1로 설정된 경우, 모든 토큰이 무작위 토큰과 상관없이 선택됩니다. |
| repetition_penalty | 출력 반복을 제어하는 매개변수 | 1은 패널티가 없음을 의미합니다. 값이 높을수록 반복이 적어지고, 값이 낮을수록 반복이 더 많아집니다. |
| encoder_repetition_penalty | 생성된 텍스트와 이전 텍스트 간의 일관성에 영향을 미치는 매개변수 | 1.0은 패널티가 없음을 의미합니다. 값이 높을수록 이전 텍스트와 관련된 문맥을 유지하는 경향이 커지고, 값이 낮을수록 이전 텍스트와 관련 없는 문맥으로 쉽게 이탈할 수 있습니다. |
| no_repeat_ngram_size | 생성된 텍스트에서 반복되는 단편을 허용할지 여부를 제어합니다. | 값이 높을수록 생성된 텍스트에서 긴 구절이 반복되는 것을 방지하여 생성된 텍스트를 더 다양하게 만듭니다. 값이 낮을수록 단어나 글자의 반복을 방지하여 생성된 텍스트를 더 유니크하게 만듭니다. |
| min_length | 생성된 텍스트의 최소 길이 |