Überblick über AIGC-Modelle
Der Kern der AIGC-Technologie sind verschiedene Deep-Learning-Modelle.
Ein Deep-Learning-Modell ist eine komplexe Struktur, die aus einer Netzwerkstruktur und Parametern besteht.
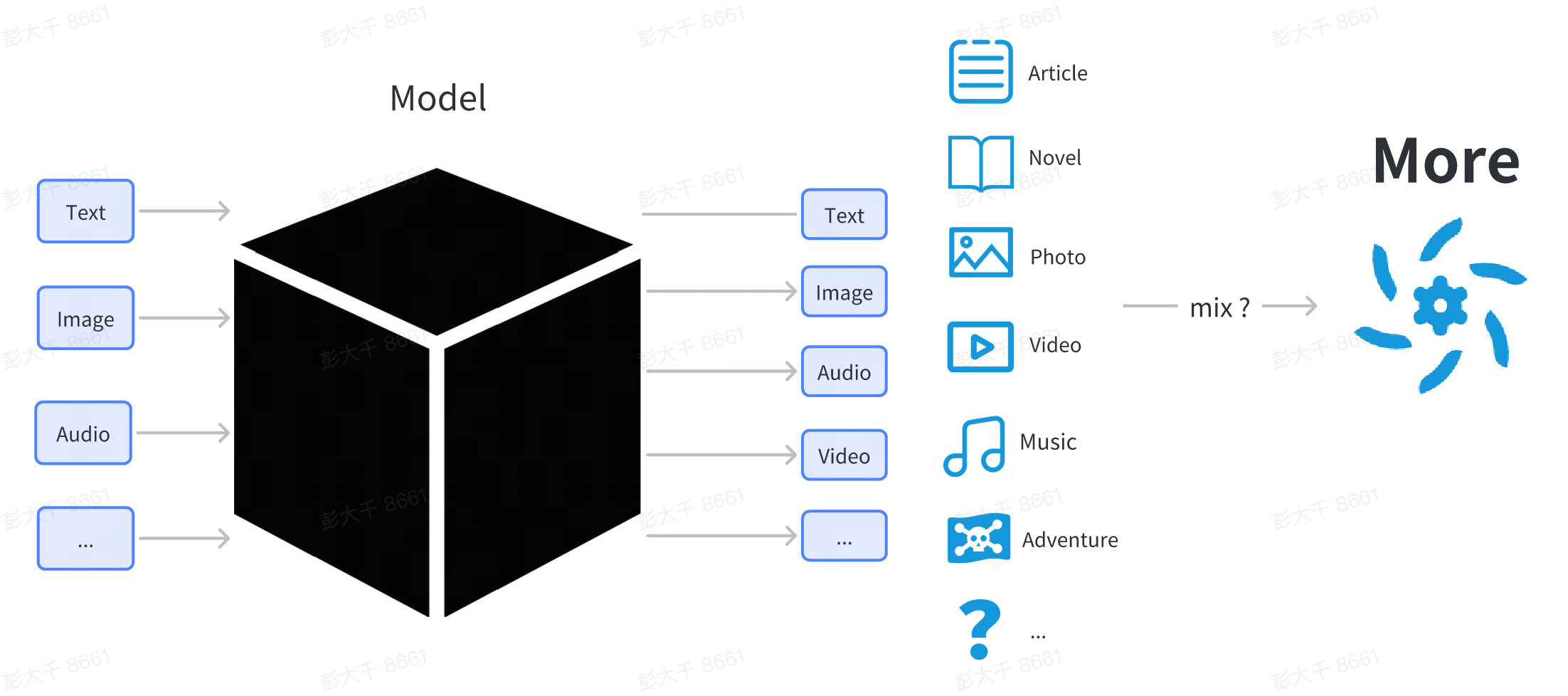
Hier werden wir nicht zu sehr auf die technische Erklärung des Modells eingehen. Für Benutzer kann das Modell als Black-Box behandelt werden. Benutzer geben etwas ein (wie Texteingabe), und das Modell gibt Inhalte in einer bestimmten Form aus (wie Bilder und Text, die mit der Eingabe zusammenhängen).
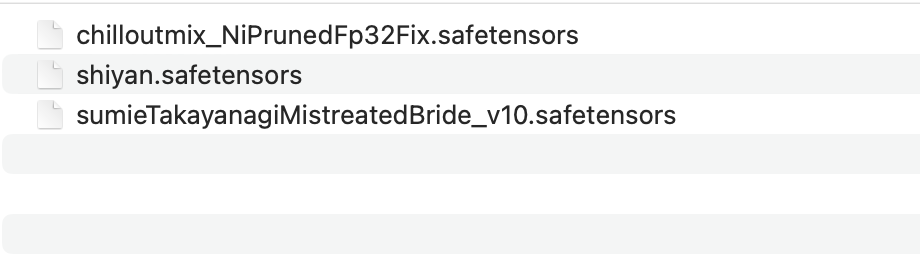
Aus der Sicht gewöhnlicher Benutzer ist das Modell eine Datei, die aus dem Internet heruntergeladen wird und normalerweise mit .pt, .safetensor oder .checkpoint endet.
Das Modell kann nicht wie gewöhnliche Software direkt doppelgeklickt werden, um ausgeführt zu werden. Es muss von anderer Software geladen werden, um verwendet zu werden. Normalerweise haben wir eine Workstation-Software, um das Modell zu laden und zu verwenden, wie:
- Workstation für Bildgenerierung stable-diffusion-webui
- Workstation für Textgenerierung text-generation-webui
Benutzer laden verschiedene Modelle auf ihre lokalen Computer, platzieren sie im vom Workstation-Software angegebenen Verzeichnis und starten dann die Workstation.
In der Workstation können Benutzer angeben, ein bestimmtes Modell zu verwenden. Die Software lädt die ausgewählte Modell-Datei. Nach dem Laden kann ein bestimmtes Modell verwendet werden.
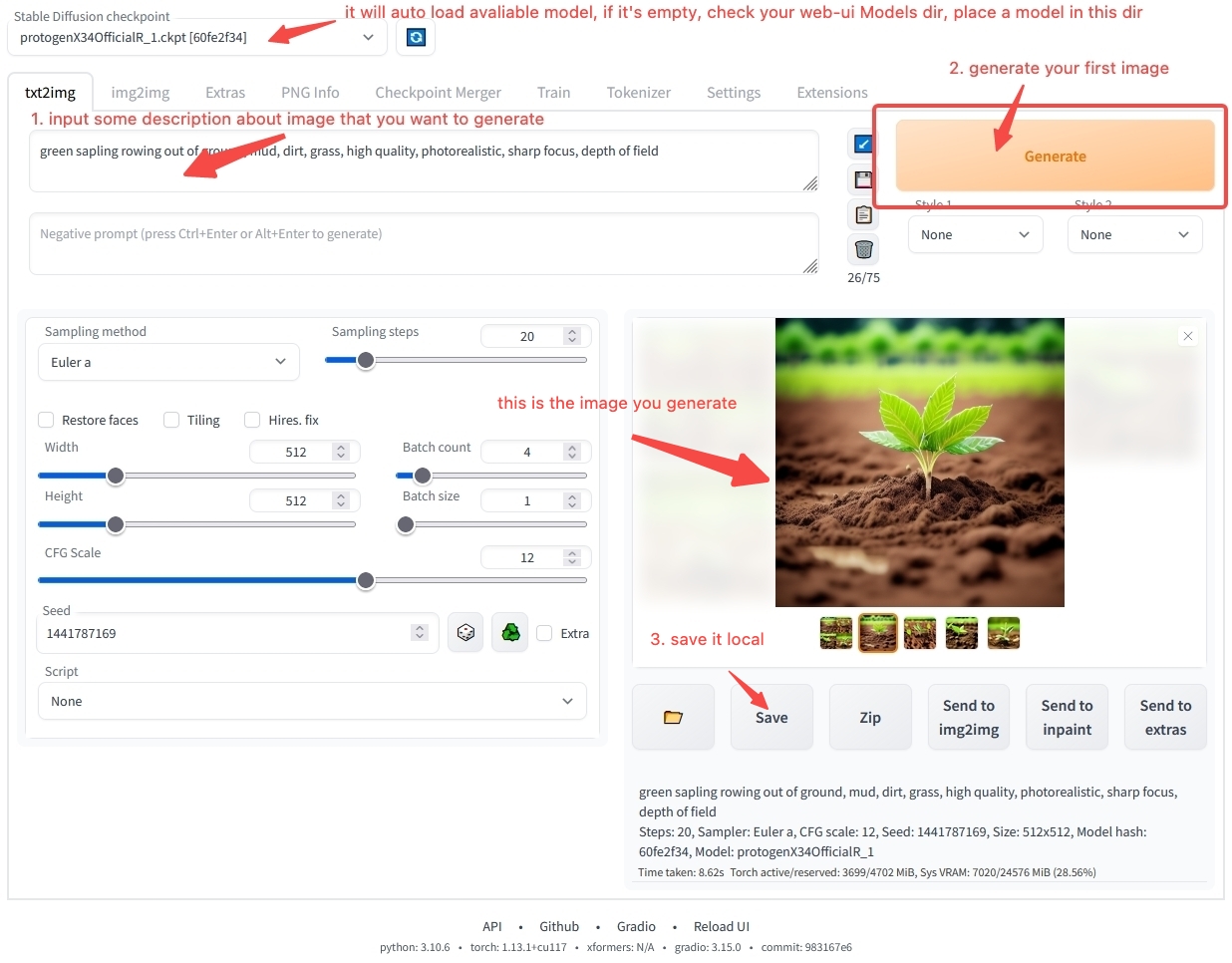
Sie haben vielleicht immer noch viele Zweifel, wie Sie die Workstation-Software verwenden können. Keine Sorge, im Kapitel Modellnutzungsübersicht werden wir Sie Schritt für Schritt bei der Installation und Bedienung der Software anleiten. Wenn Sie nicht warten können, um Ihre erste KI-Kunst zu generieren, können Sie direkt zum Schnellstart springen und mit unserer Online-Umgebung schnell starten. Wenn Sie mehr über modellbezogene Inhalte erfahren möchten, lesen Sie weiter.
Modellklassifikation
Sie haben vielleicht von verschiedenen Modellnamen wie Stable Diffusion, ChilloutMix und KoreanDollLikeness im Internet gehört. Warum gibt es so viele Modelle? Was sind ihre Unterschiede?
Aus der Sicht der Benutzer können Modelle in Grundmodelle, vollständig parameterfeinabgestimmte Modelle und leichtgewichtige feinabgestimmte Modelle unterteilt werden.
| Kategorie | Funktion | Einführung | Beispiel |
|---|---|---|---|
| Grundmodell | Kann direkt für die Inhaltsgenerierung verwendet werden | Normalerweise ein Modell mit einer neuen Netzwerkstruktur, das von Forschungseinrichtungen/Technologieunternehmen veröffentlicht wurde | Stable Diffusion 1.5, Stable Diffusion 2.1 |
| Vollständig parameterfeinabgestimmtes Modell | Kann direkt für die Inhaltsgenerierung verwendet werden | Ein neues Modell, das durch Feinabstimmung des Grundmodells auf bestimmten Daten erhalten wurde, mit derselben Struktur wie das ursprüngliche Grundmodell, aber unterschiedlichen Parametern | ChilloutMix |
| Leichtgewichtiges feinabgestimmtes Modell | Kann nicht direkt für die Inhaltsgenerierung verwendet werden | Das Modell wird unter Verwendung von leichtgewichtigen Feinabstimmungsmethoden feinabgestimmt | KoreanDollLikeness, JapaneseDollLikeness |
Feinabstimmung bezieht sich auf das erneute Training des Grundmodells auf bestimmten Daten, um ein feinabgestimmtes Modell zu erhalten. Das feinabgestimmte Modell funktioniert in bestimmten Szenarien besser als das ursprüngliche Grundmodell.
Bildmodelle
Nehmen wir als Beispiel Modelle für Bildinhalte. Fast alle derzeit auf dem Markt erhältlichen Modelle stammen aus der Stable Diffusion-Serie von Modellen. Stable Diffusion ist ein Open-Source-Modell für die Generierung von Bildinhalten, das von stability.ai veröffentlicht wurde. Von August 2022 bis heute wurden vier Versionen veröffentlicht.
- Stable Diffusion
- Stable Diffusion 1.5
- Stable Diffusion 2.0
- Stable Diffusion 2.1
Derzeit basieren die meisten abgeleiteten Modelle in der Community auf Stable Diffusion 1.5 für die Feinabstimmung.
Im Bereich der Bildgenerierung sind Stable Diffusion-Seriemodelle zum De-facto-Standard geworden.
Textmodelle
Im Bereich des Textes gibt es derzeit keinen einheitlichen Standard. Mit der Veröffentlichung von ChatGPT im November haben einige Forschungseinrichtungen und Unternehmen ihre eigenen feinabgestimmten Modelle veröffentlicht, von denen jedes seine eigenen Merkmale aufweist. Zu den bekannteren gehören LLaMA, das von Meta veröffentlicht wurde, und StableLM, das von stability.ai veröffentlicht wurde.
Derzeit gibt es mehrere Kernprobleme bei der Generierung von Textinhalten:
- Kurze Dialogkontextlänge, wenn der Text für den Dialog mit dem Modell zu lang ist, vergisst das Modell den vorherigen Inhalt. Derzeit kann aufgrund des großen Unterschieds in der Modellstruktur zwischen anderen Modellen nur RWKV einen langen Kontext erreichen. Die meisten Textmodelle basieren derzeit auf Transformer-Strukturen, und der Kontext ist oft kurz.
- Modelle sind zu groß, je größer das Modell, desto mehr Parameter und desto mehr Rechenressourcen sind für die Inhaltsgenerierung erforderlich.
Audio-Modelle
Im Bereich der Audio gibt es einige Besonderheiten. Für einen einzelnen Audioinhalt kann er in drei Kategorien unterteilt werden: Synchronsprecherstimme, Ton und Musik.
- Stimme: Traditionell verwendet die Sprachtechnologie normalerweise Text-to-Speech (TTS)-Technologie für die Generierung, was an künstlerischer Vorstellungskraft mangelt. Derzeit achten nur wenige Menschen darauf, und es gibt kein ausgereiftes Open-Source-Tool für das Daten->Modell-, Modell->Inhaltsparadigma.
- Musik🎵: Musik ist ein imaginäreres Feld. Vor 16 Jahren begannen kommerzielle Unternehmen, KI-Modelle zur Generierung von Musik bereitzustellen. Mit der Popularität von Stable Diffusion haben einige Entwickler auch vorgeschlagen, Stable Diffusion zur Generierung von Musik zu verwenden, wie Riffusion. Derzeit ist die Wirkung jedoch nicht erstaunlich genug. Im Oktober 2022 veröffentlichte Google AudioLDM, das nach einem Musiksegment weiter schreiben kann. Im April 2023 veröffentlichte suno.ai das Bark-Modell. Das Musikfeld befindet sich noch in der Entwicklungsphase. Vielleicht wird es nach einem halben bis einem Jahr Entwicklung auch den kritischen Anwendungspunkt wie im Bildbereich durchbrechen.
- Ton: Für einfache Geräusche wie Klopfen an einer Tür und das Geräusch von Wellen sind sie relativ einfach zu generieren. Vorhandene AudioLDM und Bark können einfache Geräusche generieren.
Video-Modelle
Derzeit befinden sich Video-Modelle noch in den Anfangsstadien der Entwicklung. Im Vergleich zu Bildern verfügen Videos über Kontextinformationen, und die Ressourcen, die für die Video-Generierung benötigt werden, sind oft viel höher als die für Bilder. Wenn die Technologie noch nicht ausgereift genug ist, verschwendet sie oft Rechenressourcen für die Generierung von niedrigwertigen Inhalten. Derzeit gibt es für gewöhnliche Benutzer keine relativ ausgereifte Video-Generierungssoftware. Daher empfehlen wir gewöhnlichen Benutzern nicht, selbst Videos zu generieren. Wenn Sie dennoch die Video-Generierung erleben möchten, können Sie die Online-Services von RunwayML verwenden, um es auszuprobieren.
3D-Inhaltsmodelle
In modernen 3D-Spielen werden oft eine große Anzahl von 3D-Modellressourcen benötigt. Darüber hinaus können wir die 3D-Drucktechnologie verwenden, um 3D-Modelle in Kunstobjekte der realen Welt zu drucken.
Im Bereich der 3D-Inhaltsgenerierung ist die Nachfrage relativ gering, und es gibt derzeit kein vollständiges Paradigma. Einige Projekte, die als Referenz verwendet werden können, sind:
Derzeit ist die 3D-Inhaltsgenerierungstechnologie nahe am Anwendungskritischen Punkt auf einigen Saas-Services. Es gibt jedoch noch kein Open-Source-Produkt mit relativ hoher Qualität.
Andere Modelle
Neben Modellen, die grundlegende Inhalte generieren, gibt es auch Modelle, die mehrere Modalitäten integrieren und mehrere Modalinhalte verstehen und generieren können. Derzeit befindet sich dieser Teil der Technologie in der Entwicklungsphase.
Einige Projekte, die als Referenz verwendet werden können, sind: