Обзор моделей AIGC
Основой технологии AIGC являются различные модели глубокого обучения.
Модель глубокого обучения - это сложная структура, состоящая из сетевой структуры и параметров.
В этой главе мы не будем углубляться в технические принципы модели. Для пользователей модель может рассматриваться как черный ящик. Пользователи вводят что-то (например, текст), и модель выдает содержание в какой-то форме (например, изображения или текст), связанное с вводом.
С точки зрения обычного пользователя, модель - это файл, загруженный из Интернета, обычно заканчивающийся на .pt, .safetensor или .checkpoint.
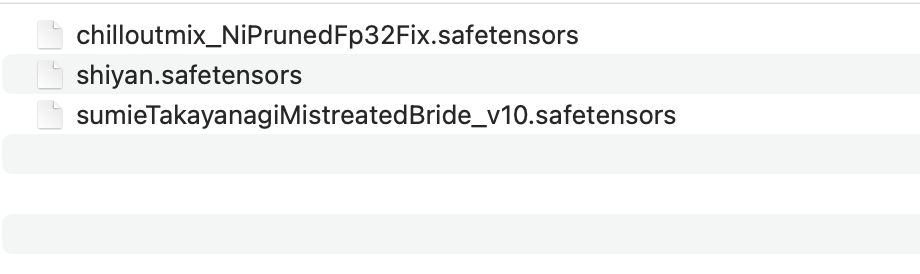
Модель не может быть выполнена непосредственно двойным щелчком, как обычное программное обеспечение. Она должна быть загружена другим программным обеспечением перед использованием. Обычно у нас есть рабочее программное обеспечение для загрузки и использования моделей, такое как:
- Рабочая станция для создания изображений: stable-diffusion-webui
- Рабочая станция для создания текста: text-generation-webui
Пользователи загружают различные модели на свой локальный компьютер, помещают их в каталог, указанный в рабочей станции, а затем запускают рабочую станцию.
В рабочей станции пользователи могут указать, какую модель использовать. Программное обеспечение загрузит файл модели, выбранный пользователем. После загрузки можно использовать конкретную модель.
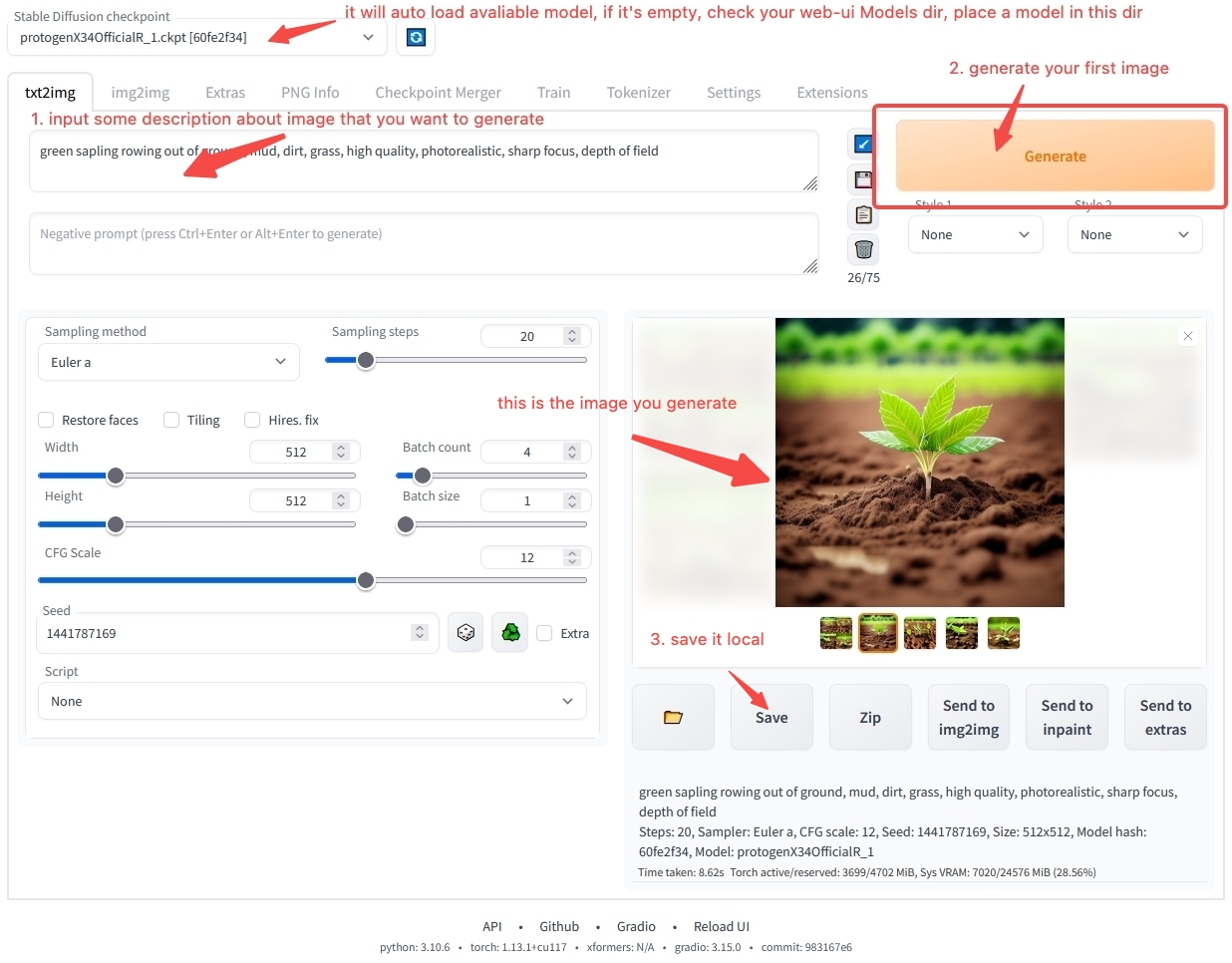
используйте stable-diffusion-webui, чтобы сгенерировать свое первое изображение
У вас могут возникнуть многие вопросы о том, как использовать программное обеспечение рабочей станции. Не волнуйтесь. В главе Обзор использования модели мы пошагово расскажем вам, как установить и работать с программным обеспечением. Если вы не можете дождаться, чтобы создать свое первое AI-произведение искусства, вы можете перейти непосредственно к Быстрому старту и использовать нашу онлайн-среду, чтобы быстро начать работу. Если вы все еще хотите узнать больше о связанном с моделью контенте, продолжайте читать.
Классификация моделей
Вы, возможно, слышали различные названия моделей, такие как Stable Diffusion, ChilloutMix и KoreanDollLikeness в Интернете. Почему существует так много моделей? В чем их различия?
С точки зрения пользователя модели можно разделить на базовые модели, модели с полным параметрическим дообучением и модели с легким дообучением.
| Категория | Функция | Описание | Пример |
|---|---|---|---|
| Базовые модели | Можно использовать непосредственно для создания контента | Обычно исследовательские учреждения/технологические компании выпускают модель с новой сетевой структурой | Stable Diffusion 1.5, Stable Diffusion 2.1 |
| Модели с полным параметрическим дообучением | Можно использовать непосредственно для создания контента | Новая модель, полученная путем дообучения базовой модели на конкретных данных, с той же структурой, что и у исходной базовой модели, но с другими параметрами | ChilloutMix |
| Модели с легким дообучением | Нельзя использовать непосредственно для создания контента | Модель дообучается с использованием методов легкого дообучения | KoreanDollLikeness, JapaneseDollLikeness |
Дообучение означает повторное обучение базовой модели на конкретных данных, чтобы дообученная модель работала лучше, чем исходная базовая модель в конкретных сценариях.
Модели изображений
На примере моделей изображений практически все модели на рынке производных от серии моделей Stable Diffusion. Stable Diffusion - это модель генерации содержимого изображения с открытым исходным кодом, выпущенная stability.ai. С августа 2022 года по настоящее время было выпущено четыре версии.
- Stable Diffusion
- Stable Diffusion 1.5
- Stable Diffusion 2.0
- Stable Diffusion 2.1
В настоящее время большинство основных производных моделей в сообществе основаны на Stable Diffusion 1.5 для дообучения.
В области генерации изображений модели серии Stable Diffusion стали де-факто стандартом.
Модели текста
В области текста на данный момент нет единого стандарта. С выпуском ChatGPT в ноябре некоторые исследовательские учреждения и компании выпустили свои собственные дообученные модели, каждая со своими характеристиками, включая LLaMA, выпущенную Meta, и StableLM, выпущенную stability.ai.
В настоящее время в генерации текстового контента существуют несколько основных проблем:
- Короткий контекст разговора: если текст в разговоре с моделью слишком длинный, модель забудет предыдущее содержание. В настоящее время только RWKV может достигать длинного контекста из-за значительных различий в структуре модели по сравнению с другими моделями. Большинство текстовых моделей основаны на структурах трансформаторов, и контекст часто является коротким.
- Модели слишком большие: чем больше модель, тем больше параметров она имеет, и тем больше вычислительных ресурсов требуется для создания контента.
Аудио Модель
В области аудио есть некоторые особенности. Отдельный аудиоконтент можно разделить на три категории: Голос Seiyuu, звук, музыка
- Голос: Традиционно говоря, голосовые технологии обычно генерируются с помощью технологии Text To Speech (Текст в речь) TTS, которой не хватает художественного воображения Парадигмы данных→модель, модель→контент
- Музыка: Музыка – более творческая область. Еще 16 лет назад коммерческие компании начали предоставлять музыкальные сервисы, созданные с помощью моделей ИИ. С ростом популярности Stable Diffusion некоторые разработчики также предложили использовать Stable Diffusion. для создания музыки, такой как Riffusion, но текущий эффект недостаточно удивителен. В октябре 2022 года Google выпустила AudioLDM, который может продолжать запись после музыкального произведения. В апреле 2023 года suno.ai выпустила модель коры. В настоящее время , музыкальное поле все еще находится в стадии разработки, возможно, через полгода-год развития оно пробьет критическую точку приложения, как и поле изображения.
- Звук: Простые звуки, такие как стук в дверь и океанские волны, относительно легко генерировать, потому что элементы относительно просты. Существующие AudioLDM и лай способны генерировать простые звуки.
Видео Модель
Текущая видеомодель все еще находится на ранних стадиях разработки. По сравнению с изображениями, видео содержат контекстную информацию. В то же время для создания видео часто требуется гораздо больше ресурсов, чем для изображений. Когда текущая технология недостаточно развита, вычислительные ресурсы часто тратится на создание низкокачественного контента. В то же время в настоящее время существует относительно зрелое программное обеспечение для создания видео для обычных пользователей, поэтому мы не рекомендуем обычным пользователям пытаться создавать видео самостоятельно. Если вы все еще хотите испытать создание видео, вы можете использовать [RunwayML ](https:// попробуйте онлайн-сервис на runwayml.com/)
Модель 3D-контента
В современных 3D-играх часто требуется большое количество ресурсов 3D-моделей.Кроме того, мы также можем использовать технологию 3D-печати, чтобы превратить печать 3D-моделей в физические произведения искусства в реальном мире.
В области создания 3D-контента спрос относительно невелик, и в то же время относительно полной парадигмы для 3D-контента в настоящее время не существует.
Некоторые проекты, которые можно использовать в качестве справочных материалов, включают
- [стабильная мечта] (https://github.com/ashawkey/stable-dreamfusion)
- [форма-е] (https://github.com/openai/shap-e)
- [три студии] (https://github.com/threestudio-project/threestudio)
В настоящее время технология генерации 3D-контента близка к критической точке применения в некоторых SaaS-сервисах.
Другие модели
В дополнение к моделям, которые генерируют базовый контент, существуют модели, которые могут интегрировать несколько модальностей и могут понимать и генерировать множественный модальный контент.В настоящее время эта часть технологии находится в стадии разработки.
Некоторые проекты, которые можно использовать в качестве справочных материалов, включают
- [minGPT] (https://github.com/karpathy/minGPT)