AIGC 모델 개요
AIGC 기술의 핵심은 다양한 딥 러닝 모델입니다.
딥 러닝 모델은 네트워크 구조와 매개변수로 구성된 복잡한 구조입니다.
이 장에서는 모델의 기술적 원리에 대해 자세히 다루지 않습니다. 사용자는 모델을 블랙 박스로 다룰 수 있습니다. 사용자는 무언가를 입력하면 (예: 텍스트), 모델은 해당 입력과 관련된 이미지 또는 텍스트와 같은 내용을 어떤 형태로든 출력합니다.
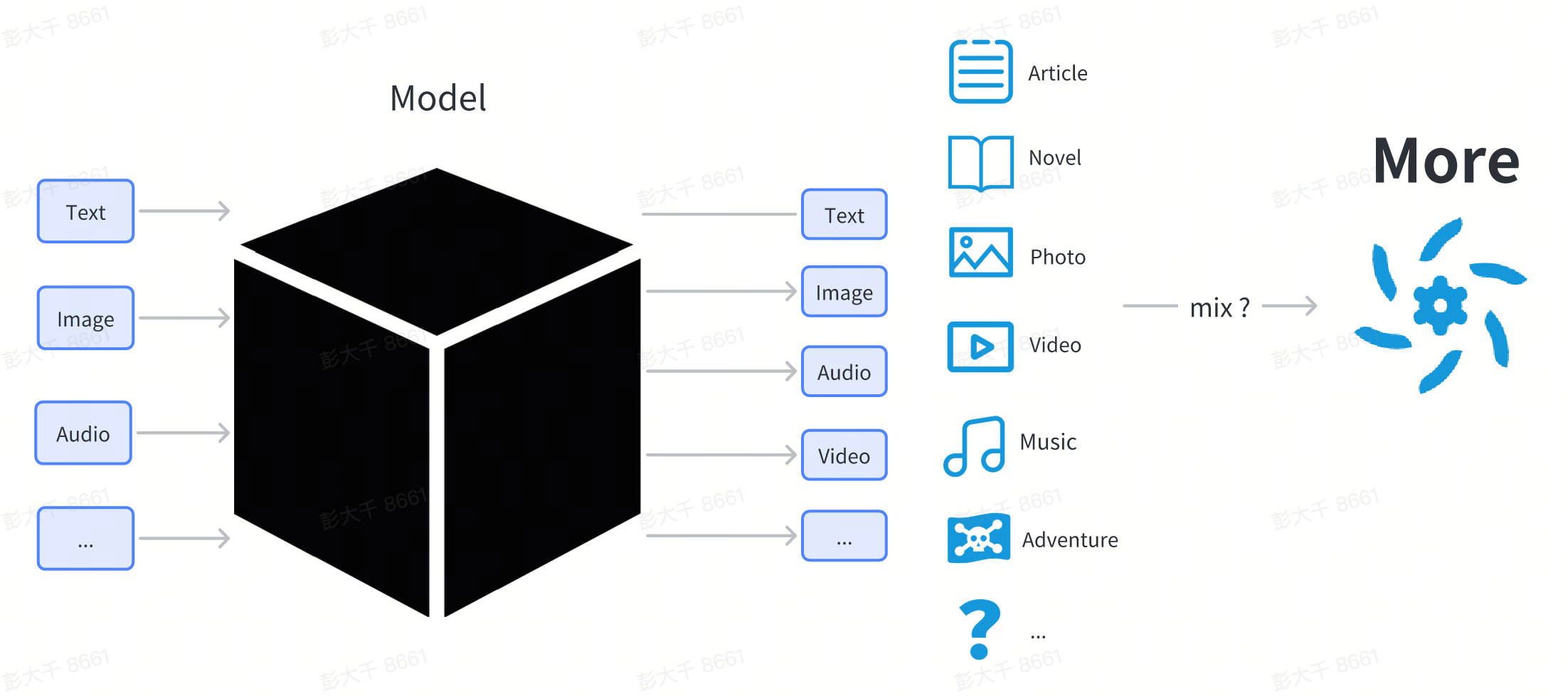
일반 사용자의 관점에서 모델은 인터넷에서 다운로드한 파일입니다. 일반적으로 .pt, .safetensor 또는 .checkpoint로 끝납니다.
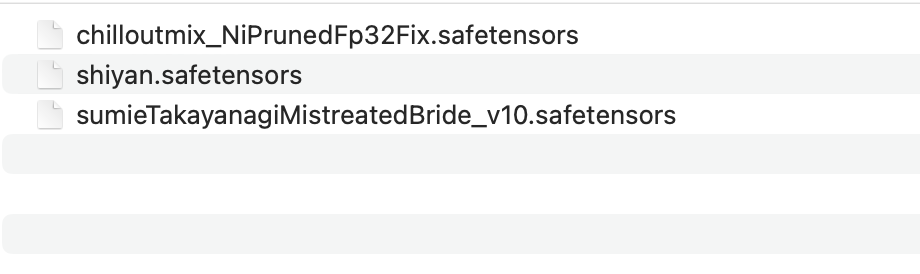
모델은 일반 소프트웨어와 같이 더블 클릭으로 직접 실행할 수 없습니다. 사용하기 전에 다른 소프트웨어에서 로드해야 합니다. 일반적으로 모델을 로드하고 사용하기 위한 워크벤치 소프트웨어가 있습니다. 예를 들어:
- 이미지 생성을 위한 워크벤치: stable-diffusion-webui
- 텍스트 생성을 위한 워크벤치: text-generation-webui
사용자는 다양한 모델을 로컬 컴퓨터에 다운로드한 다음, 워크벤치 소프트웨어에서 지정된 디렉토리에 모델을 놓고 워크벤치를 실행합니다.
워크벤치에서 사용자는 사용할 모델을 지정할 수 있습니다. 소프트웨어는 사용자가 선택한 모델 파일을 로드합니다. 로드한 후에 특정 모델을 사용할 수 있습니다.
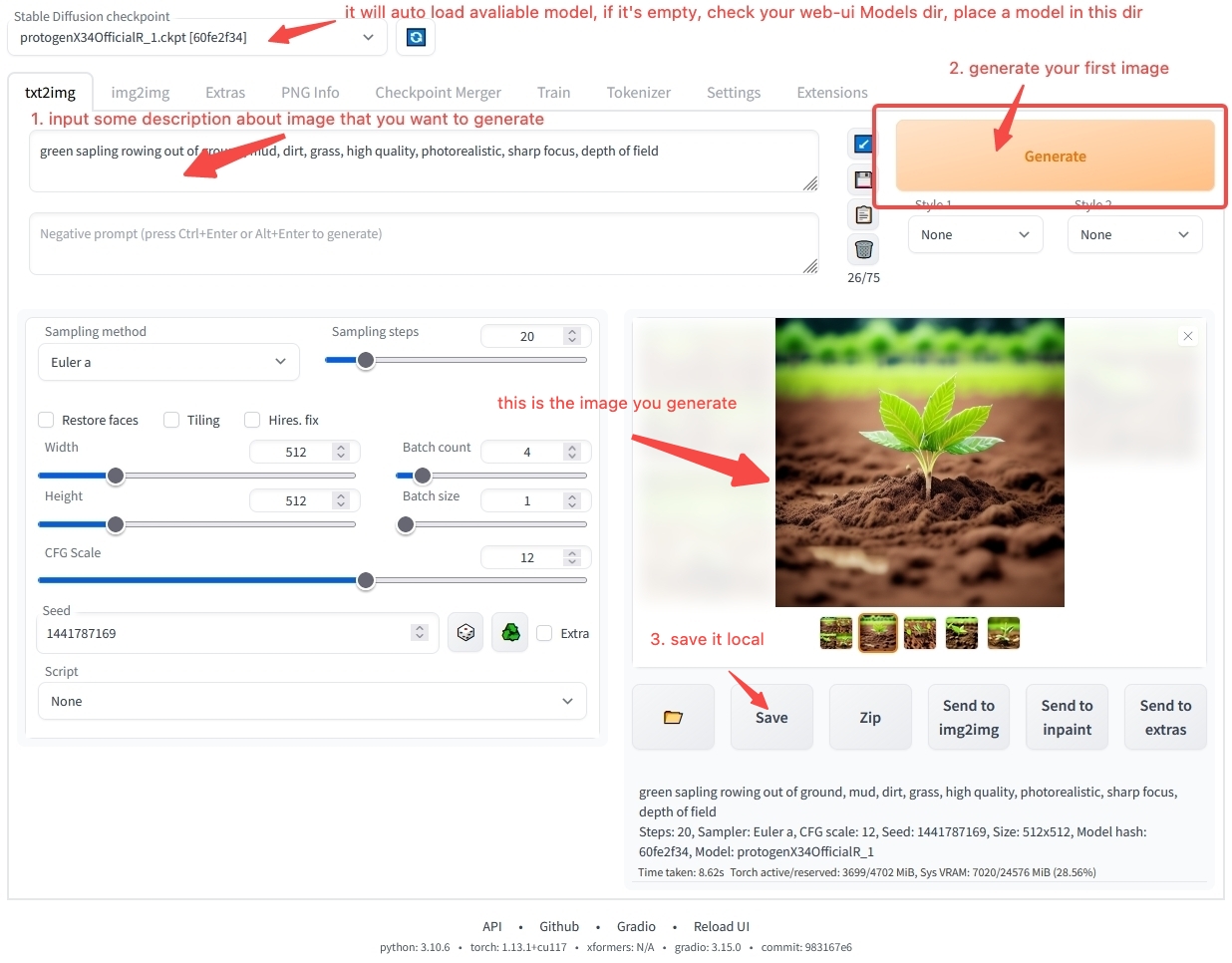
stable-diffusion-webui를 사용하여 첫 번째 이미지를 생성합니다.
아마도 워크벤치 소프트웨어를 사용하는 방법에 대해 여전히 많은 의문이 있을 것입니다. 걱정하지 마세요. 모델 사용 개요 장에서는 소프트웨어를 설치하고 작동하는 방법을 단계별로 안내해 드릴 것입니다. 첫 번째 AI 아트워크를 생성해보고 싶다면, 빠른 시작으로 바로 이동하여 제공하는 온라인 환경을 사용해보세요. 모델 관련 내용을 더 알고 싶다면 계속 읽어보세요.
모델 분류
인터넷에서 Stable Diffusion, ChilloutMix, KoreanDollLikeness 등 다양한 모델 이름을 들어본 적이 있을 것입니다. 왜 이렇게 많은 모델이 있는 걸까요? 그들 간에 차이점은 무엇일까요?
사용자의 관점에서 모델은 기본 모델, 전체 매개변수 미세 조정 모델 및 경량화 미세 조정 모델으로 나눌 수 있습니다.
| 카테고리 | 기능 | 설명 | 예시 |
|---|---|---|---|
| 기본 모델 | 내용 생성에 직접 사용될 수 있습니다. | 일반적으로 연구 기관/기술 회사에서 새로운 네트워크 구조와 함께 모델을 출시합니다. | Stable Diffusion 1.5, Stable Diffusion 2.1 |
| 전체 매개변수 미세 조정 모델 | 내용 생성에 직접 사용될 수 있습니다. | 특정 데이터에 대해 기본 모델을 미세 조정하여 얻은 새로운 모델로, 원래 기본 모델과 같은 구조이지만 매개변수가 다릅니다. | ChilloutMix |
| 경량화 미세 조정 모델 | 내용 생성에 직접 사용될 수 없습니다. | 경량화 미세 조정 방법을 사용하여 모델을 미세 조정합니다. | KoreanDollLikeness, JapaneseDollLikeness |
미세 조정이란 기본 모델을 특정 데이터에 대해 다시 학습하여 미세 조정 모델을 만드는 것으로, 미세 조정 모델은 특정 시나리오에서 원래 기본 모델보다 더 나은 성능을 발휘합니다.
이미지 모델
이미지 모델을 예로 들면, 현재 시장에서 거의 모든 모델은 Stable Diffusion 시리즈 모델에서 파생되었습니다. Stable Diffusion은 stability.ai에서 공개한 오픈 소스 이미지 내용 생성 모델입니다. 2022년 8월부터 현재까지 4개 버전이 출시되었습니다.
- Stable Diffusion
- Stable Diffusion 1.5
- Stable Diffusion 2.0
- Stable Diffusion 2.1
현재 커뮤니티에서 대부분의 파생 모델은 Stable Diffusion 1.5에서 미세 조정한 것입니다.
이미지 생성 분야에서 Stable Diffusion 시리즈 모델은 사실상의 표준 모델이 되었습니다.
텍스트 모델
텍스트 분야에서는 현재 표준이 없습니다. 11월에 ChatGPT가 출시되면서, 일부 연구 기관과 회사에서 자체 미세 조정 모델을 출시했습니다. 각각의 모델은 고유한 특성을 가지고 있습니다. 예를 들어, Meta에서 출시한 LLaMA와 stability.ai에서 출시한 StableLM 등이 있습니다.
현재 텍스트 내용 생성에서 몇 가지 핵심적인 문제가 있습니다.
- 짧은 대화 문맥: 모델과의 대화에서 텍스트가 너무 길면 모델은 이전 내용을 잊어버리게 됩니다. 현재 RWKV만이 모델 구조와 다른 큰 차이로 인해 긴 문맥을 달성할 수 있습니다. 대부분의 텍스트 모델은 트랜스포머 구조를 기반으로 하며 문맥이 짧은 경우가 많습니다.
- 모델이 너무 큼: 모델이 클수록 매개변수가 많아지며 콘텐츠 생성에 필요한 컴퓨팅 리소스가 더 많이 필요합니다.
오디오 모델
오디오 분야에는 몇 가지 특수성이 있는데, 단일 오디오 콘텐츠의 경우 성우 음성, 사운드, 음악의 세 가지 범주로 나눌 수 있습니다.
- Voice: 전통적으로 음성 기술은 예술적 상상력이 부족한 Text To Speech(Text To Speech) TTS 기술을 이용하여 생성하는 것이 일반적입니다.
- 음악: 음악은 상상이 더 많은 분야입니다.이미 16년 전부터 상업 회사에서 AI 모델 생성 음악 서비스를 제공하기 시작했습니다.안정적 확산의 인기에 따라 일부 개발자는 안정적 확산 사용을 제안 Riffusion과 같은 음악을 생성하기 위해 2022년 10월 Google에서 음악 한 곡 후에 계속 쓸 수 있는 AudioLDM을 출시했습니다. 2023년 4월 suno.ai에서 bark 모델을 출시했습니다. 현재 , 음악 분야는 아직 개발 단계에 있으며, 아마도 반년에서 1년 정도의 개발 기간이 지나면 이미지 분야와 마찬가지로 응용의 임계점을 돌파하게 될 것입니다.
- 사운드: 문 두드리는 소리, 파도 소리와 같은 단순한 사운드는 요소가 비교적 단순하기 때문에 비교적 쉽게 생성할 수 있습니다.
비디오 모델
현재 비디오 모델은 아직 개발 초기 단계입니다. 이미지와 비교할 때 비디오는 상황 정보를 가지고 있습니다. 동시에 비디오를 생성하는 데 이미지보다 훨씬 더 많은 리소스가 필요한 경우가 많습니다. 현재 기술이 충분히 성숙하지 않은 경우 컴퓨팅 리소스는 종종 저품질 콘텐츠를 생성하는 데 낭비됩니다. 동시에 현재 일반 사용자를 위한 비교적 성숙한 비디오 생성 소프트웨어가 있으므로 일반 사용자가 스스로 비디오를 생성하려고 시도하는 것을 권장하지 않습니다. 그래도 비디오 생성을 경험하고 싶다면 [ RunwayML](https://runwayml.com/에서 온라인 서비스를 사용해 보세요.)
3D 콘텐츠 모델
현대 3D 게임에서는 많은 수의 3D 모델 리소스가 필요한 경우가 많습니다.또한 3D 프린팅 기술을 사용하여 3D 모델 프린팅을 실제 세계의 물리적 예술 작품으로 전환할 수도 있습니다.
3D 콘텐츠 생성 분야에서 상대적으로 수요가 적고 동시에 현재 3D 콘텐츠에 대한 상대적으로 완전한 패러다임이 없습니다.
참조로 사용할 수 있는 일부 프로젝트는 다음과 같습니다.
현재 3D 콘텐츠 생성 기술은 일부 saas 서비스에서 중요한 적용 지점에 가깝습니다.
기타 모델
기본 콘텐츠를 생성하는 모델 외에도 여러 양식을 통합할 수 있고 여러 양식 콘텐츠를 이해하고 생성할 수 있는 일부 모델이 있으며 현재 이 부분 기술은 개발 단계에 있습니다.
참조로 사용할 수 있는 일부 프로젝트는 다음과 같습니다.