AIGCモデルの概要
AIGC技術の中心は、様々なディープラーニングモデルです。
ディープラーニングモデルは、ネットワーク構造とパラメータから構成される複雑な構造です。
ここでは、モデルの技術的な説明にはあまり触れません。ユーザーにとって、モデルはブラックボックスとして扱うことができます。ユーザーが何かを入力する(例えば、テキスト入力)と、モデルは入力に関連するイメージやテキストなどのコンテンツを出力します。
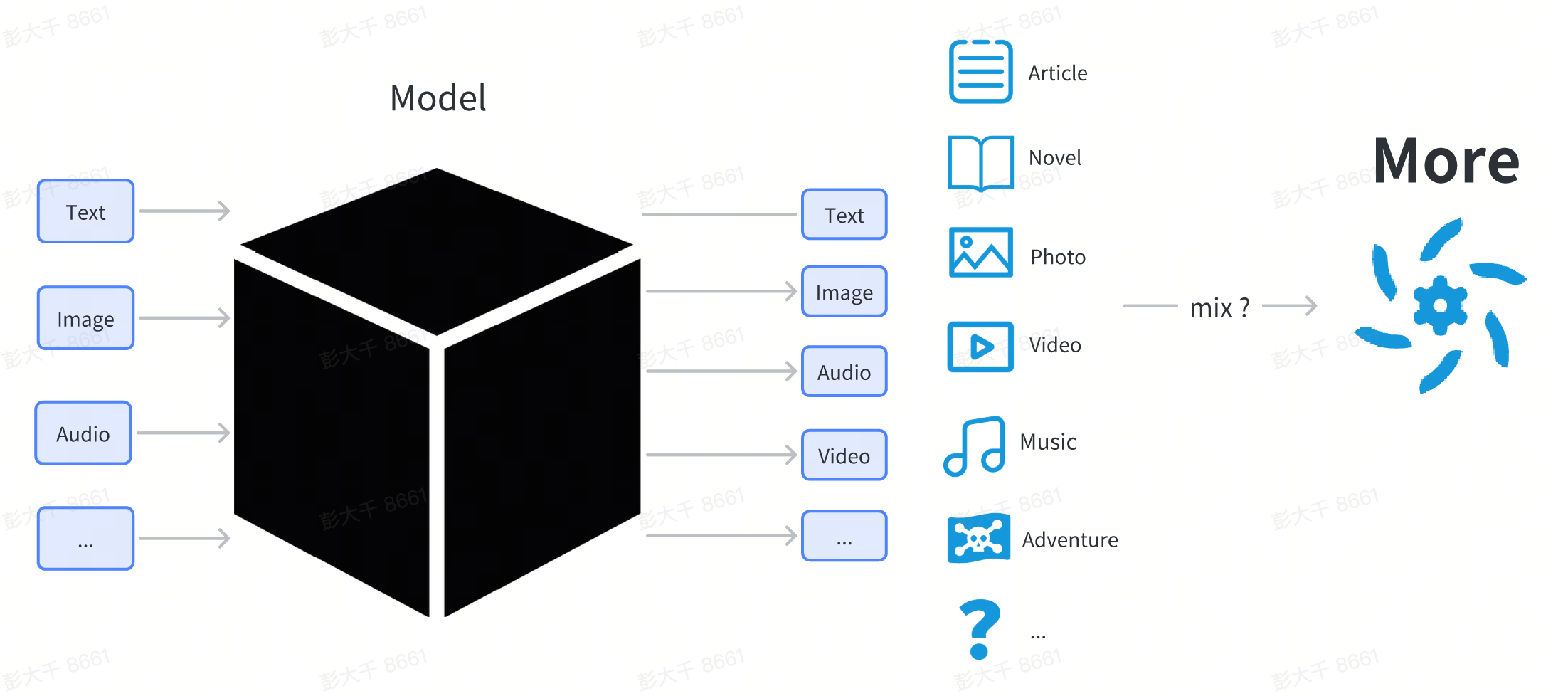
一般ユーザーの視点からは、モデルはインターネットからダウンロードされるファイルであり、通常は.pt、.safetensor、または.checkpointで終わります。
モデルは普通のソフトウェアのようにダブルクリックして直接実行することはできません。他のソフトウェアによってロードされる必要があります。通常、画像生成のためのワークステーションソフトウェアや、テキスト生成のためのテキスト生成ワークステーションソフトウェアなどがあります。
ユーザーは、様々なモデルをローカルコンピュータにダウンロードし、ワークステーションソフトウェアが指定するディレクトリに配置し、ワークステーションを起動します。
ワークステーションでは、ユーザーは特定のモデルを使用するように指定することができます。ソフトウェアは選択されたモデルファイルをロードします。ロード後、特定のモデルを使用できます。
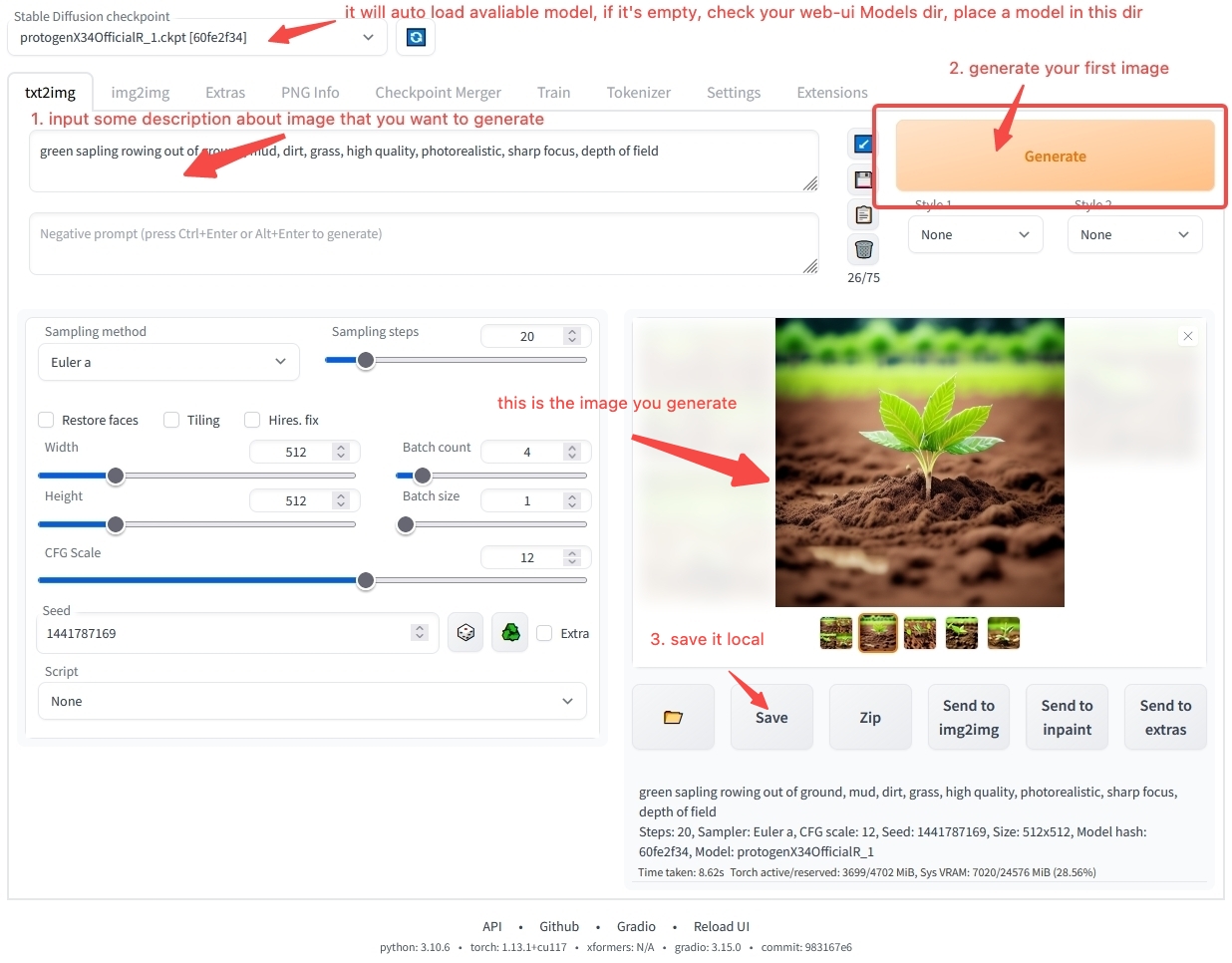
ワークステーションソフトウェアの使用方法については、まだ多くの疑問があるかもしれません。心配しないでください。モデル使用の概要章では、ソフトウェアのインストールと操作の手順をステップバイステップで説明します。最初のAIアートを生成したくて待てない場合は、クイックスタートに直接ジャンプして、オンライン環境で素早く始めることができます。モデル関連のコンテンツについてもっと学びたい場合は、読み進めてください。
モデル分類
インターネット上でStable Diffusion、ChilloutMix、KoreanDollLikenessなどの様々なモデル名を聞いたことがあるかもしれません。なぜそんなに多くのモデルがあるのでしょうか?それらの違いは何でしょうか?
ユーザーの視点から、モデルは基本モデル、全パラメータ微調整モデル、軽量微調整モデルに分けることができます。
| カテゴリ | 機能 | 紹介 | 例 |
|---|---|---|---|
| 基本モデル | コンテンツ生成に直接使用できる | 研究機関/技術企業によってリリースされた新しいネットワーク構造を持つモデル | Stable Diffusion 1.5、Stable Diffusion 2.1 |
| 全パラメータ微調整モデル | コンテンツ生成に直接使用できる | 特定のデータで基本モデルを微調整して得られた新しいモデルで、元の基本モデルと同じ構造を持ち、異なるパラメータを持つ | ChilloutMix |
| 軽量微調整モデル | コンテンツ生成に直接使用できない | 軽量微調整方法を使用して微調整されたモデル | KoreanDollLikeness、JapaneseDollLikeness |
微調整とは、基本モデルを特定のデータで再トレーニングして微調整モデルを得ることを指します。微調整モデルは、特定のシナリオで元の基本モデルよりも優れたパフォーマンスを発揮します。
画像モデル
画像コンテンツモデルを例にとると、現在市場にあるほとんどのモデルはStable Diffusionシリーズのモデルから派生しています。Stable Diffusionは、stability.aiがリリースしたオープンソースの画像コンテンツ生成モデルです。2022年8月から現在まで、4つのバージョンがリリースされています。
- Stable Diffusion
- Stable Diffusion 1.5
- Stable Diffusion 2.0
- Stable Diffusion 2.1
現在、コミュニティで主流の派生モデルのほとんどは、Stable Diffusion 1.5を微調整したものです。
画像生成の分野では、Stable Diffusionシリーズのモデルが事実上の標準となっています。
テキストモデル
テキストの分野では、現在統一された標準はありません。11月にChatGPTがリリースされたことで、いくつかの研究機関や企業が独自の微調整モデルをリリースし、それぞれ特徴を持っています。その中でも、より有名なものには、MetaがリリースしたLLaMAや、stability.aiがリリースしたStableLMなどがあります。
現在、テキストコンテンツ生成にはいくつかの核心的な問題があります。
- 短い対話コンテキストの長さ。対話のためのテキストが長すぎると、モデルは前のコンテンツを忘れてしまいます。現在、RWKVだけが、他のモデルとのモデル構造の大きな違いにより、長いコンテキストを実現できます。ほとんどのテキストモデルは現在、トランスフォーマー構造に基づいており、コンテキストはしばしば短いです。
- モデルが大きすぎる。モデルが大きくなるほど、パラメータが多くなり、コンテンツ生成に必要なコンピューティングリソースが増えます。
オーディオモデル
オーディオの分野にはいくつかの特徴があり、ひとつのオーディオコンテンツは声優の声、サウンド、音楽の3つのカテゴリに分類できます。
- 音声: 伝統的に言えば、音声テクノロジーは通常 Text To Speech (Text To Speech) TTS テクノロジーを使用して生成されますが、芸術的な想像力が欠けています データ→モデル、モデル→コンテンツのパラダイム
- 音楽: 音楽はより想像力豊かな分野です。16 年前には、営利企業が AI モデル生成の音楽サービスを提供し始めました。安定拡散の人気に伴い、一部の開発者は 安定拡散の使用を提案しました Riffusionなどの音楽を生成するために使用されますが、現在の効果は十分に驚くべきものではありません 2022年10月にGoogleは音楽の後に書き込みを続けることができるAudioLDMをリリースしました 2023年4月にはsuno.aiがbarkモデルをリリースしました, 音楽分野はまだ発展途上ですが、おそらく半年から1年くらい開発すれば映像分野と同様に応用の臨界点を突破するでしょう。
- サウンド: ドアをノックする音や海の波などの単純な音は、要素が比較的単純であるため、比較的簡単に生成できます。既存の AudioLDM と鳴き声は、単純な音を生成できます。
ビデオモデル
現在のビデオ モデルはまだ開発の初期段階にあります。画像と比較して、ビデオにはコンテキスト情報があります。同時に、ビデオの生成には画像よりもはるかに多くのリソースが必要になることがよくあります。現在のテクノロジが十分に成熟していない場合、コンピューティング リソースが不足することがよくあります。低品質のコンテンツを生成するために無駄になりました。 同時に、現在、一般ユーザー向けの比較的成熟したビデオ生成ソフトウェアがあるため、一般ユーザー が自分でビデオを生成することはお勧めしません。それでもビデオ生成を体験したい場合は、RunwayML が提供するオンライン サービスを使用して試すことができます。
3D コンテンツ モデル
最近の 3D ゲームでは、多くの場合、大量の 3D モデル リソースが必要になります。さらに、3D プリント技術を使用して、3D モデルのプリントを現実世界の物理的なアートワークに変えることもできます。
3D コンテンツ生成の分野では、需要が比較的小さいと同時に、現在 3D コンテンツの比較的完全なパラダイムが存在しません。
参考として使用できるプロジェクトには次のようなものがあります。
現在、3D コンテンツ生成テクノロジーは、一部の Saas サービスでの適用の臨界点に近づいています。
その他のモデル
基本的なコンテンツを生成するモデルに加えて、複数のモダリティを統合し、複数のモーダル コンテンツを理解して生成できるモデルがいくつかあります。現在、この部分のテクノロジーは開発段階にあります。
参考として使用できるプロジェクトには次のようなものがあります。