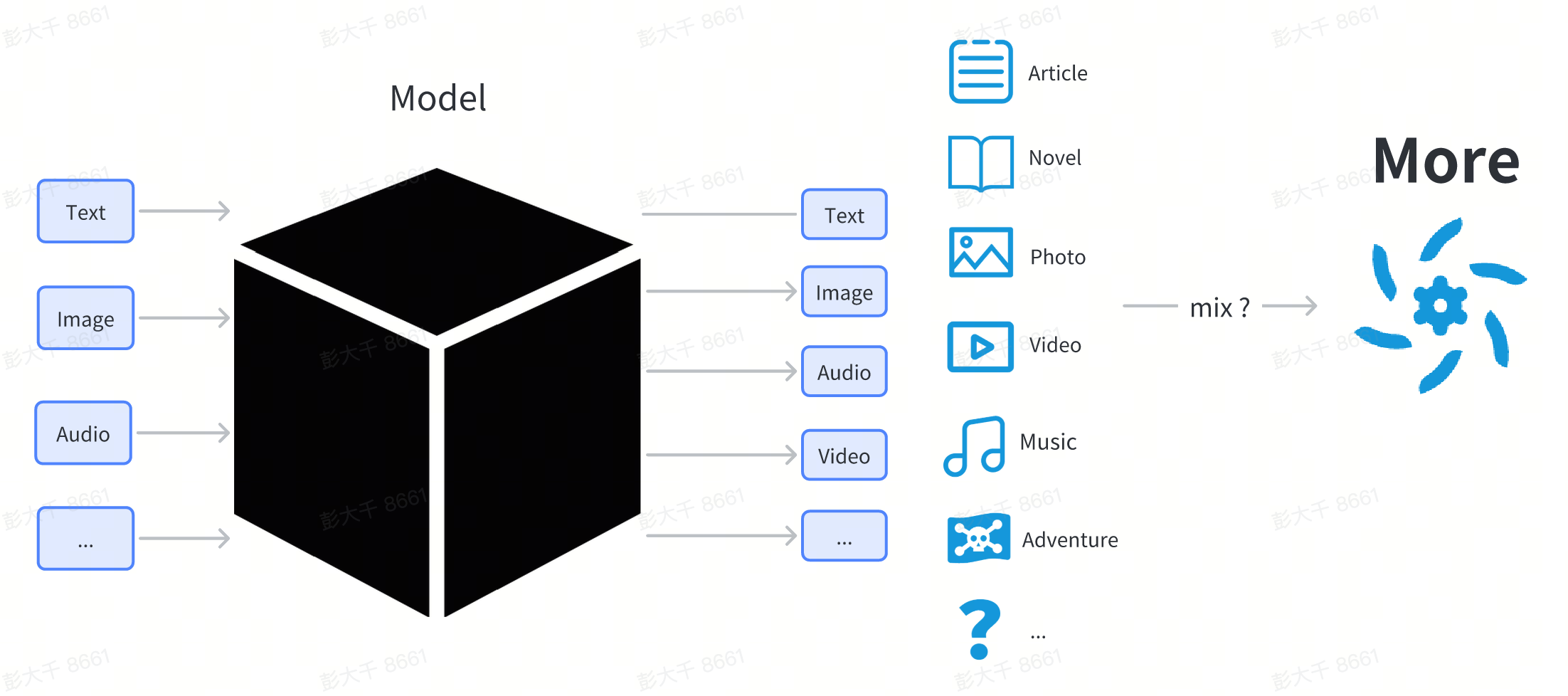
Resumen de los modelos de AIGC
El núcleo de la tecnología AIGC son varios modelos de aprendizaje profundo.
Un modelo de aprendizaje profundo es una estructura compleja compuesta por una estructura de red y parámetros.
En este capítulo, no profundizaremos en los principios técnicos del modelo. Para los usuarios, el modelo puede tratarse como una caja negra. Los usuarios ingresan algo (como texto) y el modelo produce contenido en alguna forma (como imágenes o texto) relacionado con la entrada.
Desde la perspectiva de un usuario común, el modelo es un archivo descargado de Internet, que generalmente termina en .pt, .safetensor o .checkpoint.
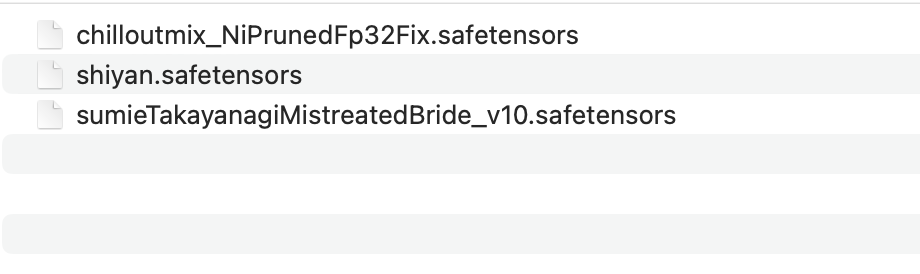
El modelo no se puede ejecutar directamente haciendo doble clic como el software ordinario. Necesita ser cargado por otro software antes de poder ser utilizado. Por lo general, tenemos un software de banco de trabajo para cargar y utilizar modelos, como:
- Banco de trabajo para generación de imágenes: stable-diffusion-webui
- Banco de trabajo para generación de texto: text-generation-webui
Los usuarios descargan varios modelos en su computadora local, los colocan en el directorio especificado por el software de banco de trabajo y luego inician el banco de trabajo.
En el banco de trabajo, los usuarios pueden especificar qué modelo usar. El software cargará el archivo de modelo seleccionado por el usuario. Después de la carga, se puede utilizar un modelo específico.
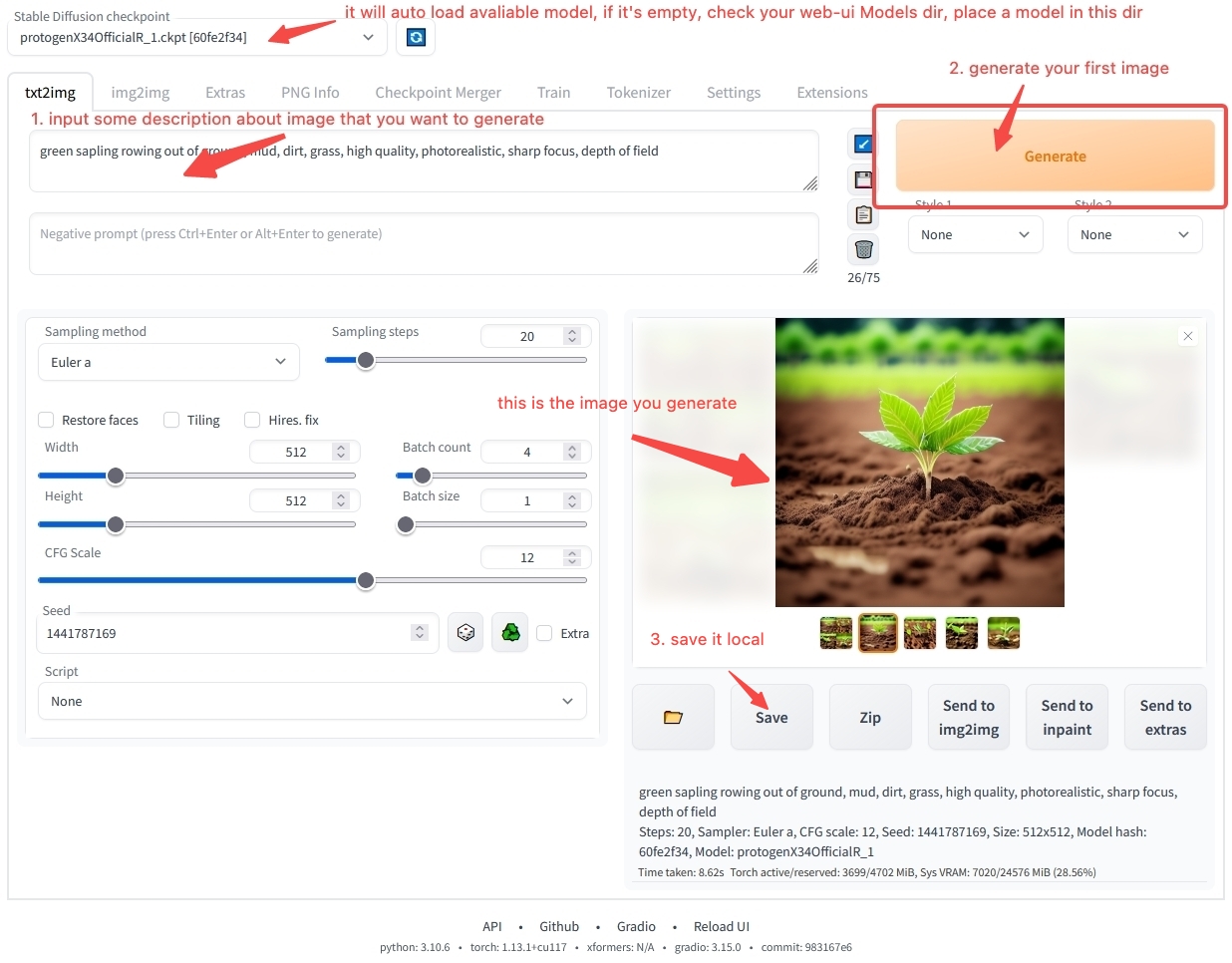
use stable-diffusion-webui generate your first image
Todavía puede tener muchas dudas sobre cómo utilizar el software de banco de trabajo. No se preocupe. En el capítulo Resumen del uso del modelo, lo guiaremos paso a paso sobre cómo instalar y operar el software. Si no puede esperar para generar su primera obra de arte de IA, puede saltar directamente al Inicio rápido y utilizar el entorno en línea que proporcionamos para comenzar rápidamente. Si aún desea aprender más sobre el contenido relacionado con el modelo, sigamos adelante.
Clasificación de modelos
Es posible que haya escuchado varios nombres de modelos como Stable Diffusion, ChilloutMix y KoreanDollLikeness en Internet. ¿Por qué hay tantos modelos? ¿Cuáles son sus diferencias?
Desde la perspectiva del usuario, los modelos se pueden dividir en modelos básicos, modelos de ajuste fino de parámetros completos y modelos de ajuste fino ligero.
| Categoría | Función | Descripción | Ejemplo |
|---|---|---|---|
| Modelos básicos | Se pueden usar directamente para la generación de contenido | Por lo general, las instituciones de investigación / empresas de tecnología lanzan un modelo con una nueva estructura de red | Stable Diffusion 1.5, Stable Diffusion 2.1 |
| Modelos de ajuste fino de parámetros completos | Se pueden usar directamente para la generación de contenido | Un nuevo modelo obtenido mediante el ajuste fino del modelo básico en datos específicos, con la misma estructura que el modelo básico original pero con parámetros diferentes | ChilloutMix |
| Modelos de ajuste fino ligero | No se pueden usar directamente para la generación de contenido | El modelo se ajusta utilizando métodos de ajuste fino ligero | KoreanDollLikeness, JapaneseDollLikeness |
El ajuste fino se refiere a la reentrenamiento del modelo básico en datos específicos, de modo que el modelo ajustado fino funciona mejor que el modelo básico original en escenarios específicos.
Modelos de imagen
Tomando los modelos de imagen como ejemplo, casi todos los modelos en el mercado se derivan de la serie de modelos Stable Diffusion. Stable Diffusion es un modelo de generación de contenido de imagen de código abierto lanzado por stability.ai. Desde agosto de 2022 hasta ahora, se han lanzado cuatro versiones.
- Stable Diffusion
- Stable Diffusion 1.5
- Stable Diffusion 2.0
- Stable Diffusion 2.1
Actualmente, la mayoría de los modelos derivados principales en la comunidad se basan en Stable Diffusion 1.5 para el ajuste fino.
En el campo de la generación de imágenes, los modelos de la serie Stable Diffusion se han convertido en el estándar de facto.
Modelos de texto
En el campo del texto, actualmente no hay un estándar unificado. Con el lanzamiento de ChatGPT en noviembre, algunas instituciones de investigación y empresas han lanzado sus propios modelos ajustados finos, cada uno con sus propias características, incluido LLaMA lanzado por Meta y StableLM lanzado por stability.ai.
Actualmente, hay varios problemas centrales en la generación de contenido de texto:
- Contexto de conversación corto: Si el texto en la conversación con el modelo es demasiado largo, el modelo olvidará el contenido anterior. Actualmente, solo RWKV puede lograr un contexto largo debido a las diferencias significativas en la estructura del modelo en comparación con otros modelos. La mayoría de los modelos de texto se basan en estructuras de transformador, y el contexto suele ser corto.
- Los modelos son demasiado grandes: Cuanto más grande es el modelo, más parámetros tiene y más recursos informáticos se requieren para la generación de contenido.
Modelos de audio
En el campo de audio, existen algunas características especiales. Para un solo contenido de audio, se puede dividir en tres categorías: discurso de actor de voz, sonido y música.
- Discurso: Tradicionalmente, la tecnología del habla suele utilizar la tecnología Text To Speech (TTS) para generar habla, lo que carece de imaginación artística. Actualmente, pocas personas prestan atención a esto y no existe una herramienta de código abierto madura para el paradigma de datos → modelo o modelo → contenido.
- Música: La música es un campo más imaginativo. Desde 2016, las empresas comerciales comenzaron a proporcionar modelos de IA para generar música. Con la popularidad de Stable Diffusion, algunos desarrolladores han propuesto utilizar Stable Diffusion para generar música, como Riffusion. Sin embargo, el efecto no es lo suficientemente sorprendente. En octubre de 2022, Google lanzó AudioLDM, que puede seguir escribiendo después de un fragmento de música. En abril de 2023, suno.ai lanzó el modelo de ladrido. Actualmente, el campo de la música todavía está en la etapa de desarrollo. Quizás después de medio año a un año de desarrollo, también romperá el punto crítico de aplicación como el campo de la imagen.
- Sonido: El sonido puro, como golpear la puerta, las olas del mar, es relativamente simple de generar porque los elementos son relativamente simples. Los existentes AudioLDM y ladrido pueden generar sonidos simples.
Modelos de video
Actualmente, los modelos de video todavía están en las primeras etapas de desarrollo. En comparación con las imágenes, los videos tienen información contextual y la generación de videos a menudo requiere más recursos que la generación de imágenes. Cuando la tecnología no es lo suficientemente madura, a menudo se desperdician recursos informáticos para generar contenido de baja calidad. Al mismo tiempo, actualmente no hay software de generación de video maduro para usuarios comunes. Por lo tanto, no recomendamos que los usuarios comunes intenten generar videos por sí mismos. Si aún desea experimentar la generación de videos, puede utilizar el servicio en línea proporcionado por RunwayML para probarlo.
Modelos de contenido 3D
En los juegos 3D modernos, a menudo se requieren una gran cantidad de recursos de modelos 3D. Además, podemos utilizar la tecnología de impresión 3D para convertir modelos 3D en obras de arte físicas del mundo real.
En el campo de la generación de contenido 3D, la demanda es relativamente pequeña y actualmente no hay un paradigma completo. Algunos proyectos que se pueden utilizar como referencia incluyen:
Actualmente, la tecnología de generación de contenido 3D está cerca del punto crítico de aplicación en algunos servicios saas.
Otros modelos
Además de los modelos que generan contenido básico, también hay modelos que pueden integrar múltiples modalidades y pueden comprender y generar contenido modal múltiple. Actualmente, esta parte de la tecnología está en la etapa de desarrollo.
Algunos proyectos que se pueden utilizar como referencia incluyen: