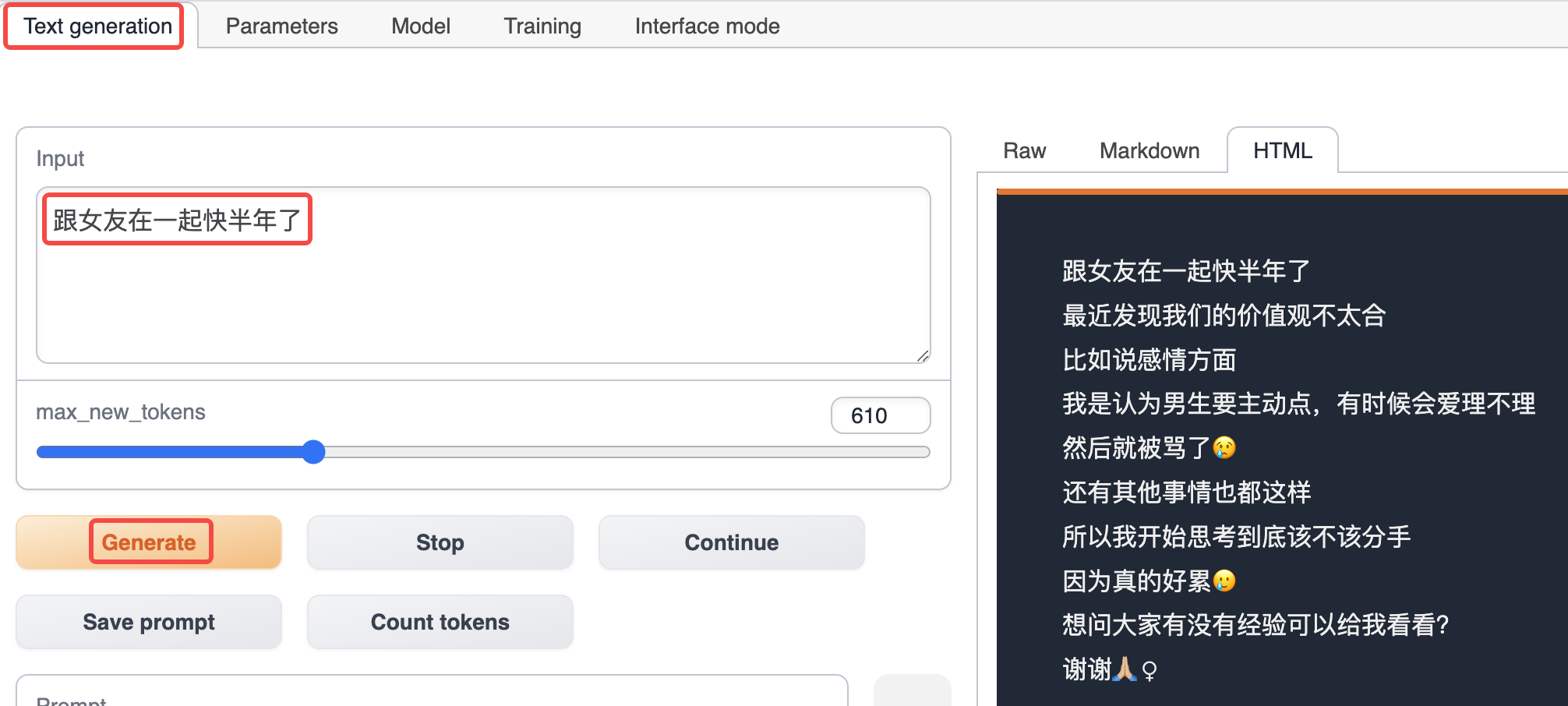
Dcard 감정 Fine-tuning (중국어)
온라인 체험
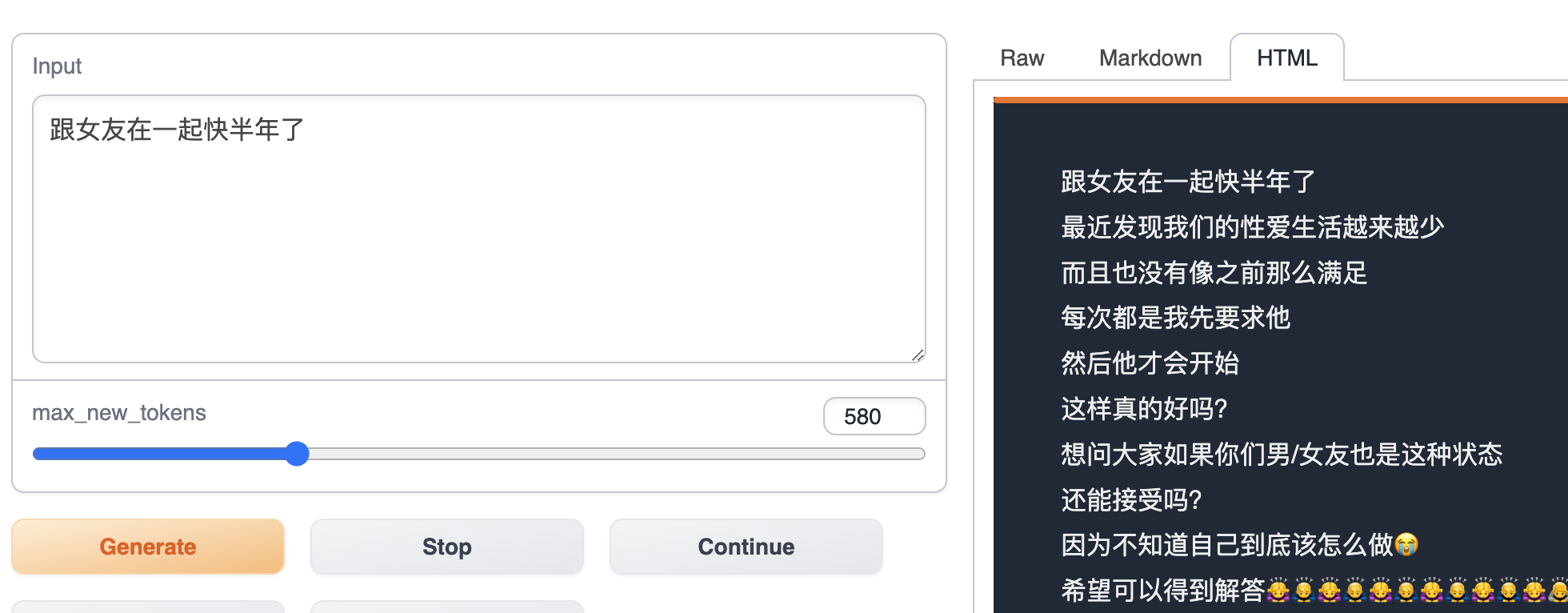
결과
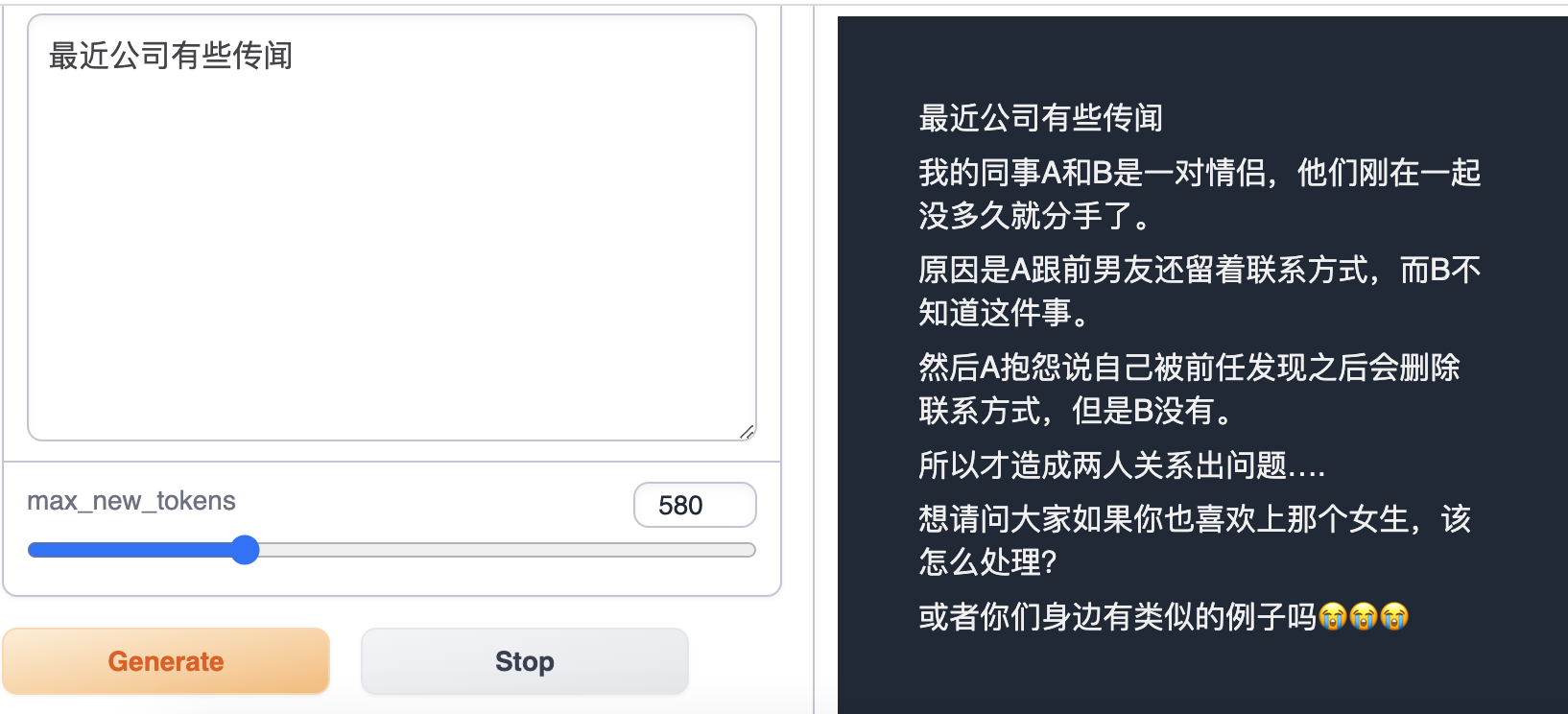
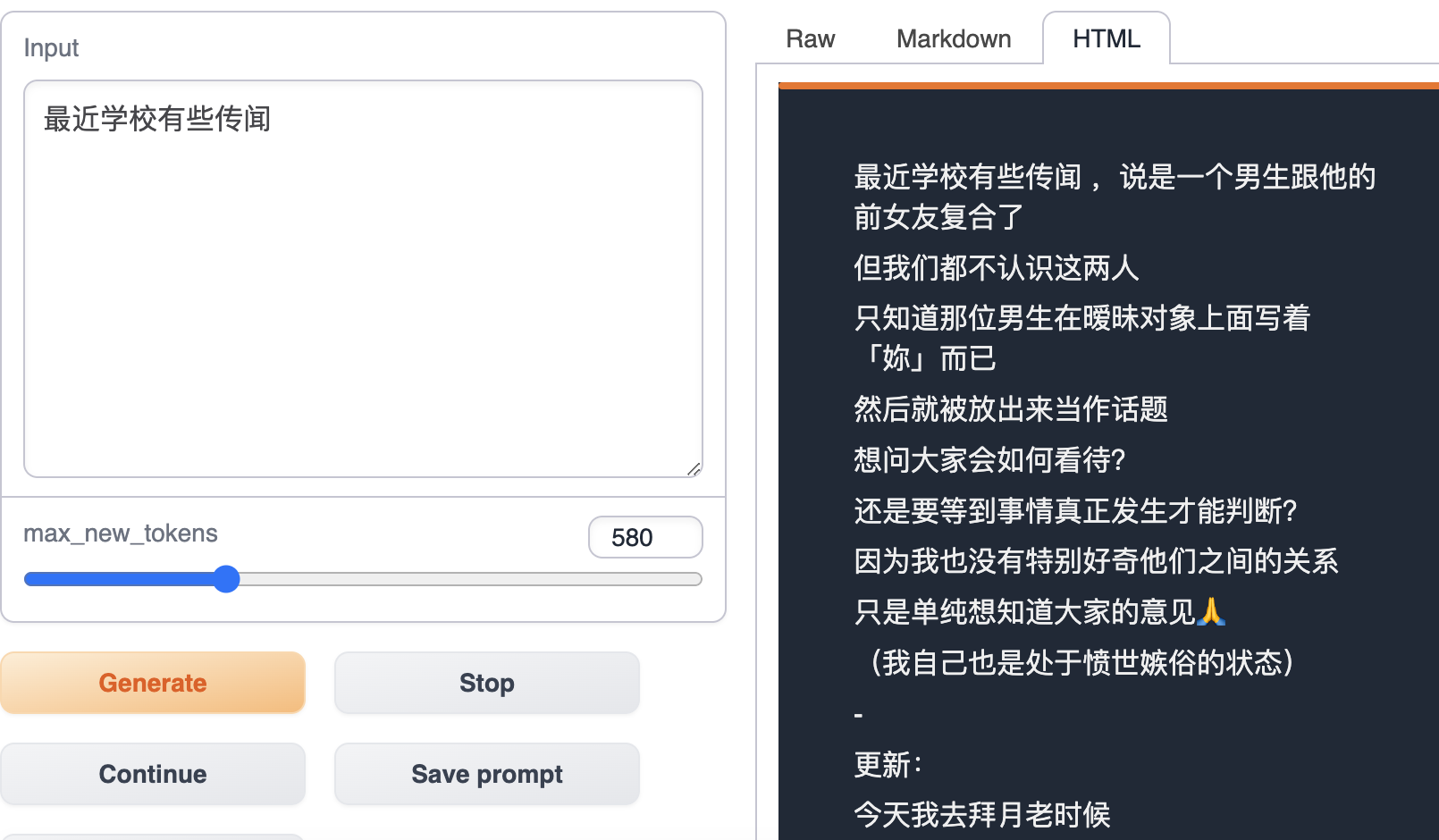
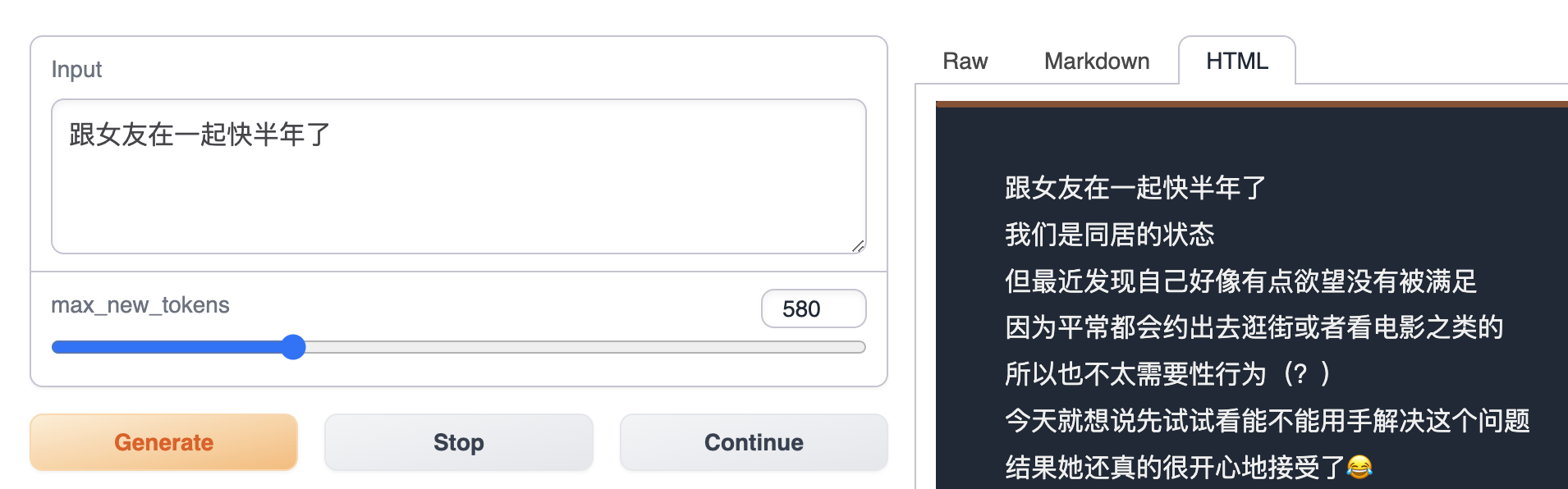
데이터 설명
Dcard는 대만의 커뮤니티 포럼으로 게시물을 주제 섹션으로 구성합니다. 이 프로젝트는 Dcard의 감정 섹션에서 게시물을 수집하고 이 데이터를 사용하여 LLaMA에서 모델을 fine-tuning하였습니다.
간단한 소개
이 프로젝트는 Dcard의 감정 섹션에서 텍스트 데이터를 수집하고 일반 텍스트로 변환한 다음 P01son/Linly-Chinese-LLaMA-7b-hf 모델을 fine-tuning했습니다.
튜토리얼
모델 Fine-tuning
text-generation-webui 설치
text-generation-webui 설치 가이드를 따라 설치합니다.
text-generation-webui를 실행하고 상단 옵션에서 Model 탭을 선택합니다.
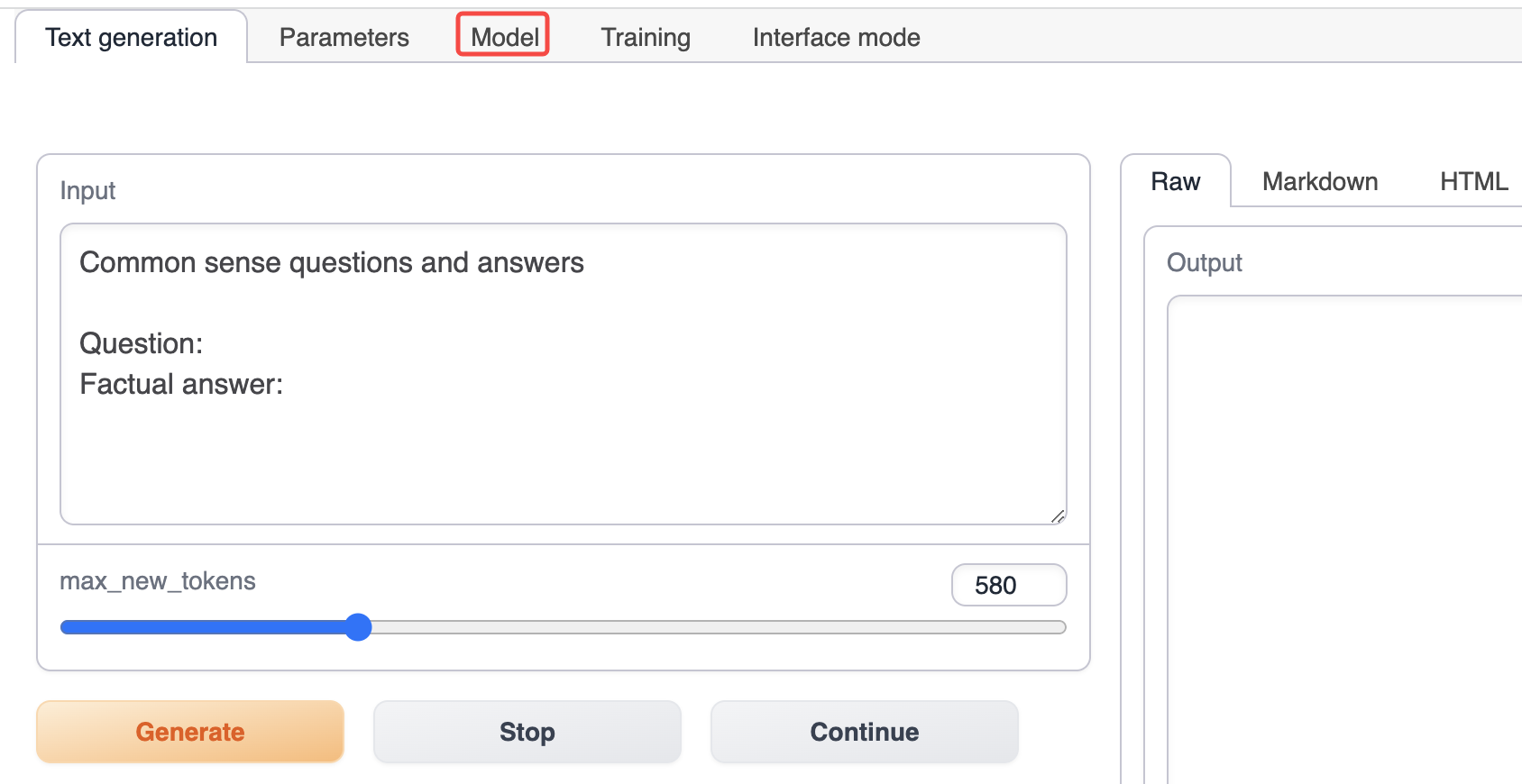
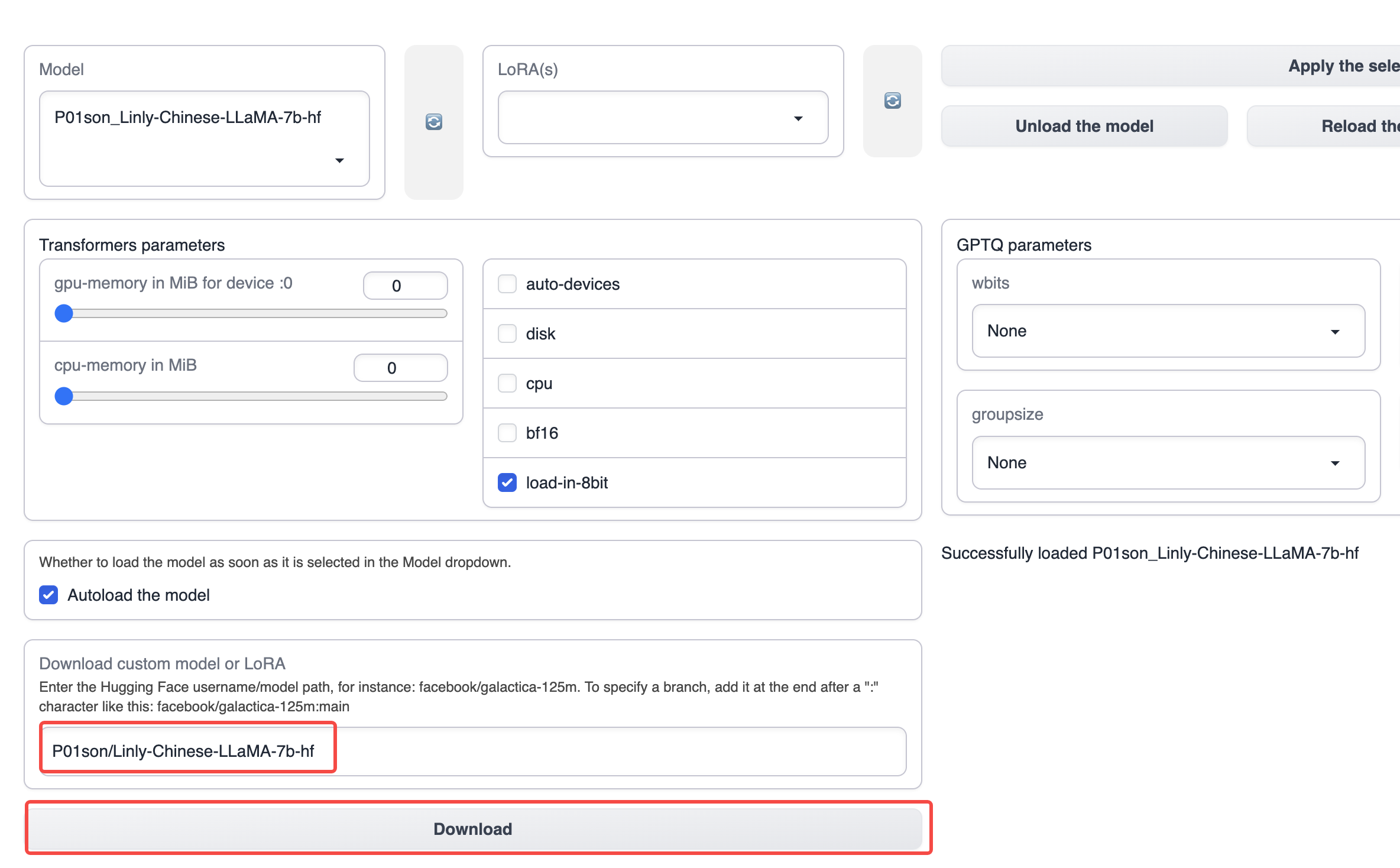
Model 탭에서 P01son/Linly-Chinese-LLaMA-7b-hf를 입력한 다음 다운로드를 클릭하여 기본 모델을 다운로드합니다 (모델을 수동으로 다운로드하고 text-generation-webui 설치의 models 디렉토리에 놓을 수도 있습니다).
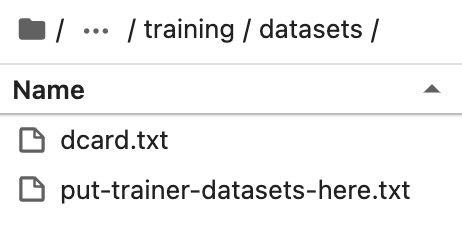
준비된 dcard 데이터셋을 다운로드하고 text-generation-webui 설치의 training/datasets 디렉토리에 넣습니다.
text-generation-webui에서 training 탭으로 전환합니다.
dcard 데이터셋을 선택합니다.
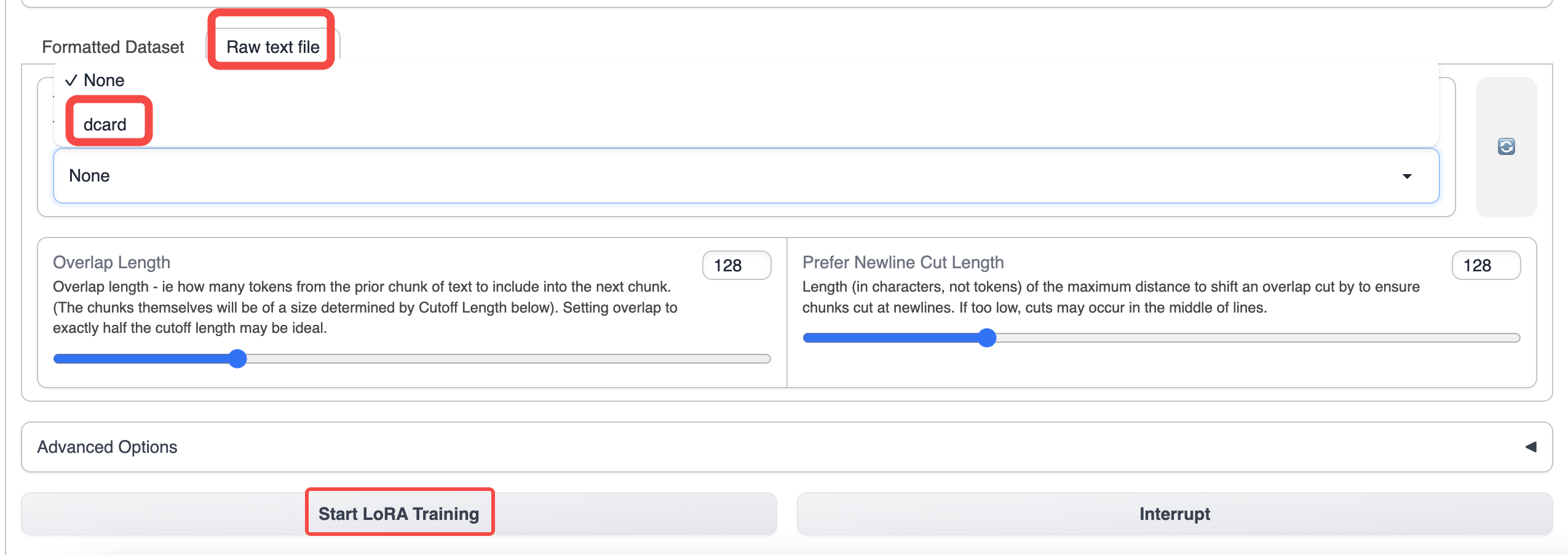
Raw text file 옵션으로 전환하고 dcard 데이터셋을 선택합니다.
훈련 시작
훈련에 대한 기본 매개변수를 사용합니다. 문맥 길이를 늘리려면 cutoff 매개변수를 늘릴 수 있습니다.
Start LoRA Training을 클릭하여 훈련을 시작합니다.
text-generation-webui에서 훈련 진행 상황을 확인할 수 있습니다.
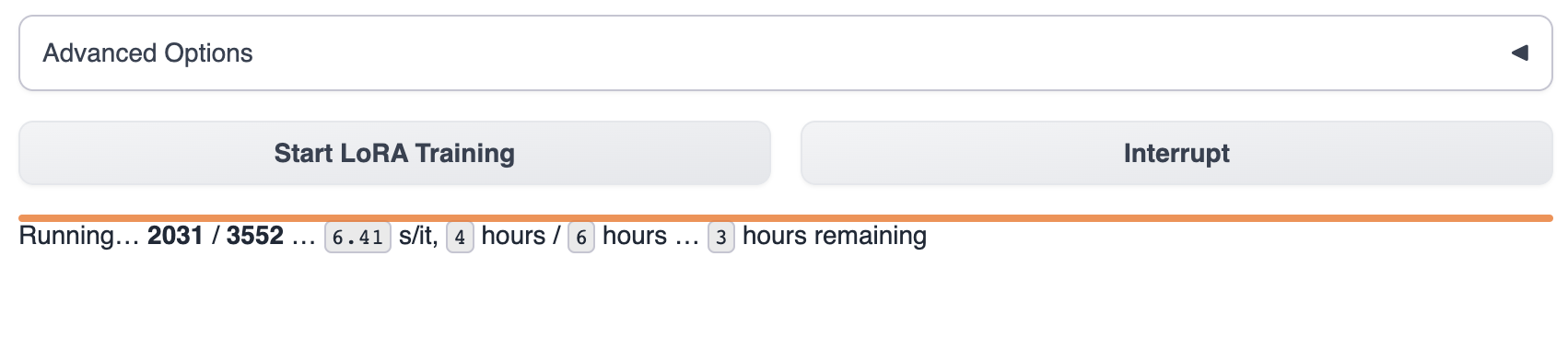
모델이 훈련을 완료할 때까지 기다립니다. 이 작업은 보통 1-8시간이 소요됩니다.
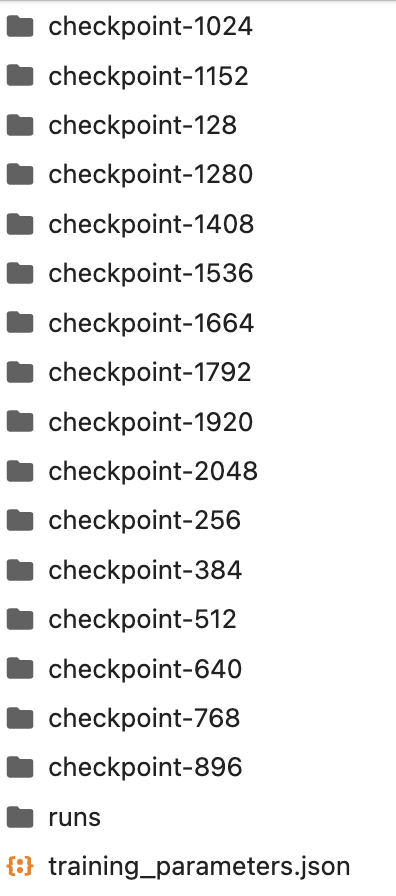
훈련 프로세스의 출력은 lora 디렉토리에 저장됩니다. 훈련 프로세스를 중단하고 lora 디렉토리의 기존 체크포인트 모델을 사용할 수도 있습니다.
모델 사용
lora 디렉토리에 dcard_m이라는 폴더를 수동으로 만듭니다.
최신 체크포인트 모델을 폴더에서 lora 디렉토리로 복사합니다.
Fine-tuned 모델 사용
Model 탭으로 전환하고 먼저 모델을 선택합니다.
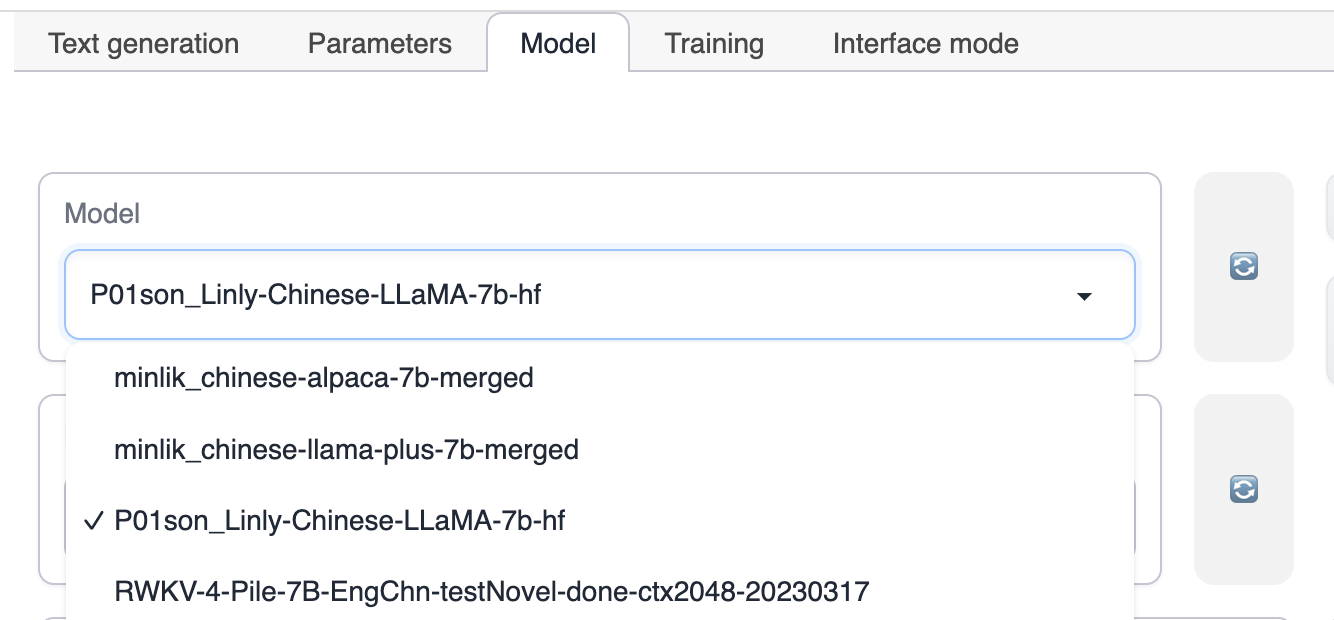
LoRA를 선택합니다. LoRA가 나타나지 않으면 오른쪽의 새로고침 버튼을 클릭하거나 text-generation-webui의 LoRA 디렉토리에 LoRA 모델이 있는지 확인합니다.
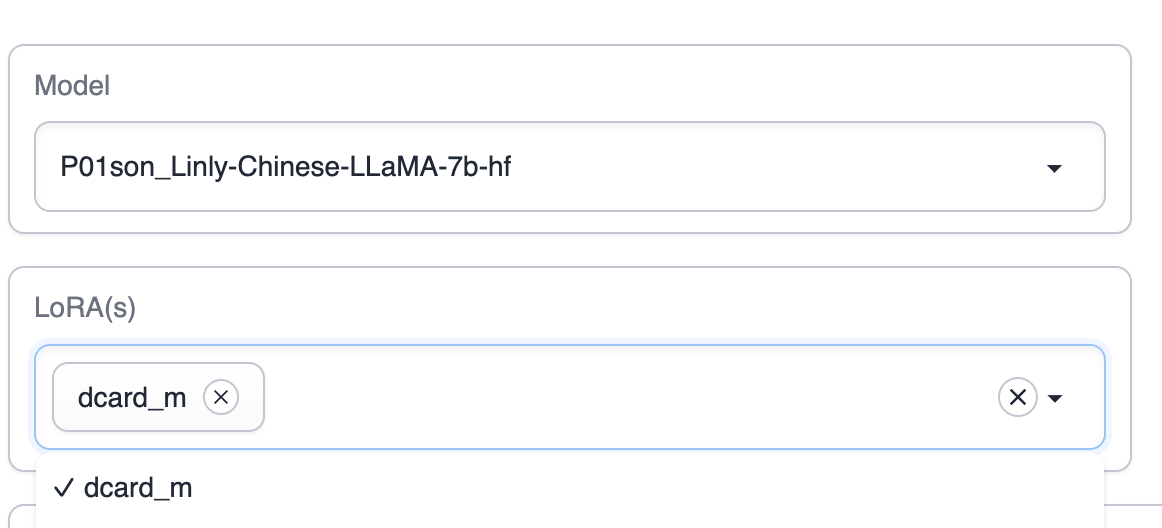
Apply the selected LoRAs를 클릭하여 LoRA를 적용합니다.

적용이 성공하면 메시지가 표시됩니다.
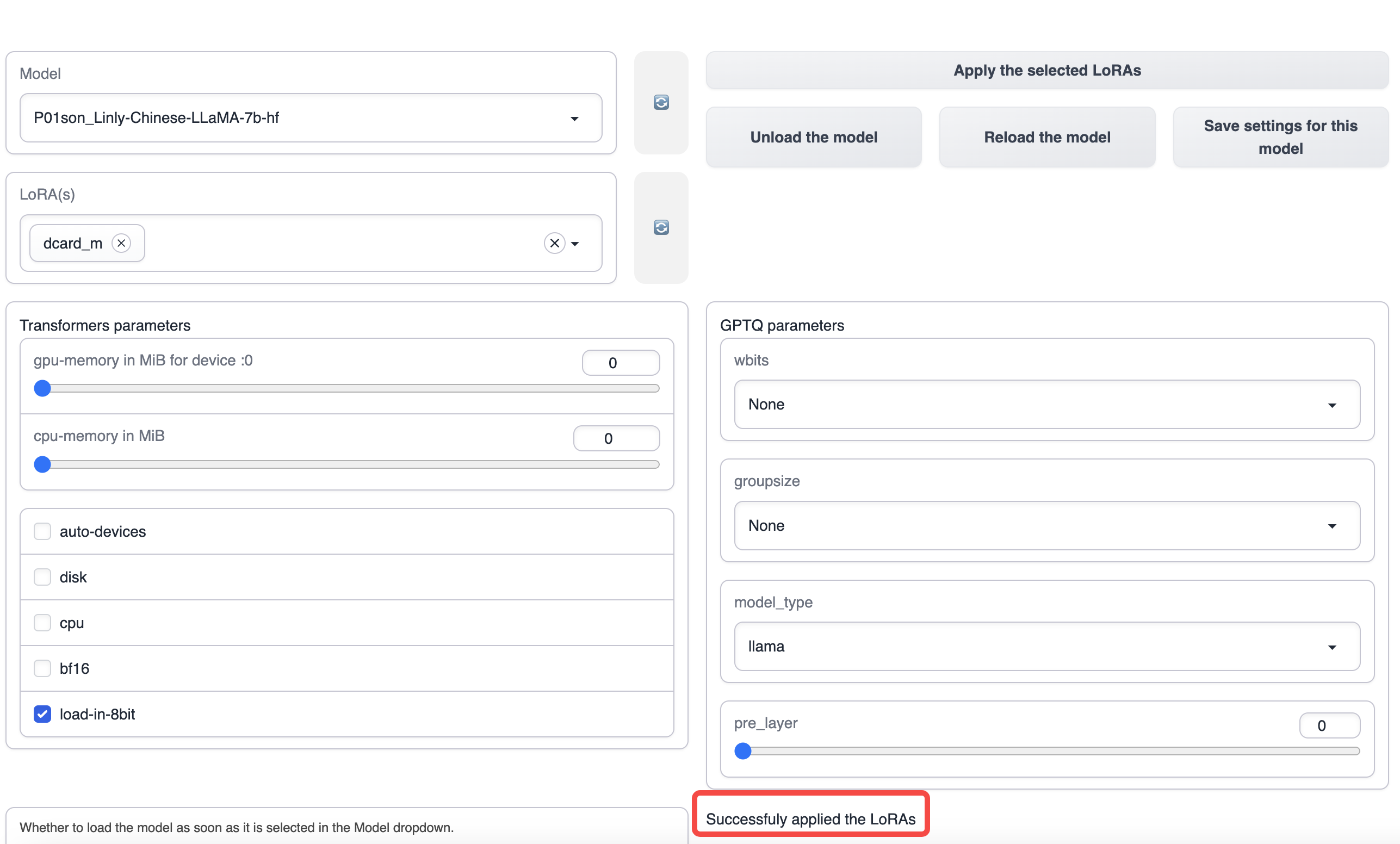
모델 사용
Text generation 탭으로 전환하고 이야기의 시작을 입력한 다음 Generate를 클릭하여 오른쪽에 자동으로 이야기의 나머지 부분을 생성합니다.